
機器學習-11:MachineLN之過擬合
你要的答案或許都在這裡:小鵬的部落格目錄
我想說:
其實很多時候大家都想自己做一些事情,但是很多也都是想想而已,其實有了想法自己感覺可行,就可以去行動起來,去嘗試,即使最後敗了,也無怨無悔,有句話說的很好:成功收穫成果,失敗收穫智慧,投入收穫快樂!反而有時候顧及的太多,本應該做的事情錯過了,怪誰呢?我跟大家不同的是無論什麼事情,先做了再說吧!
說起過擬合,那麼我的問題是:
(1)什麼是過擬合?
(2)為什麼要解決過擬合問題?
(3)解決過擬合有哪些方法?
1. 什麼是過擬合?
不同的人提到過擬合時會有不同的含義:
(1) 看最終的loss,訓練集的loss比驗證集的loss小的多;
(2)訓練的loss還在降,而驗證集的loss已經開始升了;
(3)另外要提一下本人更注重loss,你過你看的是準確率,那麼也OK,適合自己的才是最好的,正所謂學習再多tricks,不如踩一遍坑;
-
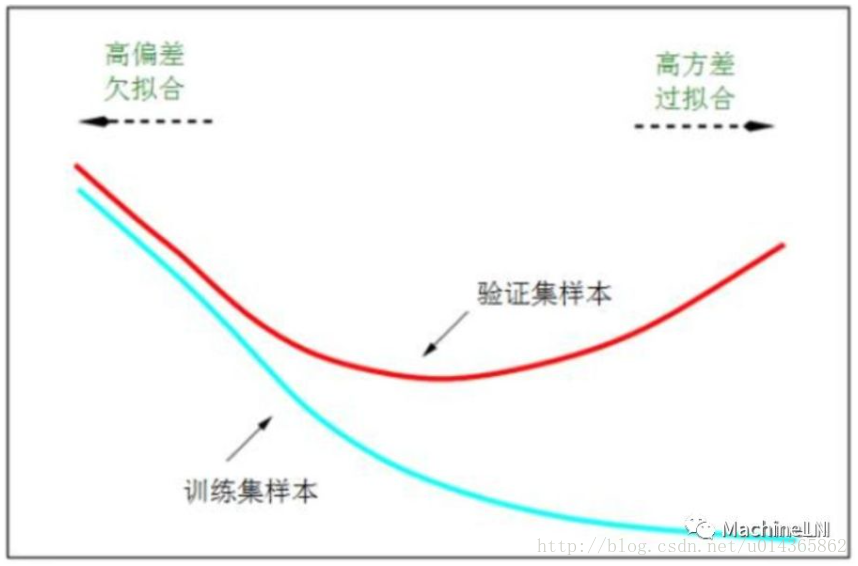
在第一種(1)中驗證集的loss還在降,是不用太在意的。(2)中的overfitting如下圖,在任何情況下都是不行滴!
-
和過擬合相對應的是欠擬合,如下圖剛開始的時候;可以參考MachineLN之模型評估。
2. 為什麼要解決過擬合問題?
過擬合對我們最終模型影響是很大的,有時候訓練時間越長過擬合越嚴重,導致模型表現的效果很差,甚至崩潰;由上圖我們也能看出來解決過擬合問題的必要性。
3. 解決過擬合有哪些方法?
(1)正則化
正則化的思想十分簡單明瞭。由於模型過擬合極有可能是因為我們的模型過於複雜。因此,我們需要讓我們的模型在訓練的時候,在對損失函式進行最小化的同時,也需要讓對引數新增限制,這個限制也就是正則化懲罰項。
假設我們的損失函式是平方損失函式:
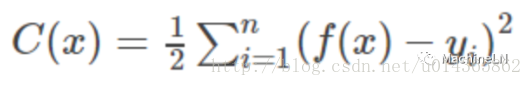
加入正則化後損失函式將變為:
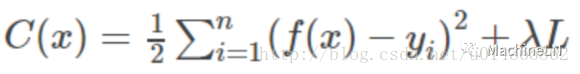
-
L1範數:
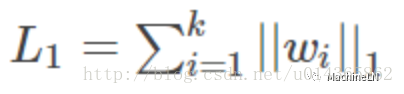
-
L2範數:
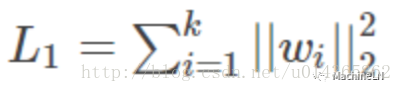
加入L1範數與L2範數其實就是不要使損失函式一味著去減小,你還得考慮到模型的複雜性,通過限制引數的大小,來限制其產生較為簡單的模型,這樣就可以降低產生過擬合的風險。
那麼L1和L2的區別在哪裡呢?L1更容易得到稀疏解:直接看下面的圖吧:(
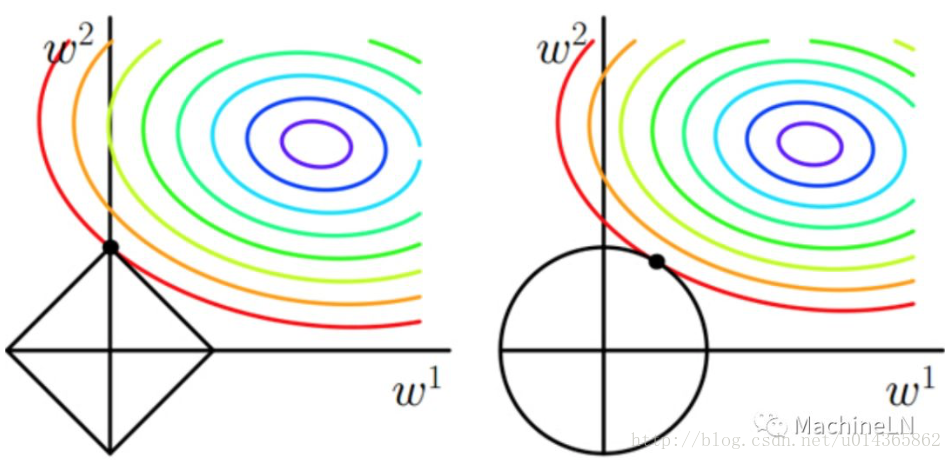
而使用L1正則項的另一個好處是:由於L1正則項求解引數時更容易得到稀疏解,也就意味著求出的引數中含有0較多。因此它自動幫你選擇了模型所需要的特徵。L1正則化的學習方式是一種嵌入式特徵學習方式,它選取特徵和模型訓練時一起進行的。
(2)Dropout
