
條件隨機場(2)——概率計算
1.CRF簡化表示
先回顧一下線性鏈CRF引數化形式
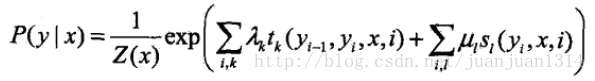
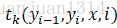
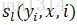
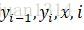
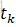
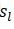
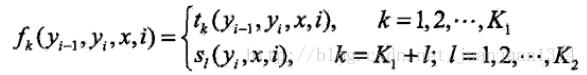
其中,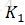
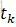
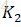
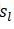
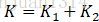
用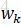
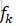
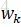
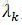
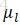
所以,CRF的形式可簡化為
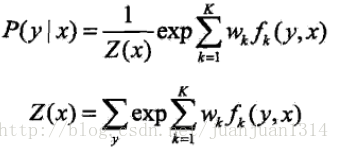
對轉移特徵和狀態特徵在各位置i求和
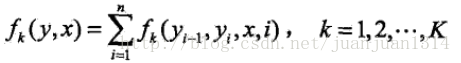
將權重集合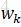
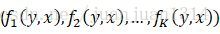
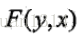
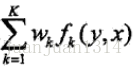
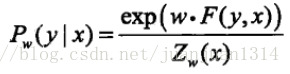
其中
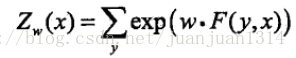
這裡,剛開始有點懵的是,前一篇舉例計算條件概率時,Y序列有5個節點,2個取值,轉移特徵一共有16個,狀態特徵有9個,條件概率的分子一共有9項相加(轉移特徵5-1項,狀態特徵5項),而這裡,w∙F(y,x)一共有K項,相當於例子中的16+9項,這就對不上了呀!
後來終於注意到
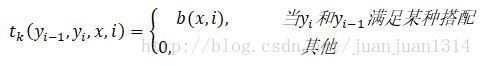
而
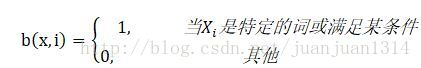
不滿足條件的項就是0,而對於
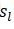 ,那種和當前狀態不滿足的,可能權重會變得接近於0.這樣一來,兩個計算方式就不衝突了。
,那種和當前狀態不滿足的,可能權重會變得接近於0.這樣一來,兩個計算方式就不衝突了。
2. CRF矩陣表示
CRF計算公式也可表示為
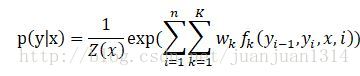
令
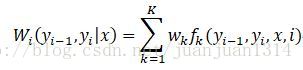
則
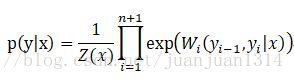
令
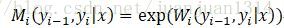
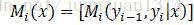
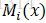
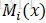
CRF可表示為
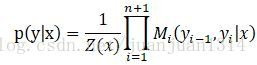
這裡序列取n+1個,實際上是給序列添加了start和stop標誌後,序列結點個數實際上上n+2,從0到n+1。
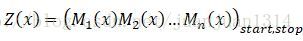
Z(x)表示從start到stop整個序列的所有路徑的概率和,p(y│x)表示從start到stop某條路徑的概率(看到這裡才理解p(y│x)所表示的含義)。Z(x)為規範化因子。
依然用上一篇的例子,
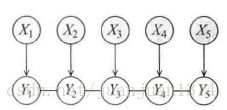
圖1

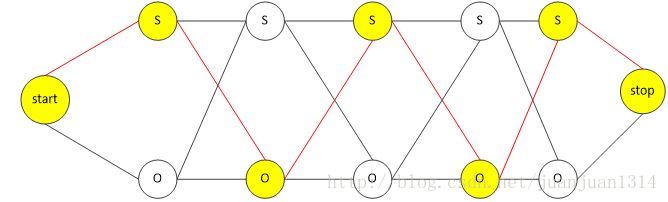
圖2
而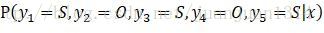
3.概率的計算方式
從
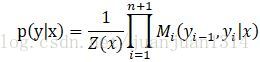
由於序列的遞推關係,從前往後推,到位置i,i位置為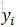
