
GA遺傳演算法入門到掌握
遺傳演算法的有趣應用很多,諸如尋路問題,8數碼問題,囚犯困境,動作控制,找圓心問題(這是一個國外網友的建議:在一個不規則的多邊形 中,尋找一個包含在該多邊形內的最大圓圈的圓心。),TSP問題(在以後的章節裡面將做詳細介紹。),生產排程問題,人工生命模擬等。直到最後看到一個非 常有趣的比喻,覺得由此引出的袋鼠跳問題(暫且這麼叫它吧),既有趣直觀又直達遺傳演算法的本質,確實非常適合作為初學者入門的例子。
問題的提出與解決方案
讓我們先來考慮考慮下面這個問題的解決辦法。
已知一元函式:
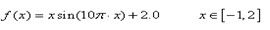
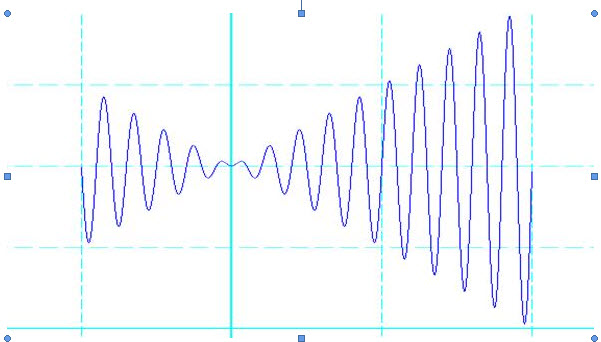
現在要求在既定的區間內找出函式的最大值
極大值、最大值、區域性最優解、全域性最優解
在解決上面提出的問題之前我們有必要先澄清幾個以後將常常會碰到的概念:極 大值、最大值、區域性最優解、全域性最優解。學過高中數學的人都知道極大值在一個小鄰域裡面左邊的函式值遞增,右邊的函式值遞減,在圖2.1裡面的表現就是一 個“山峰”。當然,在圖上有很多個“山峰”,所以這個函式有很多個極大值。而對於一個函式來說,最大值就是在所有極大值當中,最大的那個。所以極大值具有區域性性,而最大值則具有全域性性。
因為遺傳演算法中每一條染色體,對應著遺傳演算法的一個 解決方案,一般我們用適應性函式(fitness function)來衡量這個解決方案的優劣。所以從一個基因組到其解的適應度形成一個對映。所以也可以把遺傳演算法的過程看作是一個在多元函式裡面求最優解的過程。在這個多維曲面裡面也有數不清的“山峰”,而這些最優解所對應的就是區域性最優解。而其中也會有一個“山峰”的海拔最高的,那麼這個就是全域性最優 解。而遺傳演算法的任務就是儘量爬到最高峰,而不是陷落在一些小山峰。(另外,值得注意的是遺傳演算法不一定要找“最高的山峰”,如果問題的適應度評價越小越好的話,那麼全域性最優解就是函式的最小值,對應的,遺傳演算法所要找的就是“最深的谷底”)如果至今你還不太理解的話,那麼你先往下看。本章的示例程式將會 非常形象的表現出這個情景。
“袋鼠跳”問題
既然我們把 函式曲線理解成一個一個山峰和山谷組成的山脈。那麼我們可以設想所得到的每一個解就是一隻袋鼠,我們希望它們不斷的向著更高處跳去,直到跳到最高的山峰(儘管袋鼠本身不見得願意那麼做)。所以求最大值的過程就轉化成一個“袋鼠跳”的過程。下面介紹介紹“袋鼠跳”的幾種方式。
爬山法、模擬退火和遺傳演算法
解決尋找最大值問題的幾種常見的演算法:
1. 爬山法(最速上升爬山法):
從搜尋空間中隨機產生鄰近的點,從中選擇對應解最優的個體,替換原來的個體,不斷 重複上述過程。因為只對“鄰近”的點作比較,所以目光比較“短淺”,常常只能收斂到離開初始位置比較近的區域性最優解上面。對於存在很多區域性最優點的問題,通過一個簡單的迭代找出全域性最優解的機會非常渺茫。(在爬山法中,袋鼠最有希望到達最靠近它出發點的山頂,但不能保證該山頂是珠穆朗瑪峰,或者是一個非常 高的山峰。因為一路上它只顧上坡,沒有下坡。)
2. 模擬退火:
