
BP神經網路簡單流程
阿新 • • 發佈:2019-02-01
BP(Back Propagation)神經網路是一種具有三層或者三層以上的多層神經網路,每一層都由若干個神經元組成,它的左、右各層之間各個神經元實現全連線,即左層的每一個神經元與右層的每個神經元都由連線,而上下各神經元之間無連線。BP神經網路按有導師學習方式進行訓練,當一對學習模式提供給神經網路後,其神經元的啟用值將從輸入層經各隱含層向輸出層傳播,在輸出層的各神經元輸出對應於輸入模式的網路響應。然後,按減少希望輸出與實際輸出誤差的原則,從輸出層經各隱含層,最後回到輸入層(從右到左)逐層修正各連線權。由於這種修正過程是從輸出到輸入逐層進行的,所以稱它為“誤差逆傳播演算法”。隨著這種誤差逆傳播訓練的不斷修正,網路對輸入模式響應的正確率也將不斷提高。
一、BP神經網路的概念
BP神經網路是一種多層的前饋神經網路,其主要的特點是:訊號是前向傳播的,而誤差是反向傳播的。具體來說,對於如下的只含一個隱層的神經網路模型: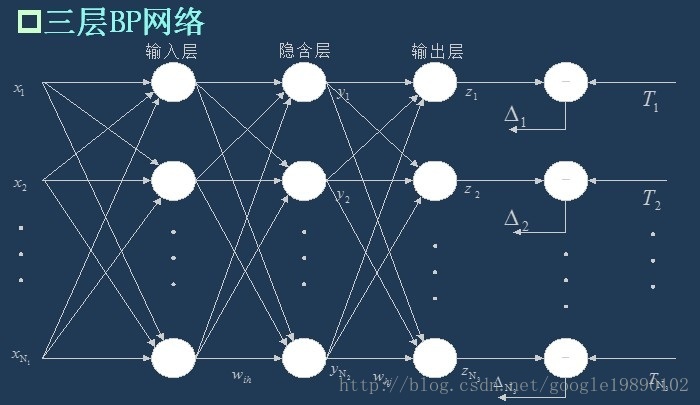
(三層BP神經網路模型) BP神經網路的過程主要分為兩個階段,第一階段是訊號的前向傳播,從輸入層經過隱含層,最後到達輸出層;第二階段是誤差的反向傳播,從輸出層到隱含層,最後到輸入層,依次調節隱含層到輸出層的權重和偏置,輸入層到隱含層的權重和偏置。
二、BP神經網路的流程
在知道了BP神經網路的特點後,我們需要依據訊號的前向傳播和誤差的反向傳播來構建整個網路。1、網路的初始化
假設輸入層的節點個數為2、隱含層的輸出
如上面的三層BP網路所示,隱含層的輸出3、輸出層的輸出
4、誤差的計算
我們取誤差公式為:其中
以上公式中,
5、權值的更新
權值的更新公式為:這裡需要解釋一下公式的由來: 這是誤差反向傳播的過程,我們的目標是使得誤差函式達到最小值,即
- 隱含層到輸出層的權重更新
- 輸入層到隱含層的權重更新
則權重的更新公式為:
6、偏置的更新
偏置的更新公式為:- 隱含層到輸出層的偏置更新
- 輸入層到隱含層的偏置更新
則偏置的更新公式為:
7、判斷演算法迭代是否結束
有很多的方法可以判斷演算法是否已經收斂,常見的有指定迭代的代數,判斷相鄰的兩次誤差之間的差別是否小於指定的值等等。三、實驗的模擬
在本試驗中,我們利用BP神經網路處理一個四分類問題,最終的分類結果為: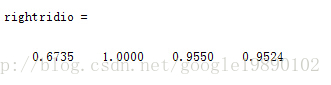
MATLAB程式碼
主程式
%% BP的主函式
% 清空
clear all;
clc;
% 匯入資料
load data;
%從1到2000間隨機排序
k=rand(1,2000);
[m,n]=sort(k);
%輸入輸出資料
input=data(:,2:25);
output1 =data(:,1);
%把輸出從1維變成4維
for i=1:2000
switch output1(i)
case 1
output(i,:)=[1 0 0 0];
case 2
output(i,:)=[0 1 0 0];
case 3
output(i,:)=[0 0 1 0];
case 4
output(i,:)=[0 0 0 1];
end
end
%隨機提取1500個樣本為訓練樣本,500個樣本為預測樣本
trainCharacter=input(n(1:1600),:);
trainOutput=output(n(1:1600),:);
testCharacter=input(n(1601:2000),:);
testOutput=output(n(1601:2000),:);
% 對訓練的特徵進行歸一化
[trainInput,inputps]=mapminmax(trainCharacter');
%% 引數的初始化
% 引數的初始化
inputNum = 24;%輸入層的節點數
hiddenNum = 50;%隱含層的節點數
