
hadoop技術基本架構
一、Hadoop概述
hadoop由兩部分組成,分別是分散式檔案系統和分散式計算框架MapReduce。其中,分散式檔案系統主要用於大規模資料的分散式儲存,而MapReduce 則構建在分散式檔案系
統之上,對儲存在分散式檔案系統中的資料進行分散式計算。
2、在Hadoop 中,MapReduce 底層的分散式檔案系統是獨立模組,使用者可按照約定的一套介面實現自己的分散式檔案系統,然後經過簡單的配置後,儲存在該檔案系統上的資料便
可以被MapReduce處理。Hadoop 預設使用的分散式檔案系統是HFDS(Hadoop Distributed File System ,Hadoop 分散式檔案系統),它與MapReduce 框架緊密結合。
二、Hadoop HDFS 架構
H D F S 是一個具有高度容錯性的分散式檔案系統,適合部署在廉價的機器上。H D F S 能提供高吞吐量的資料訪問,非常適合大規模資料集上的應用。HDFS 的架構如下圖1所示,總體上採用了master/slave 架構,主要由以下幾個元件組成:Client 、NameNode 、Secondary 和DataNode 。下面分別對這幾個元件進行介紹。
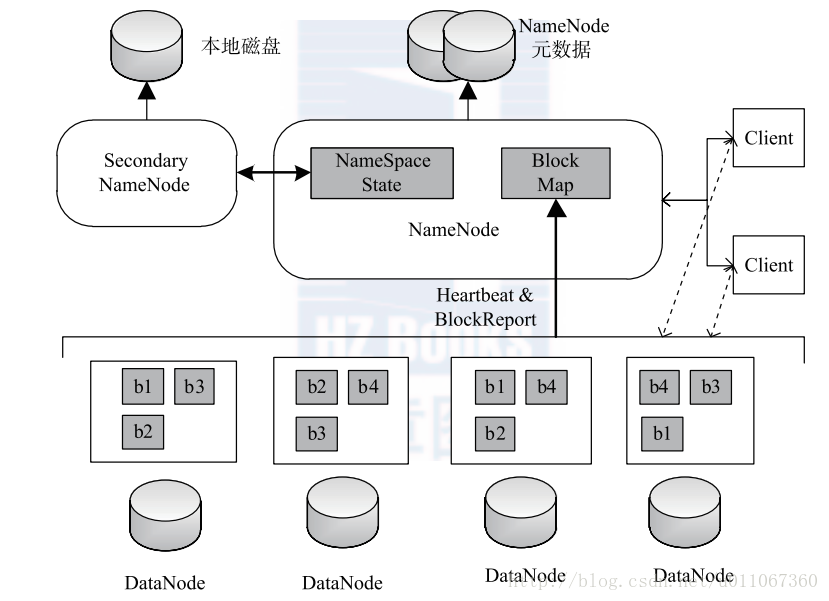
圖1 hadoop HDFS 架構圖
(1 )Client
C l i e n t (代表使用者)通過與NameNode和DataNode互動訪問H D F S 中的檔案。Clien提供了一個類似POSIX 的檔案系統介面供使用者呼叫。
(2 )NameNode
整個H a d o o p 叢集中只有一個NameNode。它是整個系統的“總管”,負責管理H D F S的目錄樹和相關的檔案元資料資訊。這些資訊是以“fsimage”(H D F S 元資料映象檔案)和 “editlog ”(H D F S 檔案改動日誌)兩個檔案形式存放在本地磁碟,當H D F S 重啟時重新構造出來的。此外,NameNode 還負責監控各個DataNode 的健康狀態,一旦發現某個DataNode 宕掉,則將該DataNode
移出H D F S 並重新備份其上面的資料。
(3 )Secondary
NameNodeSecondary NameNode 最重要的任務並不是為NameNode 元資料進行熱備份,而是定期合併f s i m a g e 和e d i t s 日誌,並傳輸給NameNode 。這裡需要注意的是,為了減小N a m e N o d e壓力,NameNode 自己並不會合併fsimage 和edits ,並將檔案儲存到磁碟上,而是交由Secondary NameNode 完成。
(4 )DataNode
一般而言,每個S l a v e 節點上安裝一個DataNode ,它負責實際的資料儲存,並將資料