這個方法來自金屬熱加工過程的啟發。在金屬熱加工過程中,當金屬的溫度超過它的熔點(Melting Point)時,原子就會激烈地隨機運動。與所有的其它的物理系統相類似,原子的這種運動趨向於尋找其能量的極小狀態。在這個能量的變遷過程中,開始時。溫度非常高, 使得原子具有很高的能量。隨著溫度不斷降低,金屬逐漸冷卻,金屬中的原子的能量就越來越小,最後達到所有可能的最低點。利用模擬退火的時候,讓演算法從較大的跳躍開始,使到它有足夠的“能量”逃離可能“路過”的區域性最優解而不至於限制在其中,當它停在全域性最優解附近的時候,逐漸的減小跳躍量,以便使其“落腳 ”到全域性最優解上。(在模擬退火中,袋鼠喝醉了,而且隨機地大跳躍了很長時間。運氣好的話,它從一個山峰跳過山谷,到了另外一個更高的山峰上。但最後,它漸漸清醒了並朝著它所在的峰頂跳去。)
3. 遺傳演算法:
模擬物競天擇的生物進化過程,通過維護一個潛在解的群體執行了多方向的搜尋,並支援這些方向上的資訊構成和交換。以面為單位的搜尋,比以點為單位的搜尋,更能發現全域性最優解。(在遺傳演算法中,有很多袋鼠,它們降落到喜瑪拉雅山脈的任意地方。這些袋鼠並不知道它們的任務是尋找珠穆朗瑪峰。但每過幾年,就在一些海拔高度較低的地方射殺一些袋鼠,並希望存活下來的袋鼠是多產的,在它們所處的地方生兒育女。)(後來,一個叫天行健的網遊給我想了一個更恰切的故事:從前,有一大群袋鼠,它們被莫名其妙的零散地遺棄於喜馬拉雅山脈。於是只好在那裡艱苦的生活。海拔 低的地方瀰漫著一種無色無味的毒氣,海拔越高毒氣越稀薄。可是可憐的袋鼠們對此全然不覺,還是習慣於活蹦亂跳。於是,不斷有袋鼠死於海拔較低的地方,而越是在海拔高的袋鼠越是能活得更久,也越有機會生兒育女。就這樣經過許多年,這些袋鼠們竟然都不自覺地聚攏到了一個個的山峰上,可是在所有的袋鼠中,只有聚 攏到珠穆朗瑪峰的袋鼠被帶回了美麗的澳洲。)
下面主要介紹介紹遺傳演算法實現的過程。
遺傳演算法的實現過程
遺傳演算法的實現過程實際上就像自然界的進化過程那樣。首先尋找一種對問題潛在解進行“數字化”編碼的方案。(建立表現型和基因型的對映關係。)然後用隨機 數初始化一個種群(那麼第一批袋鼠就被隨意地分散在山脈上。),種群裡面的個體就是這些數字化的編碼。接下來,通過適當的解碼過程之後,(得到袋鼠的位置 座標。)用適應性函式對每一個基因個體作一次適應度評估。(袋鼠爬得越高,越是受我們的喜愛,所以適應度相應越高。)用選擇函式按照某種規定擇優選 擇。(我們要每隔一段時間,在山上射殺一些所在海拔較低的袋鼠,以保證袋鼠總體數目持平。)讓個體基因交叉變異。(讓袋鼠隨機地跳一跳)然後產生子 代。(希望存活下來的袋鼠是多產的,並在那裡生兒育女。)遺傳演算法並不保證你能獲得問題的最優解,但是使用遺傳演算法的最大優點在於你不必去了解和操心如何 去“找”最優解。(你不必去指導袋鼠向那邊跳,跳多遠。)而只要簡單的“否定”一些表現不好的個體就行了。(把那些總是愛走下坡路的袋鼠射殺。)以後你會 慢慢理解這句話,這是遺傳演算法的精粹!所以我們總結出遺傳演算法的一般步驟:
開始迴圈直至找到滿意的解。
1.評估每條染色體所對應個體的適應度。
2.遵照適應度越高,選擇概率越大的原則,從種群中選擇兩個個體作為父方和母方。
3.抽取父母雙方的染色體,進行交叉,產生子代。
4.對子代的染色體進行變異。
5.重複2,3,4步驟,直到新種群的產生。
結束迴圈。
接下來,我們將詳細地剖析遺傳演算法過程的每一個細節。
編制袋鼠的染色體----基因的編碼方式
通過前一章的學習,讀者已經瞭解到人類染色體的編碼符號集,由4種鹼基的兩種配合組成。共有4種情況,相當於2 bit的資訊量。這是人類基因的編碼方式,那麼我們使用遺傳演算法的時候編碼又該如何處理呢?
