
Python3爬蟲之四簡單爬蟲架構【爬取百度百科python詞條網頁】
阿新 • • 發佈:2019-02-01
前面介紹了Python寫簡單的爬蟲程式,這裡參考慕課網Python開發簡單爬蟲總結一下爬蟲的架構。讓我們的爬蟲程式模組劃分更加明確,程式碼具有更佳的邏輯性、可讀性。因此,我們可以將整個爬蟲程式總結為以下5個模組:
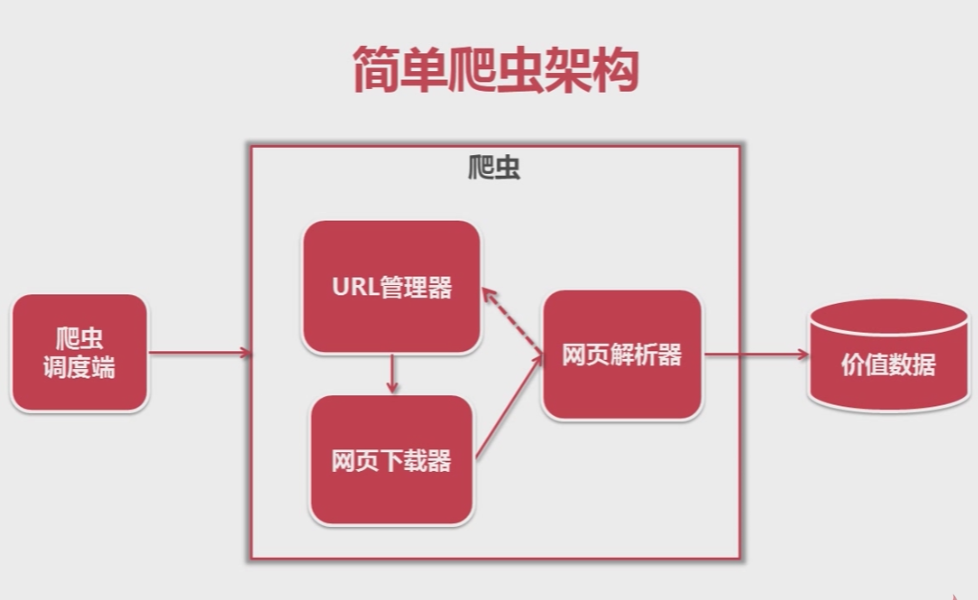
1、爬蟲排程端:負責啟動、停止、監控爬蟲程式的執行;
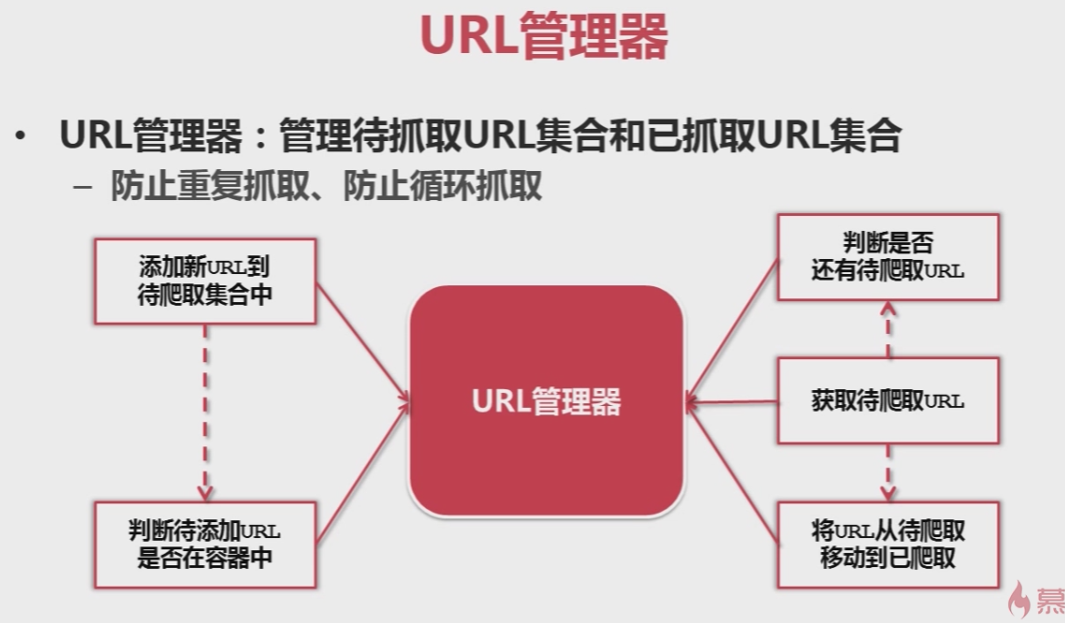
2、URL管理器:負責爬蟲執行過程中待爬取的URL佇列和已爬取的URL佇列的管理【防重複、防迴圈抓取】;
3、網頁下載器:把url指向的網頁下載下來;
4、網頁解析器:解析下載下來的網頁,一方面可以得到網頁中有價值的資訊,另一方面可以得到網頁中新的URL連結,儲存到URL管理器中;
5、結果:將解析器中得到的結果按我們期望的格式展現出來;
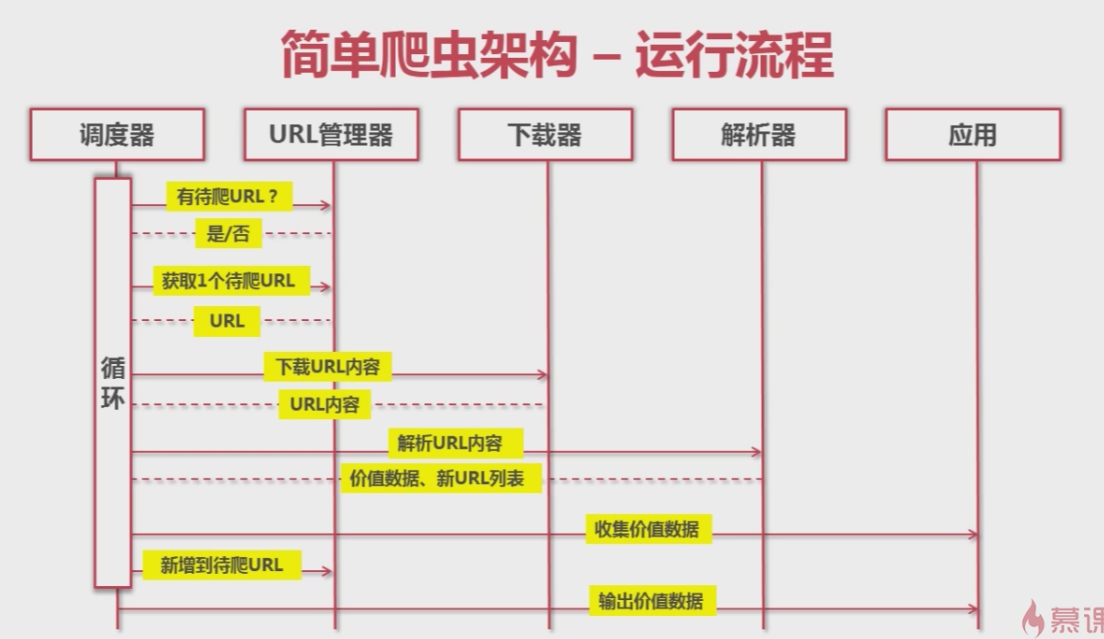
整個執行過程就是,排程器啟動爬蟲,從URL管理器中取一條待爬取的URL,呼叫下載器進行網頁的下載,呼叫網頁解析器對下載的網頁進行解析,將新的URL加入到URL管理器中,將提取到的資料展示出來。如圖
下面以爬取百度百科Python詞條為例【http://baike.baidu.com/item/Python】,運用爬蟲架構的方式實現相關頁面的抓取:
1、爬蟲總除錯程式---負責對程式各模組的排程
# coding=utf-8 from BaikePython import URLManager, HTMLDownloader, HTMLParser, HTMLOutput # 爬蟲總排程程式 class SpiderMain(object): # 建構函式初始化url管理器、HTML下載器、HTML解析器、輸出四個物件 def __init__(self): # url管理器 self.urls = URLManager.url_manager() # url下載器 self.downloader = HTMLDownloader.html_downloader() # url解析器 self.parser = HTMLParser.html_parser() # 最終的輸出 self.outputer = HTMLOutput.html_output() # 爬蟲排程程式 def craw(self, root_url): count = 1 # 新增入口URL self.urls.add_new_url(root_url) while self.urls.has_new_url(): try: # 取出新的URL new_url = self.urls.get_new_url() # 下載該url對應的頁面 print("craw %d : %s" % (count, new_url)) html_cont = self.downloader.download(new_url) # 解析該url對應的頁面,得到新的連結和內容 new_urls, new_data = self.parser.parse(new_url, html_cont) # 