
scrapy爬蟲編寫流程
1:建立虛擬環境 mkvirtualenv --python=(python路徑) 虛擬環境名
2:進入虛擬環境 workon 虛擬環境名
3:安裝scrapy 使用豆瓣源安裝 pip install -i https://pypi.douban.com/simple/ scrapy
4:進入工程目錄,建立工程 scrapy startproject ArticleSpider(專案名稱)
5:進入pycharm,匯入工程,選擇環境
6:進入spiders,建立爬蟲 scrapy genspider jobbole(名稱) blog.jobbole.com(域名)
7:建立main.py進行除錯
from scrapy.cmdline import execute
import sys
import os
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy","crawl","jobbole"])
8:在settings.py中設定ROBOTSTXT_OBEY = False
9:編寫parse()函式
功能:
1.獲取文章列表中的文章url並交給scrapy下載後並進行解析
2.獲取下一頁的url並交給scrapy進行下載, 下載完成後交給parse
0:呼叫
import scrapy
import re
from scrapy.http import Request
from urllib import parse1:程式碼
def parse(self, response): """ 1.獲取文章列表中的文章url並交給scrapy下載後並進行解析 2.獲取下一頁的url並交給scrapy進行下載, 下載完成後交給parse :param response: :return: """ #獲取列表頁所有文章的url並交給scrapy下載後進行解析 post_nodes = response.css("div#archive div.floated-thumb div.post-thumb a") for post_node in post_nodes: post_url = post_node.css("::attr(href)").extract_first("") img_url = post_node.css("img::attr(src)").extract_first("") # img_url = parse.urljoin(response.url,img_url) yield Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url":img_url},callback=self.parse_detail,dont_filter=True) # print(post_url) #提取下一頁url並交給scrapy進行下載 next_url = response.css("a.next.page-numbers::attr(href)").extract_first() if next_url: yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse,dont_filter=True)
yield用於交給scrapy進行下載
parse.urljoin將域名和網址合併成最終網址
callback傳遞迴調函式
設定dont_filter=True防止被過濾掉而不去執行callback
meta引數很重要,用來將列表頁面爬取的內容如封面圖傳遞給parse_deatil中的response,在response中可以用front_image_url = response.meta.get("front_image_url","")接收
10:在jobbole.py中的定義方法paser_detail(self,response),使用xpath或css選擇器對網頁欄位解析。 start_urls設定為爬蟲初始列表頁網址。
在cmd中使用 scrapy shell 網址 進行除錯
response.xpth("xpth語法/text()").extract_first()
response.css("css語法::text").extract_first()
xpath:


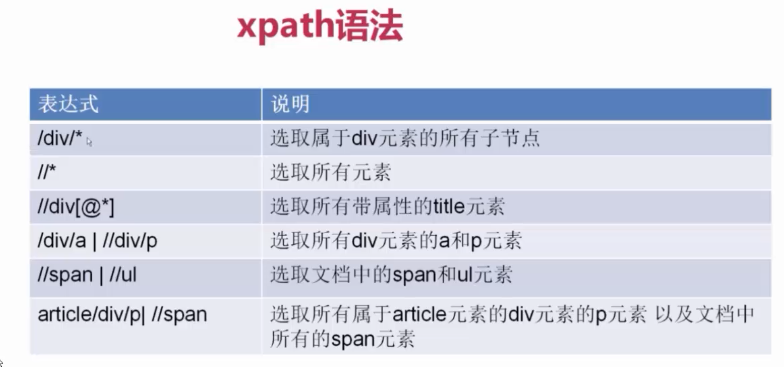
@後跟屬性名
屬性名=“屬性值”
/text()提取標籤內容
response.xpath().extract() 可提取內容組成陣列
如果一個標籤的屬性有多個值,xpath可呼叫函式contains
response.xpath("//span[contains(@class,'vote-post-up')]")
即:span標籤中包含vote-post-up即可
css:
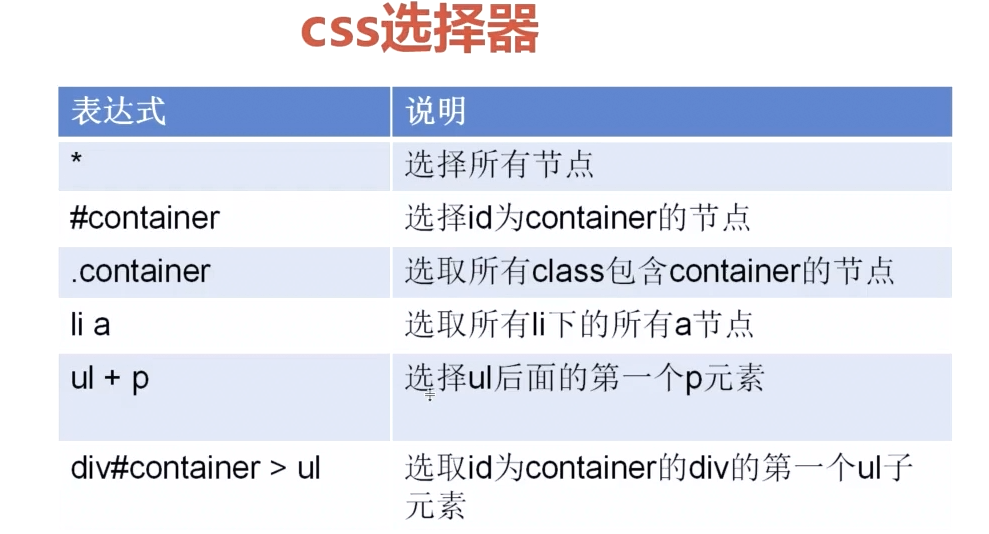
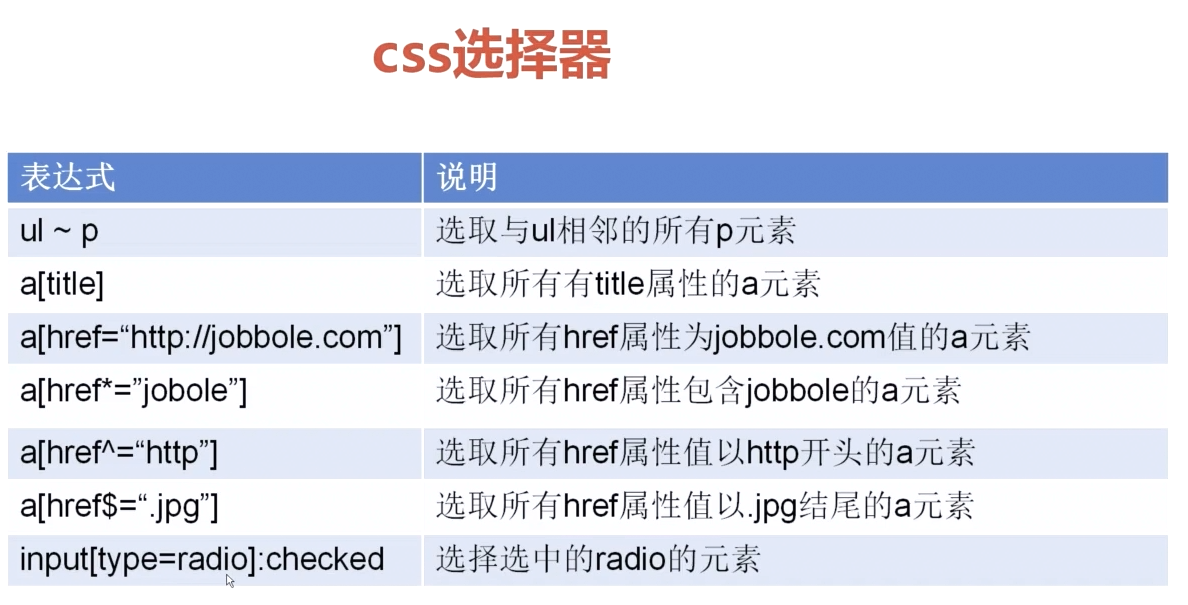

例:
def parse_detail(self, response):
#提取文章具體欄位
# re_selector = response.xpath("//*[@id='post-113568']/div[1]/h1/text()")
title = response.xpath("//*[@id='post-113568']/div[1]/h1/text()").extract()[0]
praise_nums = response.xpath("//div[@class='post-adds']/span[1]/h10/text()").extract()[0]
fav_nums = response.xpath("//div[@class='post-adds']/span[2]/text()").extract()[0]