受到人類染色體結構的啟發,我們可以設想一下,假設目前只有“0”,“1”兩種鹼基,我們也用一條鏈條把他們有序的串連在一起,因為每一個單位都能表現出 1 bit的資訊量,所以一條足夠長的染色體就能為我們勾勒出一個個體的所有特徵。這就是二進位制編碼法,染色體大致如下:
010010011011011110111110
上面的編碼方式雖然簡單直觀,但明顯地,當個體特徵比較複雜的時候,需要大量的編碼才能精確地描述,相應的解碼過程(類似於生物學中的DNA翻譯過程,就是把基因型對映到表現型的過程。)將過份繁複,為改善遺傳演算法的計算複雜性、提高運算效率,提出了浮點數編碼。染色體大致如下:
1.2 – 3.3 – 2.0 –5.4 – 2.7 – 4.3
那麼我們如何利用這兩種編碼方式來為袋鼠的染色體編碼呢?因為編碼的目的是建立表現型到基因型的對映關係,而表現型一般就被理解為個體的特徵。比如人的基因型是46條染色體所描述的(總長度 兩 米的紙條?),卻能解碼成一個個眼,耳,口,鼻等特徵各不相同的活生生的人。所以我們要想為“袋鼠”的染色體編碼,我們必須先來考慮“袋鼠”的“個體特徵”是什麼。也許有的人會說,袋鼠的特徵很多,比如性別,身長,體重,也許它喜歡吃什麼也能算作其中一個特徵。但具體在解決這個問題的情況下,我們應該進 一步思考:無論這隻袋鼠是長短,肥瘦,只要它在低海拔就會被射殺,同時也沒有規定身長的袋鼠能跳得遠一些,身短的袋鼠跳得近一些。當然它愛吃什麼就更不相關了。我們由始至終都只關心一件事情:袋鼠在哪裡。因為只要我們知道袋鼠在那裡,我們就能做兩件必須去做的事情:
(1)通過查閱喜瑪拉雅山脈的地圖來得知袋鼠所在的海拔高度(通過自變數求函式值。)以判斷我們有沒必要把它射殺。
(2)知道袋鼠跳一跳後去到哪個新位置。
如 果我們一時無法準確的判斷哪些“個體特徵”是必要的,哪些是非必要的,我們常常可以用到這樣一種思維方式:比如你認為袋鼠的愛吃什麼東西非常必要,那麼你就想一想,有兩隻袋鼠,它們其它的個體特徵完全同等的情況下,一隻愛吃草,另外一隻愛吃果。你會馬上發現,這不會對它們的命運有絲毫的影響,它們應該有同 等的概率被射殺!只因它們處於同一個地方。(值得一提的是,如果你的基因編碼設計中包含了袋鼠愛吃什麼的資訊,這其實不會影響到袋鼠的進化的過程,而那隻攀到珠穆朗瑪峰的袋鼠吃什麼也完全是隨機的,但是它所在的位置卻是非常確定的。)
以上是對遺傳演算法編碼過程中經常經歷的思維過程,必須把具體問題抽象成數學模型,突出主要矛盾,捨棄次要矛盾。只有這樣才能簡潔而有效的解決問題。希望初學者仔細琢磨。
既然確定了袋鼠的位置作為個體特徵,具體來說位置就 是橫座標。那麼接下來,我們就要建立表現型到基因型的對映關係。就是說如何用編碼來表現出袋鼠所在的橫座標。由於橫座標是一個實數,所以說透了我們就是要對這個實數編碼。回顧我們上面所介紹的兩種編碼方式,讀者最先想到的應該就是,對於二進位制編碼方式來說,編碼會比較複雜,而對於浮點數編碼方式來說,則會 比較簡潔。恩,正如你所想的,用浮點數編碼,僅僅需要一個浮點數而已。而下面則介紹如何建立二進位制編碼到一個實數的對映。
明顯地,一定長度的二進位制編碼序列,只能表示一定精度的浮點數。譬如我們要求解精確到六位小數,由於區間長度為2 – (-1) = 3 ,為了保證精度要求,至少把區間[-1,2]分為3 × 106等份。又因為
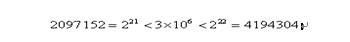
所以編碼的二進位制串至少需要22位。
把一個二進位制串(b0,b1,....bn)轉化位區間裡面對應的實數值通過下面兩個步驟。
(1)將一個二進位制串代表的二進位制數轉化為10進位制數:
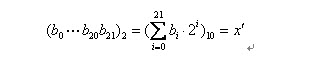
(2)對應區間內的實數:
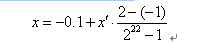
例如一個二進位制串<1000101110110101000111>表示實數值0.637197。
二進位制串<0000000000000000000000>和<1111111111111111111111>則分別表示區間的兩個端點值-1和2。