outputNum = 4;%輸出層的節點數
% 權重和偏置的初始化
w1 = rands(inputNum,hiddenNum);
b1 = rands(hiddenNum,1);
w2 = rands(hiddenNum,outputNum);
b2 = rands(outputNum,1);
% 學習率
yita = 0.1;
%% 網路的訓練
for r = 1:30
E(r) = 0;% 統計誤差
for m = 1:1600
% 資訊的正向流動
x = trainInput(:,m);
% 隱含層的輸出
for j = 1:hiddenNum
hidden(j,:) = w1(:,j)'*x+b1(j,:);
hiddenOutput(j,:) = g(hidden(j,:));
end
% 輸出層的輸出
outputOutput = w2'*hiddenOutput+b2;
% 計算誤差
e = trainOutput(m,:)'-outputOutput;
E(r) = E(r) + sum(abs(e));
% 修改權重和偏置
% 隱含層到輸出層的權重和偏置調整
dw2 = hiddenOutput*e';
db2 = e;
% 輸入層到隱含層的權重和偏置調整
for j = 1:hiddenNum
partOne(j) = hiddenOutput(j)*(1-hiddenOutput(j));
partTwo(j) = w2(j,:)*e;
end
for i = 1:inputNum
for j = 1:hiddenNum
dw1(i,j) = partOne(j)*x(i,:)*partTwo(j);
db1(j,:) = partOne(j)*partTwo(j);
end
end
w1 = w1 + yita*dw1;
w2 = w2 + yita*dw2;
b1 = b1 + yita*db1;
b2 = b2 + yita*db2;
end
end
%% 語音特徵訊號分類
testInput=mapminmax('apply',testCharacter',inputps);
for m = 1:400
for j = 1:hiddenNum
hiddenTest(j,:) = w1(:,j)'*testInput(:,m)+b1(j,:);
hiddenTestOutput(j,:) = g(hiddenTest(j,:));
end
outputOfTest(:,m) = w2'*hiddenTestOutput+b2;
end
%% 結果分析
%根據網路輸出找出資料屬於哪類
for m=1:400
output_fore(m)=find(outputOfTest(:,m)==max(outputOfTest(:,m)));
end
%BP網路預測誤差
error=output_fore-output1(n(1601:2000))';
k=zeros(1,4);
%找出判斷錯誤的分類屬於哪一類
for i=1:400
if error(i)~=0
[b,c]=max(testOutput(i,:));
switch c
case 1
k(1)=k(1)+1;
case 2
k(2)=k(2)+1;
case 3
k(3)=k(3)+1;
case 4
k(4)=k(4)+1;
end
end
end
%找出每類的個體和
kk=zeros(1,4);
for i=1:400
[b,c]=max(testOutput(i,:));
switch c
case 1
kk(1)=kk(1)+1;
case 2
kk(2)=kk(2)+1;
case 3
kk(3)=kk(3)+1;
case 4
kk(4)=kk(4)+1;
end
end
%正確率
rightridio=(kk-k)./kk 啟用函式
%% 啟用函式
function [ y ] = g( x )
y = 1./(1+exp(-x));
end