將新url新增到url管理器中 self.urls.add_new_urls(new_urls) # 將解析到的內容收集起來 self.outputer.collect_data(new_data) if count == 1000: # 爬取1000個頁面即可 break count = count + 1 except: print("craw fail") # 最終輸出爬取目標的內容 self.outputer.output_html() # 主函式啟動爬蟲 if __name__=="__main__": # root_url = "http://baike.baidu.com/item/Python/407313?fr=aladdin" root_url = "http://baike.baidu.com/item/Python" obj_Spider = SpiderMain() obj_Spider.craw(root_url)
2、URL管理器---維護待爬取URL和已爬取URL兩個佇列
class url_manager(object): # URL管理器中維護兩個集合 def __init__(self): # 待爬取的url集合 self.new_urls = set() # 已爬取的url集合 self.old_urls = set() # 向管理器中新增一個新的url def add_new_url(self, url): if url is None: return if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) # 向管理器中批量新增urls def add_new_urls(self, urls): if urls is None or len(urls) == 0: return for url in urls: self.add_new_url(url) # 判斷待爬取列表是否有待爬取的url def has_new_url(self): return len(self.new_urls) != 0 # 從待爬取的集合中獲取一個需要爬取的url def get_new_url(self): new_url = self.new_urls.pop() self.old_urls.add(new_url) return new_url
3、網頁下載器---下載指定的頁面【有三種方法】
import urllib
class html_downloader(object):
# 下載url對應的頁面
def download(self, url):
if url is None:
return None
response = urllib.request.urlopen(url)
if response.getcode() != 200:
return None
return response.read()
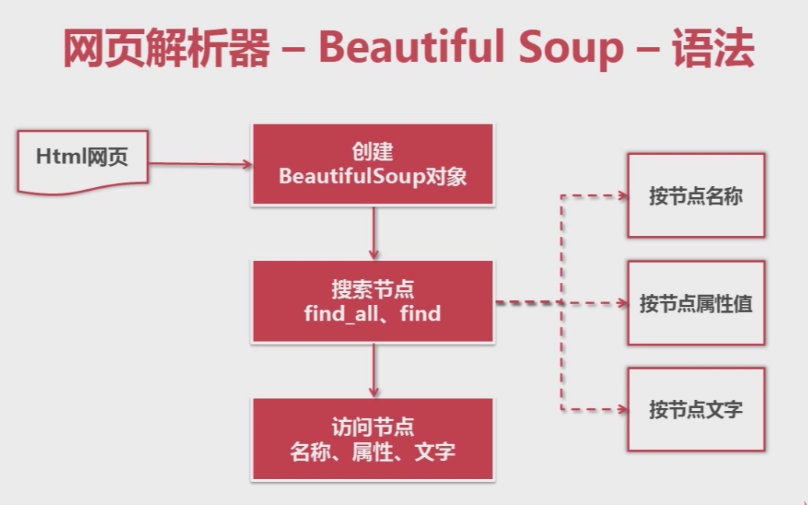
4、網頁解析器
import re
import urllib
from bs4 import BeautifulSoup
class html_parser(object):
# 從HTML頁面中解析出新的url和頁面內容
def parse(self, url, html_content):
