
Hadoop 基本架構
什麼是Hadoop?
Hadoop是Apache的一款開源框架,使用java語言編寫,可以通過編寫簡單的程式來實現大規模資料集合的分散式計算。工作在Hadoop框架上的應用可以工作在分散式儲存和計算機叢集計算的環境上面。Hadoop具有高擴充套件性,其叢集能夠從單臺機器擴充套件到數千臺機器。
Hadoop 採用的是Apache v2協議,Hadoop基於Google釋出的MapReduce論文實現,並且應用了函數語言程式設計的思想。
Hadoop 架構
Hadoop框架包括下述三個個模組
HDFS, MapReduce, YARN
HDFS
Hadoop Distributed File System (HDFS) 是Hadoop叢集中最根本的檔案系統,它提供了高擴充套件,高容錯,機架感知資料儲存等特性,可以非常方便的部署在機器上面。HDFS除過分散式檔案系統所通有的特點之外,還有些僅屬自己的特點:
- 對硬體故障的考慮設計
- 更大的資料單元,預設的塊大小為128M
- 對序列操作的優化
- 機架感知
- 支援異構叢集和跨平臺
Hadoop叢集中的資料被劃分成更小的單元(通常被稱為塊),並且將其分散式儲存在叢集中,每個塊有兩個副本,這個兩個副本被儲存在叢集的的一個機架上。這樣資料包含自身便有三個副本,具有極高的可用性和容錯性,如果一個副本丟失,HDFS將會自動的重新複製一份,以確保叢集中一共包含三個資料副本(包含自身)。
HDFS也可以有多種形式,這個取決於Hadoop版本及所需功能。
HDFS是Leader/Follower架構實現的,每個叢集都必須包含一個NameNode節點,和一個可選的SecondaryName節點,以及任意數量的DataNodes。
除了管理檔案系統名稱空間和管理元資料之外,NameNode對clients而言,還扮演著master和brokers的角色(雖然clients是直接與DataNode進行通訊的)。NameNode完全存在於記憶體中,但它仍然會將自身狀態寫入磁碟。
HDFS 的替代檔案系統
HDFS是Hadoop中經典的檔案系統,但是Hadoop並不僅僅支援HDFS,它還支援其他的檔案系統,比如Local file system, FTP, AWS S3, Azure’s file system, 和OpenStack’s Swift,這些檔案系統可以在使用時根據不同URI進行區分。比如:
file: for the local file system
s3: for data stored on Amazon S3
MapReduce
MapReduce是為能夠在叢集上分散式處理海量資料而量身訂做的框架,MapReduce job可以分為三次連續過程。
- Map 將輸入資料劃分為key-value集合
- Shuffle 將Map產生的結果傳輸給Reduce
- Reduce 則對接收到的key-value進一步處理
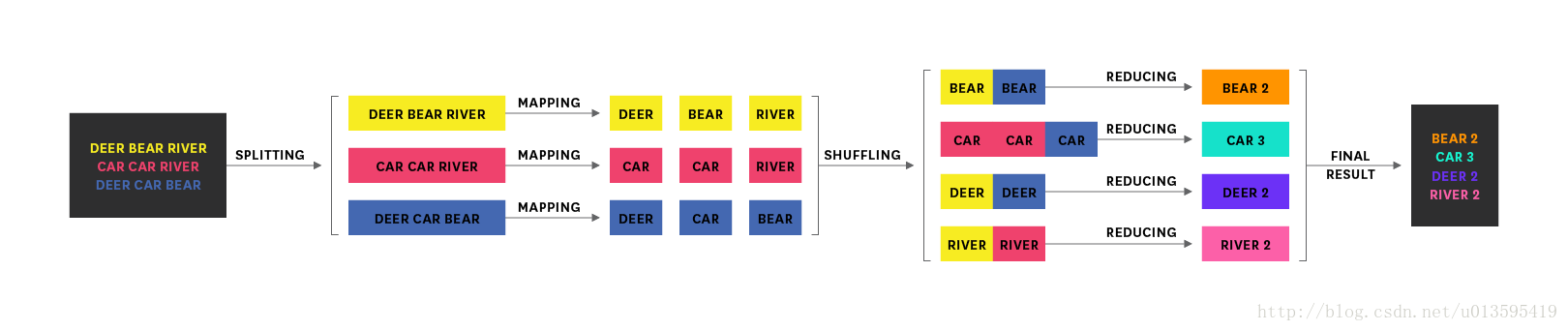
MapReduce的最大工作單元便是job,每個job又會被分割成map task或reduce task。最經典的MapReduce job便是統計文件中單詞出現的頻率,這個過程可以使用下圖來描述
YARN
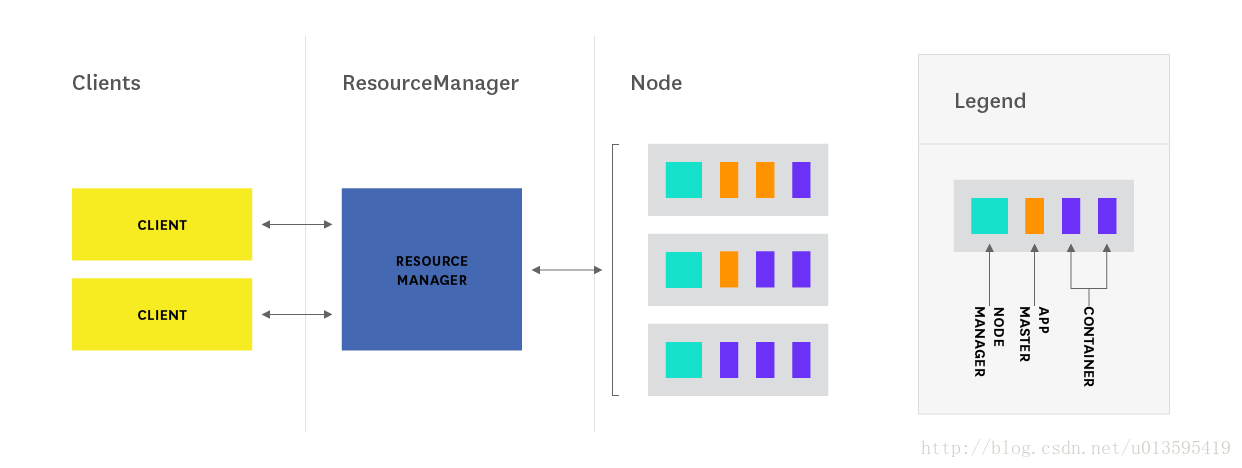
YARN (Yet Another Resource Negotiator) 是為應用執行分配計算資源的一個框架。YARN主要包含下面三個核心元件
- ResourceManager(一個叢集只有一個)
- ApplicationMaster(每個應用都有一個)
- NodeManagers (每個節點都有一個)
Note:
YARN 使用了一些容易讓人誤解的名詞作為術語,因此應該特別注意。比如在Hadoop ecosystem中,