息定期彙報給NameNode 。DataNode 以固定大小的b l o c k 為基本單位組織檔案內容,預設情況下b l o c k 大小為6 4 M B 。當用戶上傳一個大的檔案到H D F S 上時,該檔案會被切分成
若干個b l o c k ,分別儲存到不同的DataNode ;同時,為了保證資料可靠,會將同一個b l o c k以流水線方式寫到若干個(預設是3 ,該引數可配置)不同的DataNode 上。這種檔案切割後儲存的過程是對使用者透明的。
三、Hadoop MapReduce 架構
1、同H D F S 一樣,Hadoop MapReduce 也採用了Master / Slave (M /S )架構,具體如下圖2所示。它主要由以下幾個元件組成:Client 、JobTracker 、 TaskTracker 和Task 。下面分別對這幾個元件進行介紹。
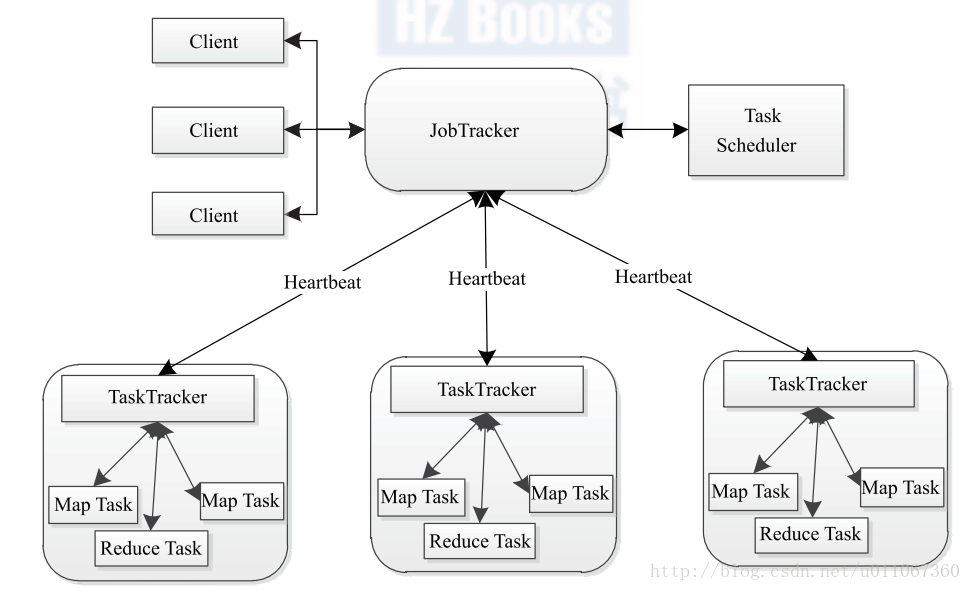
圖2 H a d o o p MapReduce 架構圖
(1 )Client
使用者編寫的MapReduce 程式通過Client 提交到JobTracker 端;同時,使用者可通過Client 提供的一些介面檢視作業執行狀態。在Hadoop 內部用“作業”(Job)表示MapReduce 程式。一個MapReduce 程式可對應若干個作業,而每個作業會被分解成若干個Map/Reduce 任務(Task)。
(2 )JobTracker
JobTracker 主要負責資源監控和作業排程。JobTracker 監控所有TaskTracker 與作業的健康狀況,一旦發現失敗情況後,其會將相應的任務轉移到其他節點;同時,JobTracker 會跟蹤任務的執行進度、資源使用量等資訊,並將這些資訊告訴任務排程器,而排程器會在資源出現空閒時,選擇合適的任務使用這些資源。在H a d o o p 中,任務排程器是一個可插拔的模組,使用者可以根據自己的需要設計相應的排程器。
(3 )TaskTracker
TaskTracker 會週期性地通過Heartbeat 將本節點上資源的使用情況和任務的執行進度彙報給JobTracker,同時接收JobTracker 傳送過來的命令並執行相應的操作(如啟動新任務、殺死任務等)。TaskTracker 使用“slot”等量劃分本節點上的資源量。“slot”代表計算資源(CPU、記憶體等)。一個Task 獲取到一個slot 後才有機會執行,而Hadoop 排程器的作用就是將各個TaskTracker 上的空閒slot 分配給Task 使用。slot 分為Map slot 和Reduce slot 兩種,分別供Map Task 和Reduce Task 使用。TaskTracker 通過slot 數目(可配置引數)限定Task 的併發度。
(4 )Task
Task 分為Map Task 和Reduce Task 兩種,均由TaskTracker 啟動。從上一小節中我們知道,HDFS 以固定大小的block 為基本單位儲存資料,而對於MapReduce 而言,其處理單位是split。