由於往下章節的示例程式幾乎都只用到浮點數編碼,所以這個“袋鼠跳”問題的解決方案也是採用浮點數編碼的。往下的程式示例(包括裝載基因的類,突變函式)都是針對浮點數編碼的。(對於二進位制編碼這裡只作簡單的介紹,不過這個“袋鼠跳”完全可以用二進位制編碼來解決的,而且更有效一些。所以讀者可以自己嘗試用 二進位制編碼來解決。)
我們定義一個類作為袋鼠基因的載體。(細心的人會提 出這樣的疑問:為什麼我用浮點數的容器來儲藏袋鼠的基因呢?袋鼠的基因不是隻用一個浮點數來表示就行嗎?恩,沒錯,事實上對於這個例項,我們只需要用上一個浮點數就行了。我們這裡用上容器是為了方便以後利用這些程式碼處理那些編碼需要一串浮點數的問題。)
[cpp] view plain copy print?- class Genome
- {
- public:
- friendclass GenAlg;
- friendclass GenEngine;
- Genome():fitness(0){}
- Genome(vector <double> vec, double f): vecGenome(vec), fitness(f){} //類的帶引數初始化引數。
- private:
- vector <double> vecGenome; // 裝載基因的容器
- double fitness; //適應度
- };
class Genome
{
public:
friend class GenAlg;
friend class GenEngine;
Genome():fitness(0){}
Genome(vector <double> vec, double f): vecGenome(vec), fitness(f){} //類的帶引數初始化引數。
private:
vector <double> vecGenome; // 裝載基因的容器
double fitness; //適應度
};
好了,目前為止我們把袋鼠的染色體給研究透了,讓我們繼續跟進袋鼠的進化旅程。
物競天擇--適應性評分與及選擇函式。
1.物競――適應度函式(fitness function)
自然界生物競爭過程往往包含兩個方面:生物相互間的搏鬥與及生物與客觀環境的搏鬥過程。但在我們這個例項裡面,你可以想象到,袋鼠相互之間是非常友好的,它們並不需要互相搏鬥以爭取生存的權利。它們的生死存亡更多是取決於你的判斷。因為你要衡量哪隻袋鼠該殺,哪隻袋鼠不該殺,所以你必須制定一個衡量的標準。而對於這個問題,這個衡量的標準比較容易制定:袋鼠所在的海拔高度。(因為你單純地希望袋鼠爬得越高越好。)所以我們直接用袋鼠的海拔高度作為它們的適應性評分。即適應度函式直接返回函式值就行了。
2.天擇――選擇函式(selection)
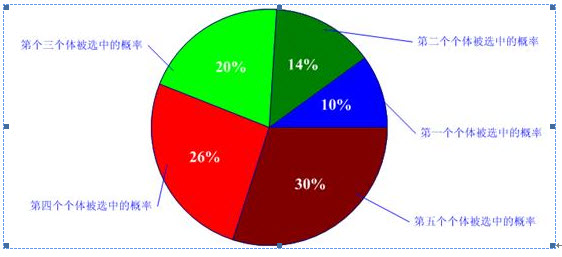
自然界中,越適應的個體就越有可能繁殖後代。但是也不能說適應度越高的就肯定後代越多,只能是從概率上來說更多。(畢竟有些所處海拔高度較低的袋鼠很幸運,逃過了你的眼睛。)那麼我們怎麼來建立這種概率關係呢?下面我們介紹一種常用的選擇方法――輪盤賭(Roulette Wheel Selection)選擇法。假設種群數目,某個個體其適應度為,則其被選中的概率為:
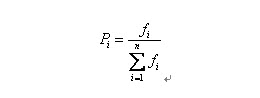
比如我們有5條染色體,他們所對應的適應度評分分別為:5,7,10,13,15。
所以累計總適應度為:
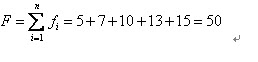
所以各個個體被選中的概率分別為:
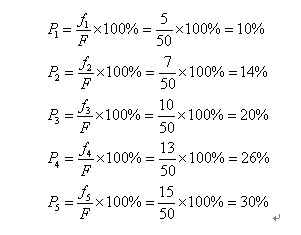
呵呵,有人會問為什麼我們把它叫成輪盤賭選擇法啊?其實你只要看看圖2-2的輪盤就會明白了。這個輪盤是按照各個個體的適應度比例進行分塊的。你可以想象一下,我們轉動輪盤,輪盤停下來的時候,指標會隨機地指向某一個個體所代表的區域,那麼非常幸運地,這個個體被選中了。(很明顯,適應度評分越高的個體被選中的概率越大。)
那麼接下來我們看看如何用程式碼去實現輪盤賭。
[cpp] view plain copy print?- Genome GenAlg:: GetChromoRoulette()
- {
- //產生一個0到人口總適應性評分總和之間的隨機數.