match_re = re.match(".*(\d+).*",fav_nums)
if match_re:
fav_nums = int(match_re.group(1))
else:
fav_nums = 0response.css("div#archive div.floated-thumb div.post-thumb a::attr(href)").extract_first()
11:編寫items.py
將爬取過來的每一個item例項路由到pipelines,在piplines中集中處理資料的儲存、去重等。類似於字典,比字典功能要多。在Item中只有一個Field型別,可以儲存任意資料型別。title = scrapy.Filed()
在items.py中新建一個類,並定義好item
class JobBoleArticleItem(scrapy.Item):
title = scrapy.Field()
create_data = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
front_image_url = scrapy.Field()
front_image_path = scrapy.Field()
praise_nums = scrapy.Field()
comment_nums = scrapy.Field()
fav_nums = scrapy.Field()
tags = scrapy.Field()
content = scrapy.Field()在jobbole.py中引用定義好的JobBoleArticleItem
from ArticleSpider.items import JobBoleArticleItem在函式parse_detail中將爬取的項儲存在item中
article_item = JobBoleArticleItem()
article_item["title"] = title
article_item["url"] = response.url
article_item["create_data"] = creat_data
article_item["front_image_url"] = front_image_url
article_item["fav_nums"] = fav_nums
article_item["comment_nums"] = comment_nums
article_item["praise_nums"] = praise_nums
article_item["tags"] = tags
article_item["content"] = content
yield article_item #傳遞到pipelines中12:配置settings.py和pipelines.py
在settings.py中將item的pipeline開啟
ITEM_PIPELINES = {
'ArticleSpider.pipelines.ArticlespiderPipeline': 300,#item的傳輸管道 數字越小越早進入管道
# 'scrapy.pipelines.images.ImagesPipeline':1, #比300小說明先進入這裡
'ArticleSpider.pipelines.ArticleImagePipeline': 1,
}
IMAGES_URLS_FIELD = "front_image_url" #處理的形式為陣列 所以要將item中此項改為陣列
project_dir = os.path.abspath(os.path.dirname(__file__))
IMAGES_STORE = os.path.join(project_dir,"images")scrapy.pipelines.images.ImagesPipeline 是將爬取的圖片進行下載
IMAGES_URLS_FIELD 是將item中的front_image_url傳遞過來 才能對圖片進行下載
project_dir 為獲取當前目錄
IMAGES_STORE 設定圖片儲存路徑
ArticleSpider.pipelines.ArticleImagePipeline為在piplinse.py中的自定義類
from scrapy.pipelines.images import ImagesPipelineclass ArticleImagePipeline(ImagesPipeline):
def item_completed(self, results, item, info):
for ok, value in results:
image_file_path = value["path"]
item["front_image_path"] = image_file_path
return item該類繼承ImagesPipeline 並重寫了item_completed方法,目的是獲取圖片路徑並新增到item
url_object_id = scrapy.Field() #使用md5函式把url變成等長的唯一序列獲取url的id就是將url通過md5方法變成唯一等長的序列
md5方法需要自己編寫,新建utils包用於放自定義常用函式,建立common.py
import hashlib
def get_md5(url):
if isinstance(url, str):
url = url.encode("utf-8")
m = hashlib.md5()
m.update(url)
return m.hexdigest()由於python3中為unicode編碼(判斷是否為str等同於判斷是否為unicode)而md5方法不識別,所以需要將傳過來的url編碼成utf-8.
生成id為0efdf49af511fd88681529ef8c2e5fbf的形式
