
lstm+ctc 實現ocr識別
轉載地址:
https://zhuanlan.zhihu.com/p/21344595
OCR是一個古老的研究領域,簡單說就是把圖片上的文字轉化為文字的過程。在最近幾年隨著大資料的發展,廣大爬蟲工程師在對抗驗證碼時也得用上OCR。所以,這篇文章主要說的OCR其實就是圖片驗證碼的識別。OCR並不是我的研究方向,我研究這個問題是因為OCR是一個可以同時用CNN,RNN兩種演算法都可以很好解決的問題,所以用這個問題來熟悉一個深度學習框架是非常適合的。我主要通過研究這個問題來了解mxnet。
驗證碼識別的思路非常暴力,大概就是這樣:
- 去噪+二值化
- 字元分割
- 每個字元識別
驗證碼的難度在這3步上都有反應。比如
-
噪聲:加一條貫穿全圖的曲線,比如網格線,還有圖的一半是白底黑字,另一半是黑底白字。
- 分割:字元粘連,7和4粘在一起。
- 識別:字元各種扭曲,各種旋轉。
但相對而言,難度最大的是第2步,分割。所以就有人想,我能不能不做分割,就把驗證碼給識別了。深度學習擅長做端到端的學習,因此這個不分割就想識別的事情交給深度學習是最合適的。
基於CNN的驗證碼識別
基於CNN去識別驗證碼,其實就是一個圖片的多標籤學習問題。比如考慮一個4個數字組成的驗證碼,那麼相當於每張圖就有4個標籤。那麼我們把原始圖片作為輸入,4個標籤作為輸出,扔進CNN裡,看看能不能收斂就行了。
下面這段程式碼定義了mxnet上的一個DataIter,我們用了python-captcha這個庫來自動生成訓練樣本,所以可以假設訓練樣本是無窮多的。
class OCRIter(mx.io.DataIter):
def __init__(self, count, batch_size, num_label, height, width):
super(OCRIter, self).__init__()
self.captcha = ImageCaptcha(fonts=['./data/OpenSans-Regular.ttf'])
self.batch_size = batch_size
self.count = count
self.height = height
self.width = 下面這段程式碼是網路結構:
def get_ocrnet():
data = mx.symbol.Variable('data')
label = mx.symbol.Variable('softmax_label')
conv1 = mx.symbol.Convolution(data=data, kernel=(5,5), num_filter=32)
pool1 = mx.symbol.Pooling(data=conv1, pool_type="max", kernel=(2,2), stride=(1, 1))
relu1 = mx.symbol.Activation(data=pool1, act_type="relu")
conv2 = mx.symbol.Convolution(data=relu1, kernel=(5,5), num_filter=32)
pool2 = mx.symbol.Pooling(data=conv2, pool_type="avg", kernel=(2,2), stride=(1, 1))
relu2 = mx.symbol.Activation(data=pool2, act_type="relu")
conv3 = mx.symbol.Convolution(data=relu2, kernel=(3,3), num_filter=32)
pool3 = mx.symbol.Pooling(data=conv3, pool_type="avg", kernel=(2,2), stride=(1, 1))
relu3 = mx.symbol.Activation(data=pool3, act_type="relu")
flatten = mx.symbol.Flatten(data = relu3)
fc1 = mx.symbol.FullyConnected(data = flatten, num_hidden = 512)
fc21 = mx.symbol.FullyConnected(data = fc1, num_hidden = 10)
fc22 = mx.symbol.FullyConnected(data = fc1, num_hidden = 10)
fc23 = mx.symbol.FullyConnected(data = fc1, num_hidden = 10)
fc24 = mx.symbol.FullyConnected(data = fc1, num_hidden = 10)
fc2 = mx.symbol.Concat(*[fc21, fc22, fc23, fc24], dim = 0)
label = mx.symbol.transpose(data = label)
label = mx.symbol.Reshape(data = label, target_shape = (0, ))