- //中m_dTotalFitness記錄了整個種群的適應性分數總和)
- double Slice = (random()) * totalFitness;
- //這個基因將承載轉盤所選出來的那個個體.
- Genome TheChosenOne;
- //累計適應性分數的和.
- double FitnessSoFar = 0;
- //遍歷總人口裡面的每一條染色體。
- for (int i=0; i<popSize; ++i)
- {
- //累計適應性分數.
- FitnessSoFar += vecPop[i].fitness;
- //如果累計分數大於隨機數,就選擇此時的基因.
- if (FitnessSoFar >= Slice)
- {
- TheChosenOne = vecPop[i];
- break;
- }
- }
- //返回轉盤選出來的個體基因
- return TheChosenOne;
- }
Genome GenAlg:: GetChromoRoulette()
{
//產生一個0到人口總適應性評分總和之間的隨機數.
//中m_dTotalFitness記錄了整個種群的適應性分數總和)
double Slice = (random()) * totalFitness;
//這個基因將承載轉盤所選出來的那個個體.
Genome TheChosenOne;
//累計適應性分數的和.
double FitnessSoFar = 0;
//遍歷總人口裡面的每一條染色體。
for (int i=0; i<popSize; ++i)
{
//累計適應性分數.
FitnessSoFar += vecPop[i].fitness;
//如果累計分數大於隨機數,就選擇此時的基因.
if (FitnessSoFar >= Slice)
{
TheChosenOne = vecPop[i];
break;
}
}
//返回轉盤選出來的個體基因
return TheChosenOne;
}遺傳變異――基因重組(交叉)與基因突變。
應該說這兩個步驟就是使到子代不同於父代的根本原因(注意,我沒有說是子代優於父代的原因,只有經過自然的選擇後,才會出現子代優於父代的傾向。)。對於這兩種遺傳操作,二進位制編碼和浮點型編碼在處理上有很大的差異,其中二進位制編碼的遺傳操作過程,比較類似於自然界裡面的過程,下面將分開講述。
1.基因重組/交叉(recombination/crossover)
(1)二進位制編碼
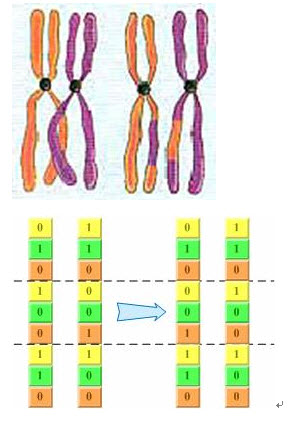
回顧上一章介紹的基因交叉過程:同源染色體聯會的過程中,非姐妹染色單體(分別來自父母雙方)之間常常發生交叉,並且相互交換一部分染色體,如圖2-3。事實上,二進位制編碼的基因交換過程也非常類似這個過程――隨機把其中幾個位於同一位置的編碼進行交換,產生新的個體,如圖2-4所示。
(2)浮點數編碼
如果一條基因中含有 多個浮點數編碼,那麼也可以用跟上面類似的方法進行基因交叉,不同的是進行交叉的基本單位不是二進位制碼,而是浮點數。而如果對於單個浮點數的基因交叉,就有其它不同的重組方式了,比如中間重組:
這樣只要隨機產生就能得到介於父代基因編碼值和母代基因編碼值之間的值作為子代基因編碼的值。
考 慮到“袋鼠跳”問題的具體情況――袋鼠的個體特徵僅僅表現為它所處的位置。可以想象,同一個位置的袋鼠的基因是完全相同的,而兩條相同的基因進行交叉後,相當於什麼都沒有做,所以我們不打算在這個例子裡面使用交叉這一個遺傳操作步驟。(當然硬要這個操作步驟也不是不行的,你可以把兩隻異地的袋鼠捉到一起, 讓它們交配,然後產生子代,再把它們送到它們應該到的地方。)
2.基因突變(Mutation)
(1)二進位制編碼
