
keras的LSTM相關原理及引數理解
理解:units引數是指他們的輸出引數,把lstm中cell中的幾個連線看成是前饋神經網路層,發現h和x輸入的結合能夠被前饋神經網路層輸出對應的維度,h和輸出的維度相同,千萬要理解下面的黃框框是一個前饋神經網路,這樣才能好理解。我前面一直理解h的維度會發生變化上,進入誤期了。
連結:https://www.zhihu.com/question/41949741/answer/309529532
這個問題也困擾了我很久,後來終於明白了,很多資料都沒有在這個地方做詳細的解釋,那就是 LSTM 的 cell 裡面的 num_units 該怎麼理解,其實也是很簡單,看看下圖:
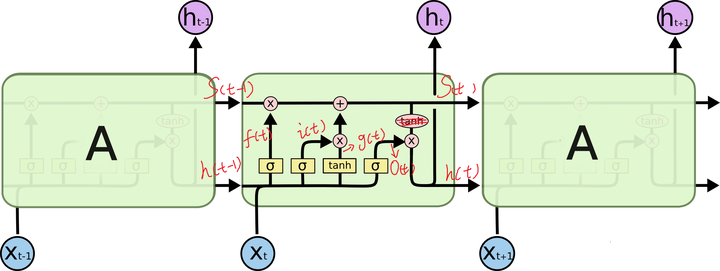
可以看到中間的 cell 裡面有四個黃色小框,你如果理解了那個代表的含義一切就明白了,每一個小黃框代表一個前饋網路層
另外幾個需要注意的地方:
1、 cell 的狀態是一個向量,是有多個值的。。。一開始沒有理解這點的時候怎麼都想不明白
2、 上一次的狀態 h(t-1)是怎麼和下一次的輸入 x(t) 結合(concat)起來的,這也是很多資料沒有明白講的地方,也很簡單,concat, 直白的說就是把二者直接拼起來,比如 x是28位的向量,h(t-1)是128位的,那麼拼起來就是156位的向量,就是這麼簡單。。
3、 cell 的權重是共享
4、那麼一層的 LSTM 的引數有多少個?根據第 3 點的說明,我們知道引數的數量是由 cell 的數量決定的,這裡只有一個 cell,所以引數的數量就是這個 cell 裡面用到的引數個數。假設 num_units 是128,輸入是28位的,那麼根據上面的第 2 點,可以得到,四個小黃框的引數一共有 (128+28)*(128*4),也就是156 * 512,可以看看 TensorFlow 的最簡單的 LSTM 的案例,中間層的引數就是這樣,不過還要加上輸出的時候的啟用函式的引數,假設是10個類的話,就是128*10的 W 引數和10個bias 引數
註明:128是h向量,28是輸入向量,黃框框把128+28的維度對映為128維的向量
5、cell 最上面的一條線的狀態即 s(t) 代表了長時記憶,而下面的 h(t)則代表了工作記憶或短時記憶
暫時這麼多。
-----------------------------------------------------------------------------------------------------------------------------------------------------
引數檢視文章:
原文:https://blog.csdn.net/jiangpeng59/article/details/77646186
keras.layers.recurrent.LSTM(units, activation='tanh', recurrent_activation='hard_sigmoid', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', unit_forget_bias=True, kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0)