return mx.symbol.SoftmaxOutput(data = fc2, label = label, name = "softmax")
上面這個網路要稍微解釋一下。因為這個問題是一個有順序的多label的圖片分類問題。我們在fc1的層上面接了4個Full Connect層(fc21,fc22,fc23,fc24),用來對應不同位置的4個數字label。然後將它們Concat在一起。然後同時學習這4個label。目前用上面的網路訓練,4位數字全部預測正確的精度可以達到95%左右(因為是無窮多的訓練樣本,所以只要能不斷訓練下去,精度還是可以提高的,只是我訓練到95%左右就停止訓練了)。
用CNN解決驗證碼識別有個問題,就是必須針對固定長度的驗證碼去做。如果長度不固定,或者是手寫一行字的識別這種長度肯定不固定的問題,CNN就沒辦法了。這個時候就需要引入序列學習的模型了。
基於LSTM+CTC的驗證碼識別
LSTM+CTC被廣泛的用在語音識別領域把音訊解碼成漢字,從這個角度說,OCR其實就是把圖片解碼成漢字,並沒有太本質的區別。而且在整個過程中,不需要提前知道究竟要解碼成幾個字。
這個演算法的思路是這樣的。假設要識別的圖片是80x30的圖片,裡面是一個長度為k的數字驗證碼。那麼我們可以沿著x軸對圖片進行切分,切成n個圖片,作為LSTM的n個輸入。在最極端的例子裡,n=80。那麼就是把圖片的每一列都作為輸入。LSTM有n個輸入就會有n個輸出,而這n個輸出可以通過CTC計算和k個驗證碼標籤之間的Loss,然後進行反向傳播。
我們同樣用python-captcha自動生成驗證碼作為訓練樣本,用如下的程式碼來定義網路結構: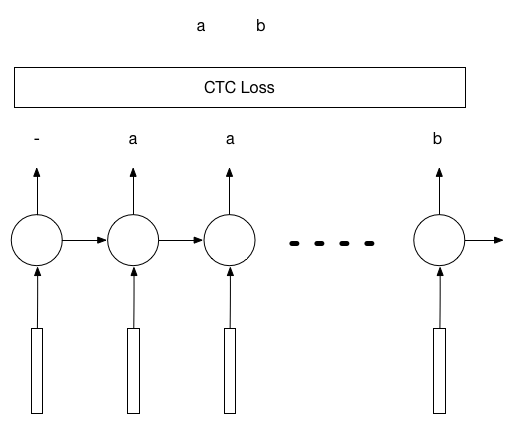
def lstm_unroll(num_lstm_layer, seq_len,
num_hidden, num_label):
param_cells = []
last_states = []
for i in range(num_lstm_layer):
state = LSTMState(c=mx.sym.Variable("l%d_init_c" % i),
h=mx.sym.Variable("l%d_init_h" % i))
last_states.append(state)
assert(len(last_states) == num_lstm_layer)
# embeding layer
data = mx.sym.Variable('data')
label = mx.sym.Variable('label')
wordvec = mx.sym.SliceChannel(data=data, num_outputs=seq_len, squeeze_axis=1)
hidden_all = []
for seqidx in range(seq_len):
hidden = wordvec[seqidx]
for i in range(num_lstm_layer):
next_state = lstm(num_hidden, indata=hidden,
prev_state=last_states[i],
param=param_cells[i],
seqidx=seqidx, layeridx=i)
hidden = next_state.h
last_states[i] = next_state
hidden_all.append(hidden)
hidden_concat = mx.sym.Concat(*hidden_all, dim=0)
pred = mx.sym.FullyConnected(data=hidden_concat, num_hidden=11)
label = mx.sym.Reshape(data=label, target_shape=(0,))
label = mx.sym.Cast(data = label, dtype = 'int32')
sm = mx.sym.WarpCTC(data=pred, label=label, label_length = num_label, input_length = seq_len)
return sm
這裡有2點需要注意的:
- 在一般的mxnet的lstm實現中,label需要轉置,但是在warpctc的實現中不需要。
- label需要是int32的格式,需要cast。
關於CTC Loss的重要性,我試過不用CTC的兩個不同想法:
- 用encode-decode模式。用80個輸入做encode,然後decode成4個輸出。實測效果很差。
-
4個label每個copy20遍,從而變成80個label。實測也很差。
用ctc loss的體會就是,如果input的長度遠遠大於label的長度,比如我這裡是80和4的關係。那麼一開始的收斂會比較慢。在其中有一段時間cost幾乎不變。此刻一定要有耐心,最終一定會收斂的。在ocr識別的這個例子上最終可以收斂到95%的精度。