先看下圖:Dropout就是使部分神經元失活,這樣就阻斷了部分神經元之間的協同作用,從而強制要求一個神經元和隨機挑選出的神經元共同進行工作,減輕了部分神經元之間的聯合適應性。也可以這麼理解:Dropout將一個複雜的網路拆分成簡單的組合在一起,這樣彷彿是bagging的取樣過程,因此可以看做是bagging的廉價的實現(但是它們訓練不太一樣,因為bagging,所有的模型都是獨立的,而dropout下所有模型的引數是共享的。);
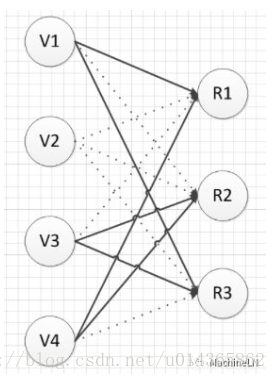
Dropout的具體流程如下:
-
對l層第 j 個神經元產生一個隨機數 :

-
將 l 層第 j 個神經元的輸入乘上產生的隨機數作為這個神經元新的輸入:
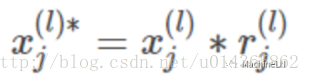
-
此時第 l 層第 j 個神經元的輸出為:
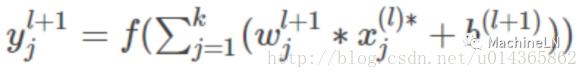
-
注意:當我們採用了Dropout訓練結束之後,應當將網路的權重乘上概率p得到測試網路的權重。
(3)提前終止
由第一副圖可以看出,模型在驗證集上的誤差在一開始是隨著訓練集的誤差的下降而下降的。當超過一定訓練步數後,模型在訓練集上的誤差雖然還在下降,但是在驗證集上的誤差卻不在下降了。此時我們的模型就過擬合了。因此我們可以觀察我們訓練模型在驗證集上的誤差,一旦當驗證集的誤差不再下降時,我們就可以提前終止我們訓練的模型。
(4)bagging 和其他整合方法
其實bagging的方法是可以起到正則化的作用,因為正則化就是要減少泛化誤差,而bagging的方法可以組合多個模型起到減少泛化誤差的作用;在深度學習中同樣可以使用此方法,但是其會增加計算和儲存的成本。
(5)深度學習中的BN
深度學習中BN也是解決過擬合的有效方法:可以參考之前的文章:DeepLN之BN。
在實際的專案中,你會發現,上面講述的那些技巧雖然都可以減輕過擬合,但是卻都比不上增加樣本量來的更實在。為什麼增加樣本可以減輕過擬合的風險呢?這個要從過擬合是啥來說。過擬合可以理解為我們的模型對樣本量學習的太好了,把一些樣本的特殊的特徵當做是所有樣本都具有的特徵。舉個簡單的例子,當我們模型去訓練如何判斷一個東西是不是葉子時,我們樣本中葉子如果都是鋸齒狀的話,如果模型產生過擬合了,會認為葉子都是鋸齒狀的,而不是鋸齒狀的就不是葉子了。如果此時我們把不是鋸齒狀的葉子資料增加進來,此時我們的模型就不會再過擬合了。(這個在最近的專案裡常用)因此其實上述的那些技巧雖然有用,但是在實際專案中,你會發現,其實大多數情況都比不上增加樣本資料來的實在。
展望:深度學習系列再更新幾篇後要暫時告一段落,開始總結傳統機器學習的內容:KNN;決策樹;貝葉斯;Logistic迴歸;SVM;AdaBoost;K-means等的理論和實踐;中間穿插資料結構和演算法(排序;散列表;搜尋樹;動態規劃;貪心;圖;字串匹配等);再之後我們重回Deep learning;
推薦閱讀:
