機器學習-學習筆記 模型評估與選擇
經驗誤差與過擬合
瞭解錯誤率 ,精度 ,誤差 ,訓練誤差(經驗誤差) ,泛化誤差的概念

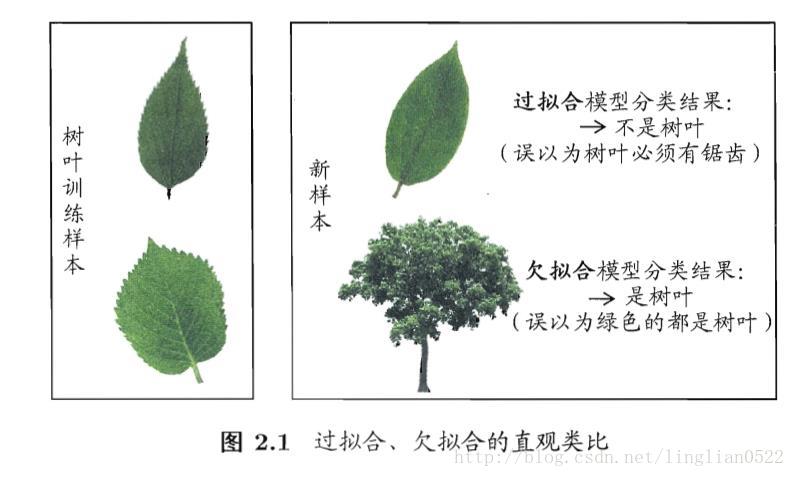
過擬合(過配)和欠擬合(欠配)
過擬合就是過度擬合,即將樣本自身的一些特點當做了樣本的一般特性, 使得泛化能力降低,注意,過擬合無法避免。
欠擬合則與之相反。
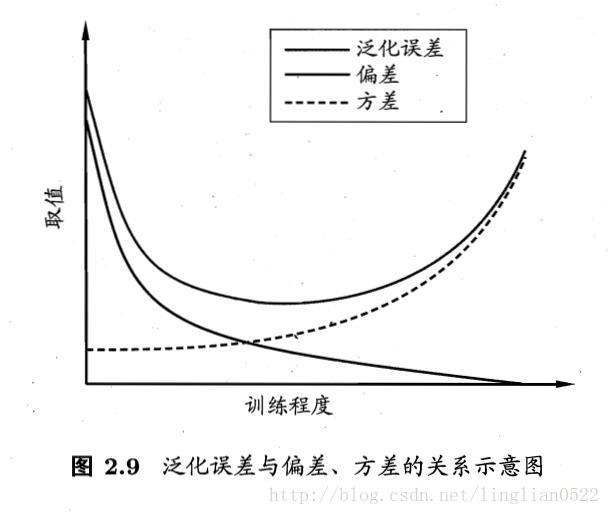
模型選擇時,選擇泛化誤差最小的, 但是我們無法直接獲得泛化誤差,而訓練誤差因為過擬合的存在而不適合作為判斷標準。
評估方法
留出法
將資料D劃分為二個互斥的集合,一個集合訓練完,另一個集合用來將第一個集合訓練完的模型進行誤差測試。
交叉驗證法
就是將集合分為k個大小相似的互斥子集, 分為訓練集、測試集,進行誤差測試。
自助法
採用自主取樣法, 自動生成訓練和測試集,進行誤差測試。
適用於資料集較小的情況,非常有用。
調參和最終模型
進行引數步長的設定,讓其自行調參,測試誤差。
效能度量
對學習器進行評估,不僅需要科學可行的方法, 還需要有衡量模型泛化能力的評估標準,這就是效能度量。
效能度量反映了任務需求,在預測任務中,進行效能評估,把預測結果與真實標記進行比較即可。

