
Golang效能調優(go-torch, go tool pprof)
Go語言已經為開發者內建配套了很多效能調優監控的好工具和方法,這大大提升了我們profile分析的效率。此外本文還將重點介紹和推薦uber開源的go-torch,其生成的火焰圖更方便更直觀的幫我們進行效能調優。我也是在實際一次的效能調優中,接觸到go-torch,非常棒。
go tool pprof簡介
Golang內建cpu, mem, block profiler
Go強大之處是它已經在語言層面集成了profile取樣工具,並且允許我們在程式的執行時使用它們,使用Go的profiler我們能獲取以下的樣本資訊:
- cpu profiles
- mem profiles
- block profile
Golang常見的profiling使用場景
基準測試檔案:例如使用命令go test . -bench . -cpuprofile prof.cpu生成取樣檔案後,再通過命令 go tool pprof [binary] prof.cpu 來進行分析。
import _ net/http/pprof:如果我們的應用是一個web服務,我們可以在http服務啟動的程式碼檔案(eg: main.go)新增 import _ net/http/pprof,這樣我們的服務 便能自動開啟profile功能,有助於我們直接分析取樣結果。
通過在程式碼裡面呼叫runtime.StartCPUProfile或者runtime.WriteHeapProfile等內建方法,即可方便的進行資料取樣。
go tool pprof的使用方法
go tool pprof的引數很多,不做詳細介紹,自己help看看。在這裡,我主要用到的命令為:
go tool pprof --seconds 25 http://localhost:9090/debug/pprof/profile
命令中,設定了25s的取樣時間,當25s取樣結束後,就生成了我們想要的profile檔案,然後在pprof互動命令列中輸入web,從瀏覽器中開啟,就能看到對應的整個呼叫鏈的效能樹形圖。
[email protected]:~/# go tool pprof -h
usage: pprof [options] [binary] <profile source> ...
Output format (only set one):
-callgrind Outputs go-torch簡介
go-torch是Uber公司開源的一款針對Golang程式的火焰圖生成工具,能收集 stack traces,並把它們整理成火焰圖,直觀地程式給開發人員。go-torch是基於使用BrendanGregg建立的火焰圖工具生成直觀的影象,很方便地分析Go的各個方法所佔用的CPU的時間。
go-torch的具體使用參加如下help資訊,在這裡,我們主要使用到-u和-t引數:
go-torch -u http://localhost:9090 -t 30
[email protected]:~/# go-torch -h
Usage:
go-torch [options] [binary] <profile source>
pprof Options:
-u, --url= Base URL of your Go program (default: http://localhost:8080)
-s, --suffix= URL path of pprof profile (default: /debug/pprof/profile)
-b, --binaryinput= File path of previously saved binary profile. (binary profile is anything accepted by https://golang.org/cmd/pprof)
--binaryname= File path of the binary that the binaryinput is for, used for pprof inputs
-t, --seconds= Number of seconds to profile for (default: 30)
--pprofArgs= Extra arguments for pprof
Output Options:
-f, --file= Output file name (must be .svg) (default: torch.svg)