同樣回顧一下上一章所介紹的基因突變過程:基因突變是染色體的某一個位點上基因的改變。基因突變使一個基因變成它的等位基因,並且通常會引起一定的表現型變化。恩,正如上面所說,二進位制編碼的遺傳操作過程和生物學中的過程非常相類似,基因串上的“ 0”或“ 1”有一定機率變成與之相反的“ 1”或“ 0”。例如下面這串二進位制編碼:
101101001011001
經過基因突變後,可能變成以下這串新的編碼:
001101011011001
(2)浮點型編碼
浮點型編碼的基因突變過程一般是對原來的浮點數增加或者減少一個小隨機數。比如原來的浮點數串如下:
1.2,3.4, 5.1, 6.0, 4.5
變異後,可能得到如下的浮點數串:
1.3,3.1, 4.9, 6.3, 4.4
當 然,這個小隨機數也有大小之分,我們一般管它叫“步長”。(想想“袋鼠跳”問題,袋鼠跳的長短就是這個步長。)一般來說步長越大,開始時進化的速度會比較快,但是後來比較難收斂到精確的點上。而小步長卻能較精確的收斂到一個點上。所以很多時候為了加快遺傳演算法的進化速度,而又能保證後期能夠比較精確地收斂 到最優解上面,會採取動態改變步長的方法。其實這個過程與前面介紹的模擬退火過程比較相類似,讀者可以做簡單的回顧。
下面是針對浮點型編碼的基因突變函式的寫法:
[cpp] view plain copy print?- void GenAlg::Mutate(vector<double> &chromo)
- {
- //遵循預定的突變概率,對基因進行突變
- for (int i=0; i<chromo.size(); ++i)
- {
- //如果發生突變的話
- if (random() < mutationRate)
- {
- //使該權值增加或者減少一個很小的隨機數值
- chromo[i] += ((random()-0.5) * maxPerturbation);
- //保證袋鼠不至於跳出自然保護區.
- if(chromo[i] < leftPoint)
- {
- chromo[i] = rightPoint;
- }
- elseif(chromo[i] > rightPoint)
- {
- chromo[i] = leftPoint;
- }
- //以上程式碼非基因變異的一般性程式碼只是用來保證基因編碼的可行性。
- }
- }
- }
void GenAlg::Mutate(vector<double> &chromo)
{
//遵循預定的突變概率,對基因進行突變
for (int i=0; i<chromo.size(); ++i)
{
//如果發生突變的話
if (random() < mutationRate)
{
//使該權值增加或者減少一個很小的隨機數值
chromo[i] += ((random()-0.5) * maxPerturbation);
//保證袋鼠不至於跳出自然保護區.
if(chromo[i] < leftPoint)
{
chromo[i] = rightPoint;
}
else if(chromo[i] > rightPoint)
{
chromo[i] = leftPoint;
}
//以上程式碼非基因變異的一般性程式碼只是用來保證基因編碼的可行性。
}
}
}值得一提的是遺傳演算法中基因突變的特點和上一章提到的生物學中的基因突變的特點非常相類似,這裡回顧一下:
1.基因突變是隨機發生的,且突變頻率很低。(不過某些應用中需要高概率的變異)
2.大多數基因變異對生物本身是有害的。
3.基因突變是不定向的。
好了,到此為止,基因編碼,基因適應度評估,基因選擇,基因變異都一一實現了,剩下來的就是把這些遺傳過程的“零件”裝配起來了。
未完待續,承接下篇遺傳演算法入門到掌握(二)