if url is None or html_content is None:
return
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(url, soup)
new_data = self._get_new_data(url, soup)
return new_urls, new_data
def _get_new_urls(self, url, soup):
new_urls = set()
# # /item/****
# links = soup.find_all('a', href=re.compiler(r"/item/\S+"))
# /view/123.htm
links = soup.find_all('a', href=re.compile(r'/item/(.*)'))
for link in links:
new_url = link['href']
new_full_url = urllib.parse.urljoin(url, new_url)
new_urls.add(new_full_url)
return new_urls
# 解析網頁的標題標籤title和簡介標籤summary
def _get_new_data(self, url, soup):
res_data= {}
res_data['url'] = url
# 標題標籤
# <dd class ="lemmaWgt-lemmaTitle-title" >
# < h1 > Python < / h1 >
title_node = soup.find('dd', class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data['title'] = title_node.get_text()
# <div class="lemma-summary" label-module="lemmaSummary">
summary_node = soup.find('div', class_="lemma-summary")
res_data['summary'] = summary_node.get_text()
return res_data5、輸出到檔案
class html_output(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout = open('output.html', 'w', encoding='utf-8')
fout.write("<html>")
fout.write("<body>")
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>" % data['url'])
fout.write("<td>%s</td>" % data['title'])
fout.write("<td>%s</td>" % data['summary'])
fout.write("</tr>")
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
fout.close()