-p, --print Print the generated svg to stdout instead of writing to file
-r, --raw Print the raw call graph output to stdout instead of creating a flame graph; use with Brendan Gregg's flame graph perl script (see
https://github.com/brendangregg/FlameGraph)
--title= Graph title to display in the output file (default: Flame Graph)
--width= Generated graph width (default: 1200)
--hash Colors are keyed by function name hash
--colors= set color palette. choices are: hot (default), mem, io, wakeup, chain, java, js, perl, red, green, blue, aqua, yellow, purple, orange
--cp Use consistent palette (palette.map)
--reverse Generate stack-reversed flame graph
--inverted icicle graph
Help Options:
-h, --help Show this help message環境準備
安裝FlameGraph指令碼
git clone https://github.com/brendangregg/FlameGraph.git
cp flamegraph.pl /usr/local/bin在終端輸入 flamegraph.pl -h 是否安裝FlameGraph成功:
$ flamegraph.pl -h
Option h is ambiguous (hash, height, help)
USAGE: /usr/local/bin/flamegraph.pl [options] infile > outfile.svg
--title # change title text
--width # width of image (default 1200)
--height # height of each frame (default 16)
--minwidth # omit smaller functions (default 0.1 pixels)
--fonttype # font type (default "Verdana")
--fontsize # font size (default 12)
--countname # count type label (default "samples")
--nametype # name type label (default "Function:")
--colors # set color palette. choices are: hot (default), mem, io,
# wakeup, chain, java, js, perl, red, green, blue, aqua,
# yellow, purple, orange
--hash # colors are keyed by function name hash
--cp # use consistent palette (palette.map)
--reverse # generate stack-reversed flame graph
--inverted # icicle graph
--negate # switch differential hues (blue<->red)
--help # this message
eg,
/usr/local/bin/flamegraph.pl --title="Flame Graph: malloc()" trace.txt > graph.svg安裝go-torch
有了flamegraph的支援,我們接下來要使用go-torch展示profile的輸出:
go get -v github.com/uber/go-torchDemo