split 與block 的對應關係如下圖3所示。split 是一個邏輯概念,它只包含一些元資料資訊,比如資料起始位置、資料長度、資料所在節點等。它的劃分方法完全由使用者自己決定。但需要注意
的是,split 的多少決定了Map Task 的數目,因為每個split 會交由一個Map Task 處理。
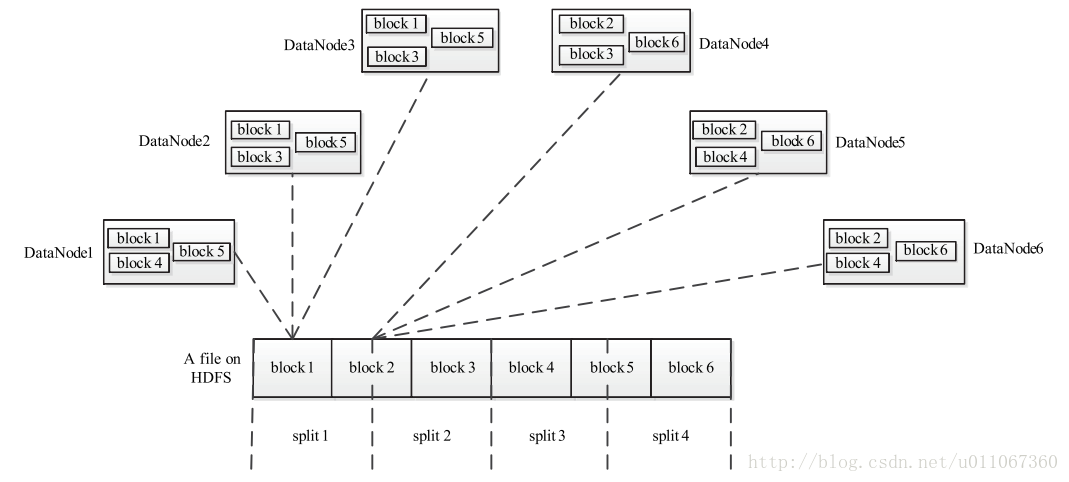
圖3 split 與block 的對應關係
PS:
1、Map Task 執行過程如圖4所示。由該圖可知,Map Task 先將對應的s p l i t 迭代解析成一個個key / value 對,依次呼叫使用者自定義的map ( ) 函式進行處理,最終將臨時結果存放到本地磁碟上,其中臨時資料被分成若干個partition ,每個partition 將被一個Reduce Task 處理。

圖4 M a p Ta s k 執行流程
2、Reduce Task 執行過程如圖5所示。該過程分為三個階段
①從遠端節點上讀取Map Task 中間結果(稱為“Shuffle 階段”);
②按照key 對key / value 對進行排序(稱為“Sort 階段”);
③依次讀取< key, value list > ,呼叫使用者自定義的reduce ( ) 函式處理,並將最終結果存到HDFS 上(稱為“Reduce 階段”)。
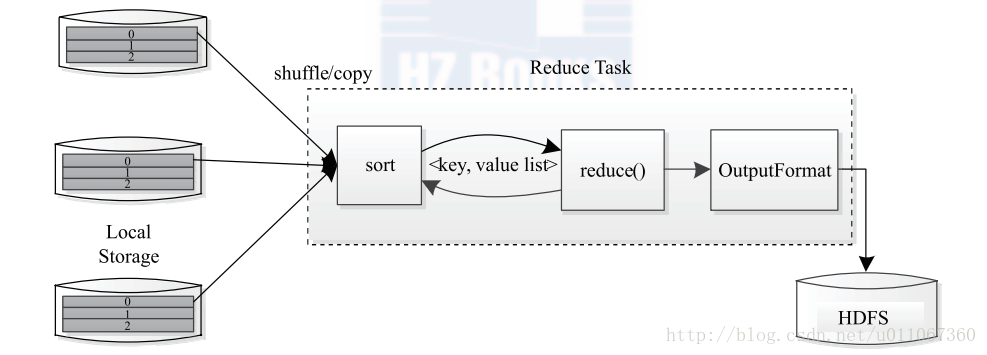
圖5 R e d u c e Ta s k 執行過程
PS
1、Hadoop MapReduce 直接誕生於搜尋領域,以易於程式設計、良好的擴充套件性和高容錯性為設計目標。它主要由兩部分組成:程式設計模型和執行時環境。其中,程式設計模型為使用者提供了5個可程式設計元件,分別是InputFormat 、Mapper 、Partitioner 、Reducer、OutputFormat ;執行時環境則將使用者的MapReduce 程式部署到叢集的各個節點上,並通過各種機制保證其成功執行。
2、Hadoop MapReduce 處理的資料一般位於底層分散式檔案系統中。該系統往往將使用者的檔案切分成若干個固定大小的block 儲存到不同節點上。預設情況下,MapReduce 的每個Ta s k 處理一個block。 MapReduce 主要由四個元件構成,分別是Client 、Job Tracker 、TaskTracker 和Task ,它們共同保障一個作業的成功執行。一個MapReduce 作業的執行週期是,先在Client 端被提交到JobTracker 上,然後由JobTr acker
將作業分解成若干個Ta s k ,並對這些Ta s k 進行排程和監控,以保障這些程式執行成功,而TaskTracker 則啟動JobTracker 發來的Ta s k ,並向Job Tracker 彙報這些Task 的執行狀態和本節點上資源的使用情況。