然後在parse_detail方法中加入item項
article_item["url_object_id"] = get_md5(response.url)這時,所有的item項賦值完畢。
13.將爬取的item儲存到資料庫或本地
將item儲存為json檔案,建立儲存json的pipeline
自定義方式:
import codecs
import jsonclass JsonWithEncodingPipeline(object):
#自定義匯出json檔案
def __init__(self):
self.file = codecs.open('article.json', 'w',encoding="utf-8")
def process_item(self, item, spider):
lines = json.dumps(dict(item), ensure_ascii=False) + "\n" #將item轉為字典,ensure_ascii設定為False否則當有中文或其他編碼時出錯
self.file.write(lines)
return item
def spider_closed(self, spider):
self.file.close()使用提供的JsonItemExporter方式:
from scrapy.exporters import JsonItemExporterclass JsonExporterPipleline(object):
#呼叫scrapy提供的json export匯出json檔案
def __init__(self):
self.file = open('articleexport.json','wb')
self.exporter = JsonItemExporter(self.file,encoding="utf-8",ensure_ascii=False)
self.exporter.start_exporting()
def close_spider(self,spider):
self.exporter.finish_exporting()
self.file.close()
def process_item(self, item, spider):
self.exporter.export_item(item)
return item同時需要在settings.py中設定
ITEM_PIPELINES = {
# 'ArticleSpider.pipelines.ArticlespiderPipeline': 300,#item的傳輸管道 數字越小越早進入管道
# 'scrapy.pipelines.images.ImagesPipeline':1, #比300小說明先進入這裡
# 'ArticleSpider.pipelines.JsonWithEncodingPipeline': 3,
'ArticleSpider.pipelines.JsonExporterPipleline':2,
'ArticleSpider.pipelines.ArticleImagePipeline': 1,
}
IMAGES_URLS_FIELD = "front_image_url" #處理的形式為陣列 所以要將item中此項改為陣列
project_dir = os.path.abspath(os.path.dirname(__file__))
IMAGES_STORE = os.path.join(project_dir,"images")將item儲存到mysql資料庫
pipeline中設定
import MySQLdb
import MySQLdb.cursors
from twisted.enterprise import adbapi #twisted提供非同步操作容器class MysqlTwistedPipeline(object):
def __init__(self,dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings):
dbparms = dict(
host = settings["MYSQL_HOST"],
db = settings["MYSQL_DBNAME"],
user = settings["MYSQL_USER"],
passwd = settings["MYSQL_PASSWORD"],
charset = "utf8",
cursorclass = MySQLdb.cursors.DictCursor,
use_unicode = True,
)
dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms)
return cls(dbpool)
def process_item(self, item, spider):
#使用twisted將mysql插入變成非同步執行
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error)#處理異常
def handle_error(self, failure):
#處理非同步的異常
print(failure)
def do_insert(self, cursor, item):
#執行具體的插入
insert_sql = "insert into jobbole_article(title, create_data, url,fav_nums,url_object_id) VALUES (%s,%s,%s,%s,%s)"
cursor.execute(insert_sql,(item["title"],item["create_data"],item["url"],item["fav_nums"],item["url_object_id"]))
在settings.py中進行相應設定