啟動待調優的程式
在我的例項中,是一個簡單的web Demo,go run main.go -printStats啟動之後,瀏覽器能正常訪問待調優的介面: http://localhost:9090/demo。每次該介面的訪問,都會列印訪問資訊,如下所示:
[email protected]:/# go run main.go -printStats
Starting Server on :9090
IncCounter: handler.received.garnett.advance.no-os.no-browser = 1
IncCounter: handler.received.garnett.advance.no-os.no-browser = 1
RecordTimer: handler.latency.garnett.advance.no-os.no-browser = 67.984µs
IncCounter: handler.received.garnett.advance.no-os.no-browser = 1
RecordTimer: handler.latency.garnett.advance.no-os.no-browser = 339.656µs
IncCounter: handler.received.garnett.advance.no-os.no-browser = 1
RecordTimer: handler.latency.garnett.advance.no-os.no-browser = 55.749µs
IncCounter: handler.received.garnett.advance.no-os.no-browser = 1
RecordTimer: handler.latency.garnett.advance.no-os.no-browser = 89.34µs
IncCounter: handler.received.garnett.advance.no-os.no-browser = 1
RecordTimer: handler.latency.garnett.advance.no-os.no-browser = 59.606µs
IncCounter: handler.received.garnett.advance.no-os.no-browser = 1
RecordTimer: handler.latency.garnett.advance.no-os.no-browser = 47.917µs
IncCounter: handler.received.garnett.advance.no-os.no-browser = 1
RecordTimer: handler.latency.garnett.advance.no-os.no-browser = 42.768µs
IncCounter: handler.received.garnett.advance.no-os.no-browser = 1
RecordTimer: handler.latency.garnett.advance.no-os.no-browser = 1.270416ms
IncCounter: handler.received.garnett.advance.no-os.no-browser = 1
RecordTimer: handler.latency.garnett.advance.no-os.no-browser = 34.518µs
IncCounter: handler.received.garnett.advance.no-os.no-browser = 1
RecordTimer: handler.latency.garnett.advance.no-os.no-browser = 281.014µs啟動壓力測試
接下來,我們對該介面進行壓力測試,看看它在大併發情況下的效能表現。
我們使用go-wrk工具進行試壓,go-wrk的安裝請前往github官網https://github.com/adjust/go-wrk,只要把程式碼clone下來go build一下即可。
執行如下命令,進行35s 1W次高併發場景模擬:
go-wrk -d 35 -n 10000 http://localhost:9090/demo
使用go tool pprof
在上面的壓測過程中,我們再新建一個終端視窗輸入以下命令,生成我們的profile檔案:
go tool pprof --seconds 25 http://localhost:9090/debug/pprof/profile命令中,我們設定了25秒的取樣時間,當看到(pprof)的時候,我們輸入 web, 表示從瀏覽器開啟,可見下圖:
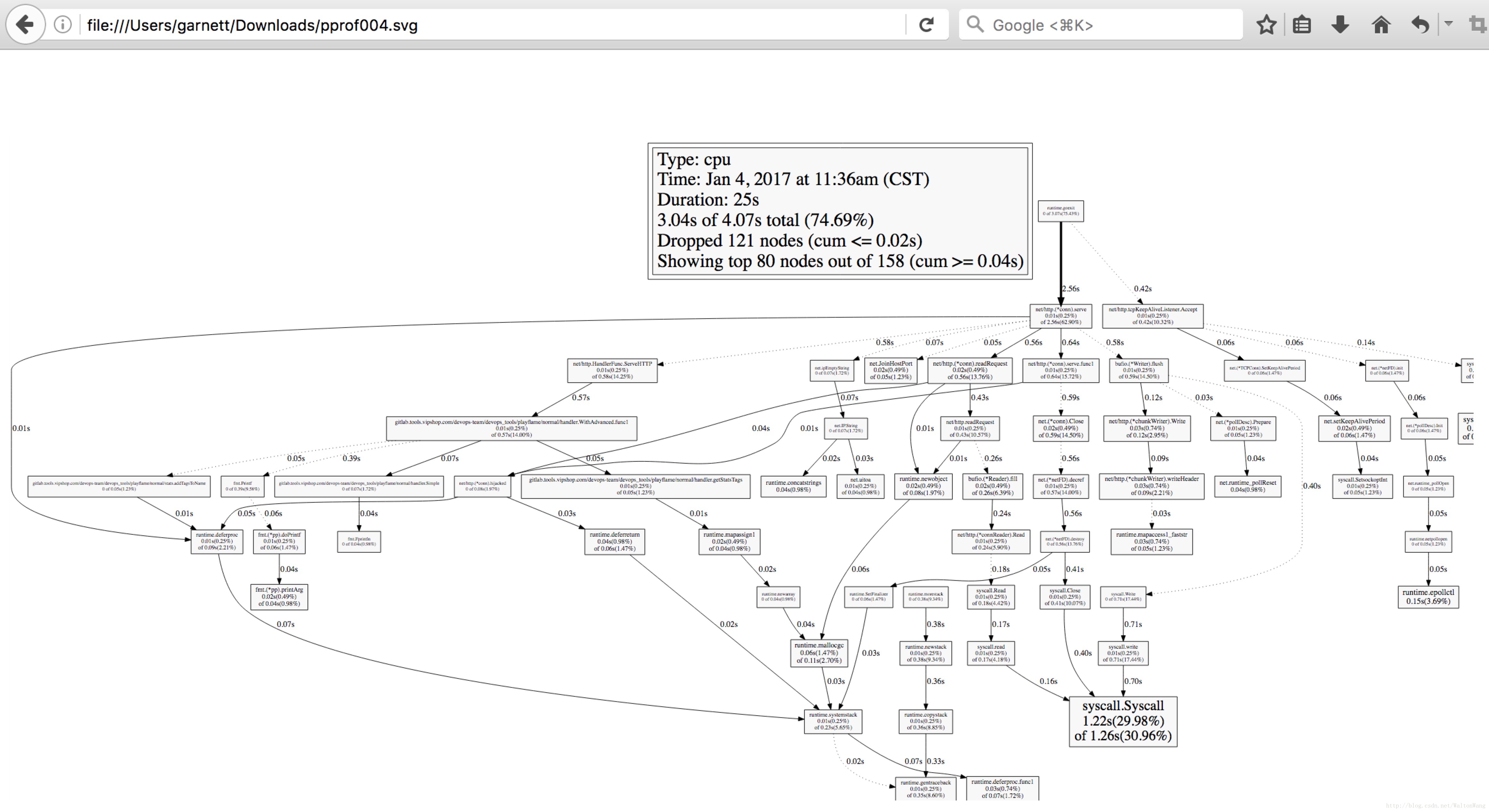
看到這個圖,你可能已經懵逼了。在我這個簡單的Demo中,已經這麼難看了,更何況在實際的效能調優中呢!
使用go-torch
在上面的壓測過程中,這次我們使用go-torch來生成取樣報告:
go-torch -u http://localhost:9090 -t 3030s後,go-torch完成取樣,輸出以下資訊:
Writing svg to torch.svgtorch.svg是go-torch取樣結束後自動生成的profile檔案,我們也用瀏覽器開啟,可見下圖:
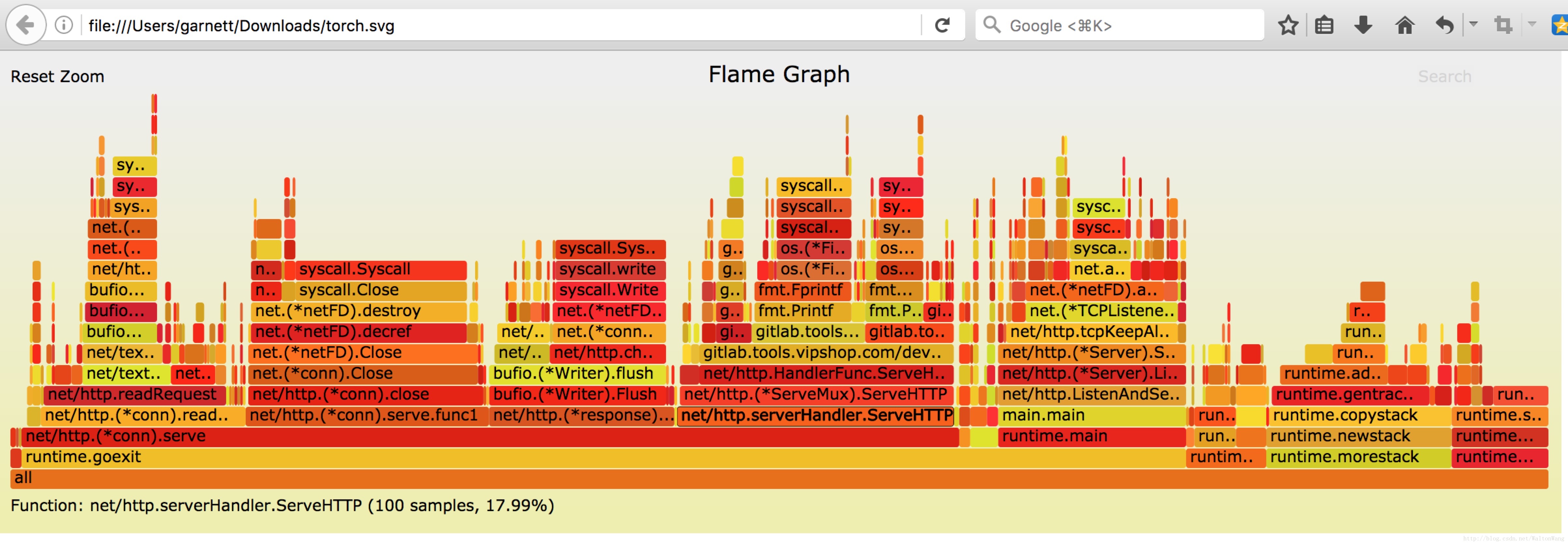
這就是go-torch生成的火焰圖,看起來是不是舒服多了。
火焰圖的y軸表示cpu呼叫方法的先後,x軸表示在每個取樣呼叫時間內,方法所佔的時間百分比,越寬代表佔據cpu時間越多
有了火焰圖,我們就可以更清楚的看到哪個方法呼叫耗時長了,然後不斷的修正程式碼,重新取樣,不斷優化。
好了,本文只有一個目的,就是希望讓你對golang程式的效能調優更有興趣。接下來,你可以在自己的golang專案中對那些耗時太長的介面進行調優了。
相關推薦
Golang效能調優(go-torch, go tool pprof)
Go語言已經為開發者內建配套了很多效能調優監控的好工具和方法,這大大提升了我們profile分析的效率。此外本文還將重點介紹和推薦uber開源的go-torch,其生成的火焰圖更方便更直觀的幫我們進行效能調優。我也是在實際一次的效能調優中,接觸到go-torch
golang 效能調優分析工具 pprof(下)
[golang 效能調優分析工具 pprof(上)篇](https://www.cnblogs.com/jiujuan/p/14588185.html), 這是下篇。 ## 四、net/http/pprof ### 4.1 程式碼例子 1 > go version go1.13.9 把上面的程式例子稍
Go語言HTTP測試及程式效能調優
這篇要講的東西,主要是HTTP,WebSocket的測試及如何調優Go程式的一些方法. 分下面幾個內容: 一.httptest測試包 二.效能測試 三.怎麼利用引數分析和調優程式四.在執行中實時監控調優 一.httptest測試包 對於HTTP和WebS
Golang 的 協程排程機制 與 GOMAXPROCS 效能調優
作者:林冠巨集 / 指尖下的幽靈 前序 正確地認識 G , M , P 三者的關係,能夠對協程的排程機制有更深入的理解! 本文將會完整介紹完 go 協程的排程機制,包含: 排程物件的主要組成 各物件的關係 與 分工 gorutine 協程是如何被執行的 核心執行緒 sysmon 對 goru
1.效能調優概覽
介紹 Optimization Overview 優化概述 Optimizing SQL Statements 優化SQL語句 Optimization and Indexes 優化和索引 Optimizing Database Structure 優化資料庫結
深入理解Java虛擬機器總結一虛擬機器效能監控工具與效能調優(三)
深入理解Java虛擬機器總結一虛擬機器效能監控工具與效能調優(三) JDK的命令列工具 JDK的視覺化工具 效能調優 JDK的命令列工具 主要有以下幾種: jps (Java Process Status Tool): 虛擬機器程序
【Big Data 每日一題】Spark開發效能調優總結
1. 分配資源調優 Spark效能調優的王道就是分配資源,即增加和分配更多的資源對效能速度的提升是顯而易見的,基本上,在一定範圍之內,增加資源與效能的提升是成正比的,當公司資源有限,能分配的資源達到頂峰之後,那麼才去考慮做其他的調優 如何分配及分配哪些資源 在生產環境中,提交spark作
nkv客戶端效能調優
此文已由作者張洪簫授權網易雲社群釋出。 歡迎訪問網易雲社群,瞭解更多網易技術產品運營經驗。 問題描述 隨著考拉業務的增長和規模的擴大,很多的應用都開始重度依賴快取服務,也就是杭研的nkv。但是在使用過程中,發現服務端壓力並不是特別大的情況下,客戶端的rt卻很高,導致應用在到達一定併發的情況下,服務的質量下降的