Container這個概念,平常我們聽到Container時,我們都認為是與Docker相關。但是這裡卻是指Resource Container (RC),即表示物理資源的集合。通常被抽象的表示,將資源分配給到目標和可分配單元。
Application也是一個熟詞僻義的用法,在YARN中,一個Application指的是被一併執行的task的集合,YARN中的Application的概念大概類似於MapReduce中的job這個概念。
ResourceManager
ResourceManager在YARN中是一個rack-aware master節點,它主要負責管理所有可用資源的集合和執行一些至關重要的服務,其中最重要的便是Scheduler
Scheduler元件是YARN Resourcemanager中向執行時應用分配資源的一個重要元件,它僅僅完成資源排程的功能,並不完成監控應用狀態和進度的功能,因此即使應用執行失敗,它也不會去重啟失敗的應用。
但是在Hadoop 2.7.2開始,YARN開始支援少數排程策略CapacityScheduler,FairScheduler,FIFO Scheduler。預設情況下由Hadoop來負責決定使用哪種排程策略,無論使用那種排程策略,Scheduler都會通過Continer來向請求的ApplicationMaster分配資源。
ApplicationMaster
每個執行在Hadoop上面的應用都會有自己專用的ApplicationMaster例項。每個例項進會存在於叢集中每個節點僅屬於自己的單獨Container。每個Application的ApplicationMaster都會週期性的向ResourceManager傳送心跳訊息,如果有需要的話,還會去向ResourceManger請求額外的資源,ResourceManager便會為額外的資源劃分租期(表明該資源已被某NodeManager所持有)
ApplicationMaster會監控每個application的整個生命週期,從向ResourceManager請求額外的資源到向NodeManager提交請求。
NodeManagers
NodeManager可以認為是監控每個節點的Container的代理,會監控每個Container的整個生命週期,包括Continer的資源使用情況,與ResourceManager的週期性通訊。
從概念上來說,NodeManager更像是Hadoop早期版本的TaskTrackers,當時Taskrackers主要被用來解決排程map和reduce slots問題,NodeManager有一個動態建立的,任意大小的Resouce Containers(RCs),並不像MR1中的那種slots,RCs可以被用在map tasks中,reduce tasks中,或者是其他框架的tasks
為了更好的描述YARN,這裡給出一個YARN application的執行過程。如下圖所示:

- client向ResourceManager提交一個MapReduce應用,和啟動指定應用的ApplicationMaster所需要的資訊。
- ResourceManager 會為ApplicationMaster分派一個Container,並且啟動Application
- ApplicationMaster啟動,接著向ResourceManager註冊自己,允許呼叫client直接與ApplicationMaster互動
- ApplicatoinMaster為客戶端應用分配資源
- ApplicationMaster為application啟動Container
- 在執行期間,clients向Applicationaster提交application狀態和進度
- apllication執行完成,ApplicationMaster向ResouceManager撤銷掉自己的註冊資訊,然後關機,將自己所持有的Container歸還給資源池。