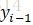
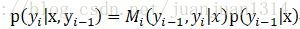
同時,從圖1可以看出,Y的各節點之間是無向的,也就是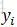
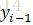
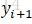
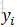
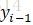
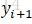
因此,引入前向後-後向演算法,前向演算法計算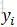
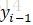
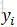
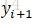
以標註序列為例,p(y|x)是整個序列的概率,而實際標註過程中,每個位置上Y的可能取值的概率才是決定每個位置該標註為哪一個值的關鍵。我們的計算目標更多在於
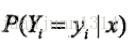
而根據前面的依賴關係,要計算位置i為
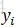 的概率,需要先計算位置i-1和i+1各可能標註值的概率,所以,還需要計算
的概率,需要先計算位置i-1和i+1各可能標註值的概率,所以,還需要計算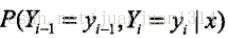 (將此公式中i替換為i+1就是
(將此公式中i替換為i+1就是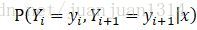 )
)
在前向演算法中,定義
對每個指標i=0,1,2,…,n+1定義前向向量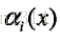
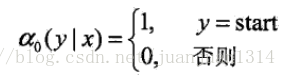
遞推公式
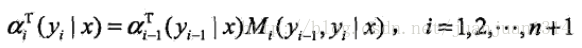
又可表示為
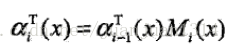
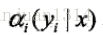
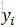
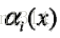
同樣,定義後向向量為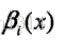
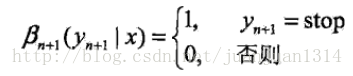
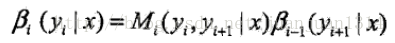
又可表示為
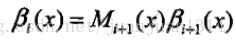
根據土遞推關係,start和stop之間所有路徑的概率和,實際上就是從start往stop推,第n位置的所有取值的概率和,因為序列最後一個包含全部可能取值,那麼前面位置的所有可能全部包含在內,同理,也等同於從stop往後推,推到start,位置1的所有可能取值的概率和等同於start和stop之間的所有路徑概率和。因此
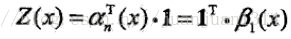
計算位置i-1和i的條件概率為
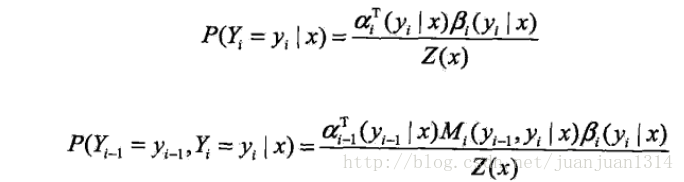
4.期望計算
在學習引數時,需要用到轉移特徵的期望和狀態特徵的期望,前面已經把轉移和狀態兩特徵函式統一成特徵函式,所以,除了計算概率,還得計算特徵函式的期望。
特徵函式f_k關於條件分佈P(Y|X)的數學期望是
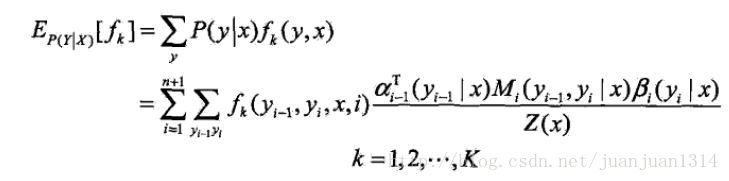
假設經驗分佈為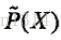
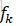
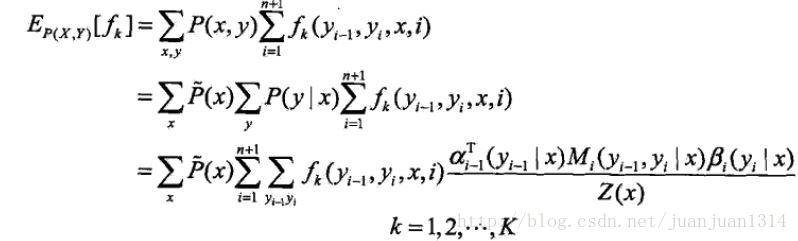
其中
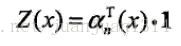
最重要的計算公式是第i和i-1位置的條件概率計算和特徵函式的兩個期望計算,前者在學習和預測時都要用到,後者主要用在學習引數。在學習引數,計算梯度時,需用實際的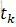
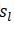
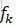
參考資料
《統計學習方法》
《統計自然語言處理》