ifeve.com 南方《JVM 效能調優實戰之:使用阿里開源工具 TProfiler 在海量業務程式碼中精確定位效能程式碼》
https://blog.csdn.net/defonds/article/details/52598018 多次拉取 JStack,發現很多執行緒處於這個狀態: at jrockit/vm/Allocator.getNewTla(JJ)V(Native Method)
實時計算 Flink效能調優
自動配置調優 實時計算 Flink新增自動調優功能autoconf。能夠在流作業以及上下游效能達到穩定的前提下,根據您作業的歷史執行狀況,重新分配各運算元資源和併發數,達到優化作業的目的。更多詳細說明請您參閱自動配置調優。 首次智慧調優 建立一個作業。如何建立作業請參看快速入門。 上線作業
Hadoop效能調優全面總結
一、 Hadoop概述 隨著企業要處理的資料量越來越大,MapReduce思想越來越受到重視。Hadoop是MapReduce的一個開源實現,由於其良好的擴充套件性和容錯性,已得到越來越廣泛的應用。 Hadoop實現了一個分散式檔案系統(Hadoop Distributed File Sys
eclipse效能調優的一次記錄
最近因為學習原因,eclipse中外掛越來越多,造成eclipse一次次假死,著實很影響工作效率和心情,有時正是興起,但是造成短片很令人生氣,如果eclipse卡頓或者假死,在電腦配置較不錯的情況下,不要懷疑自己的電腦,嘗試去除錯一下自己的eclipse。 找到eclipse或
nginx監控與效能調優
監控 nginx有自帶的監控模組,編譯nginx的時候,加上引數 --with-http_stub_status_module #配置指令 ./configure --prefix=/usr/local --user=nginx --group=nginx
Tomcat效能調優以及遠端管理(Tomcat manager與psi-probe監控)
tomcat優化的我用到的幾個點: 1.記憶體優化 2.執行緒優化 docs/config/http.html maxConnections acceptCount(配置的太大是沒有意義的) maxThreads minSpareThreads 最小空閒的工作
MySQL 效能調優技巧
技巧#1:確定MySQL的最大連線數 對於MySQL的最大連線數,一次最好是傳送5個請求到Web伺服器。對Web伺服器的5個請求中的一部分將用於CSS樣式表,影象和指令碼等資源。由於諸如瀏覽器快取等原因,要獲得準確的MySQL到Web伺服器的請求比率可能很困難; 要想得到一個確切的數字,就需要分
Tomcat8 效能調優
1.優化Linux核心及TCP連線 編輯系統配置檔案: vim /etc/sysctl.conf 修改內容如下: 配置 說明 fs.file-max = 655350 系統檔案描述符
JVM效能調優監控工具jps、jstack、jstat、jmap、jinfo使用
現實企業級Java開發中,有時候我們會碰到下面這些問題: OutOfMemoryError,記憶體不足 記憶體洩露 執行緒死鎖 鎖爭用(Lock Contention) Java程序消耗CPU過高 ...... &n
Spark之效能調優總結(一)
總結一下spark的調優方案: 一、效能調優 1、效能上的調優主要注重一下幾點: Excutor的數量 每個Excutor所分配的CPU的數量 每個Excutor所能分配的記憶體量 Driver端分配的記憶體數量 2、如何分配資源 在生產環境中,
Nginx效能調優之快取記憶體
Nginx可以快取一些檔案(一般是靜態檔案),減少Nginx與後端伺服器的IO,提高使用者訪問速度。而且當後端伺服器宕機時,Nginx伺服器能給出相應的快取檔案響應相關的使用者請求。 一 Nginx靜態快取基本配置 在tomcat的webapps目錄下建立hello.html,內容
第一章 Java效能調優概述
效能概述 看懂程式的效能 一般來說,程式的效能能通過以下幾個方面來表現: 執行速度:程式的反映是否迅速,響應時間是否足夠短 記憶體分配:記憶體分配是否合理,是否過多地消耗記憶體或者存在洩漏 啟動時間:程式從執行到可以正常處理業務需要花費多長時間 負責承受能力:當系統壓力上升時,系統的執