錯誤度與精度
跟前面說的錯誤度和精度一樣。

查準率、查全率與F1
查準率就是找到的裡面,正確的所佔的比例。
查全率就是在正確的裡面,查出來的多少,所佔正確的比例。
往往二者不可得兼。

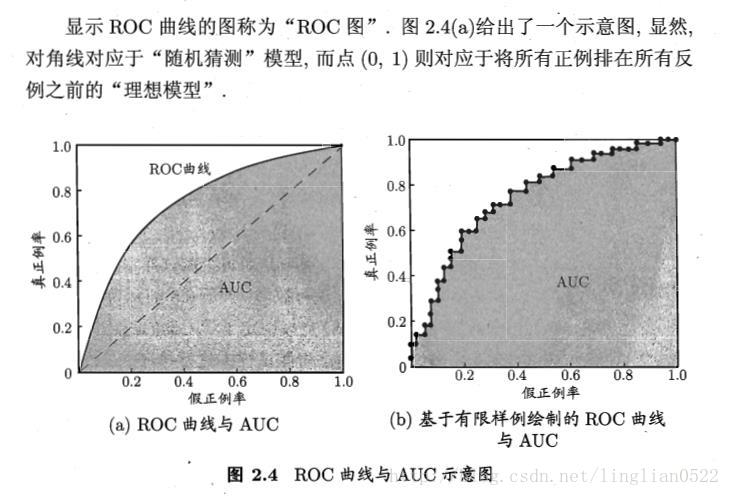
ROC與AUC
用來研究學習器泛化能力的有力工具。
ROC(受試者工作特性), 我們根據學習期的預測結果對樣例進行排序,按此順序逐個把樣本作為正例進行預測,每次計算出二個重要的值,分別為他們的橫縱軸,就得到ROC圖。
AUC 就是比較ROC下面的面積如下圖。
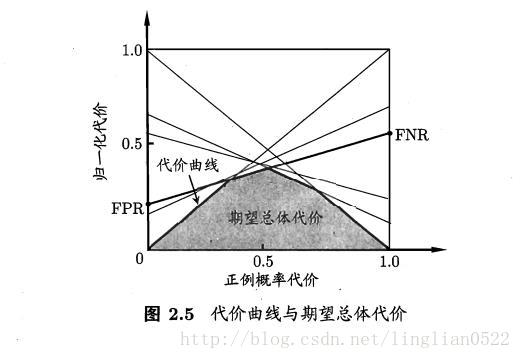
代價敏感錯誤率與代價曲線
這裡引出非均等代價的概念,之前的例子都是均等代價。
在非均等代價下,就不可以用ROC來表示效能,而是用代價曲線來表示。

比較檢驗
當我們得出了效能度量後,我們應該怎麼進行比較呢?
我們引出下面幾個比較檢驗的概念。
假設檢驗
假設檢驗就是對錯誤率(也可以是別的度量或者某種情況)進行假設(通常假設在某個範圍內),接著進行二項檢驗或t檢驗。
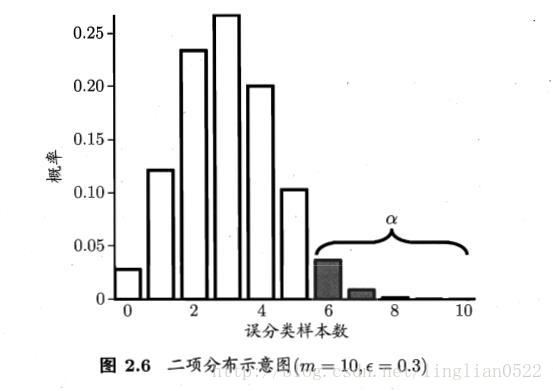
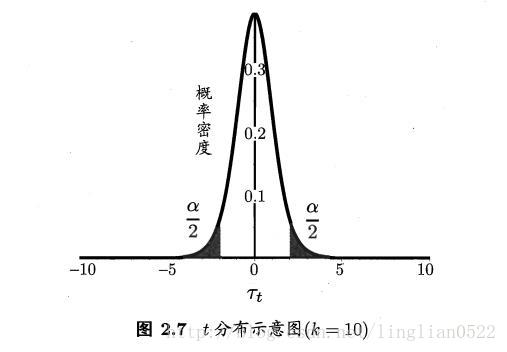
交叉驗證t檢驗
交叉驗證在有2個或者多個學習器的情況下,假設多個學習器的效能相同,進行交叉驗證,就是將資料集進行多次訓練和測試,將多個學習器的效能(在這裡是錯誤率)進行t檢驗。
McMemar檢驗
在進行留出法對2個學習器進行效能測試的時候, 我們會得到錯誤率以及二個學習器的差別,我們假設二個學習器效能一樣,那麼在進行下述計算後,得到的平均錯誤率較小的那個學習器效能則更優。

Friedman檢驗與Nemenyi後續檢驗
Friedman檢驗就是將多個演算法和多個數據進行交叉多次訓練和測試,得到的結果,如果得到的結果有顯著的區別,則進行Nemenyi後續檢驗,計算出平均臨界值域, 然後進行,二二比較,如果超出臨界值域,則二個演算法顯著不同,反之,而差距不大。
偏差與方差
偏差-方差分解是解釋學習演算法泛化效能的一種重要工具。
偏差度量了學習演算法的期望預測與真實結果的偏離程度(擬合能力)。
方差度量了同樣大小的訓練集的變動所導致的學習效能的變化,即刻畫了資料擾動所造成的影響。
噪聲則表達了在當前任務上任何學習演算法所能達到的期望泛化誤差的下界,即刻畫了學習問題本身的難度。