
常見的GAN網路的相關原理及推導
常見的GAN網路的相關原理及推導
在上一篇中我們給大家介紹了GAN的相關原理和推導,GAN是VAE的後一半,再加上一個鑑別網路。這樣而導致了完全不同的訓練方式。
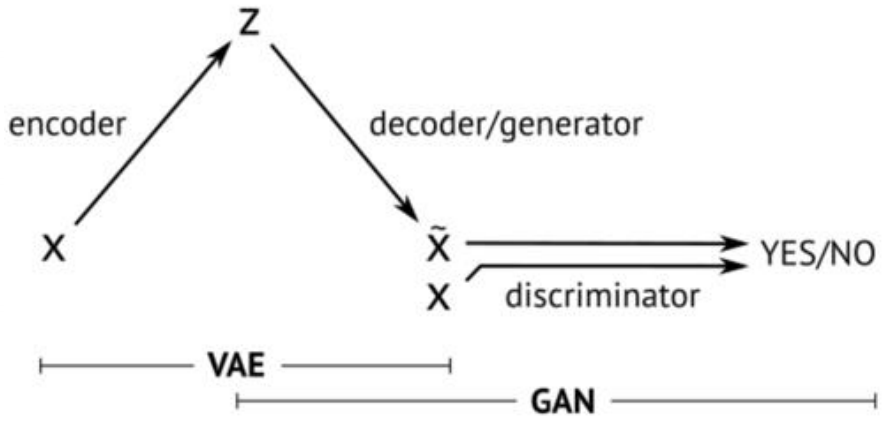
GAN,生成對抗網路,主要有兩部分構成:生成器,判別器。
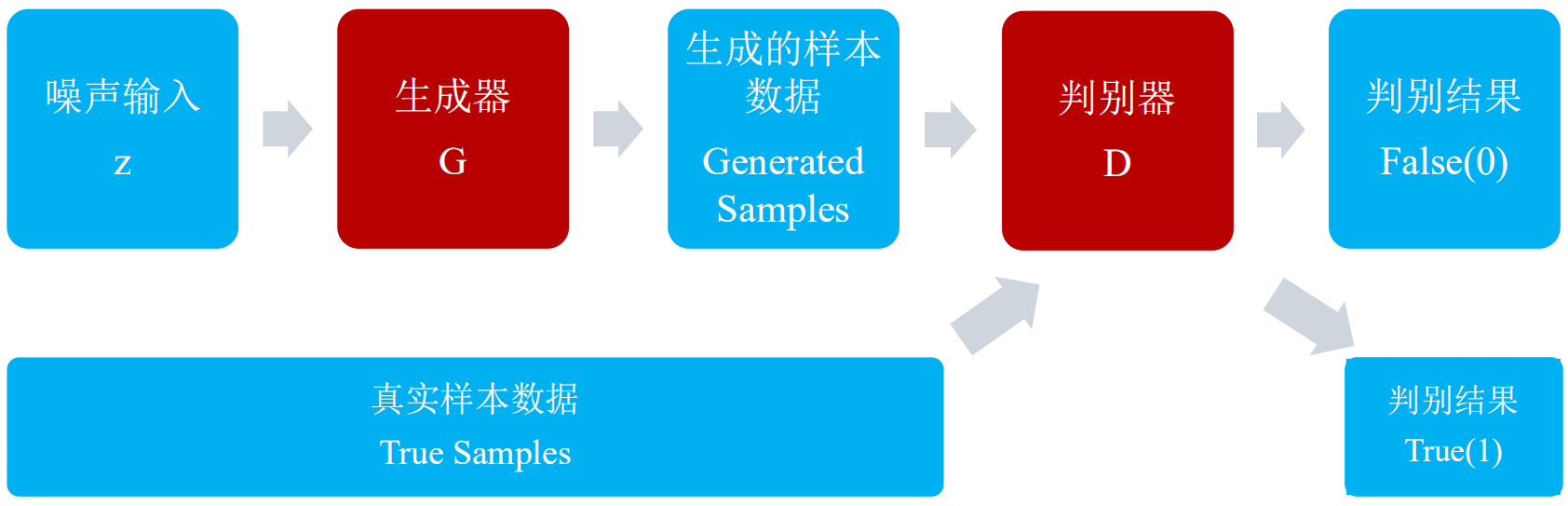
生成器網路的主要工作是負責生成樣本資料,輸入的是高斯白噪聲z,輸出的是樣本資料向量x:
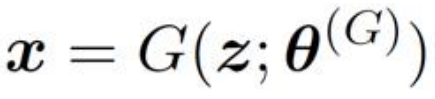
判別器網路的主要工作是負責檢測樣本的資料增加,輸入真實或者生成的樣本資料,輸出樣本的標籤:
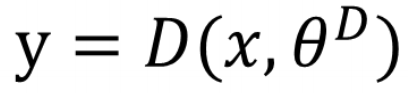
由於生成器和判別器都是需要經過網路進行訓練的,所以兩者都要能夠微分。
生成對抗網路的工作方式是讓第一代的G產生一些圖片,然後把這些圖片和一些真實的圖片丟到第一代的D裡面去學習,讓第一代的D能夠分別生成的影象和真實的圖片。在訓練第二代的G,第二代的G產生的圖片,能夠騙過第一代的D,在訓練第二代的D,依次迭代。
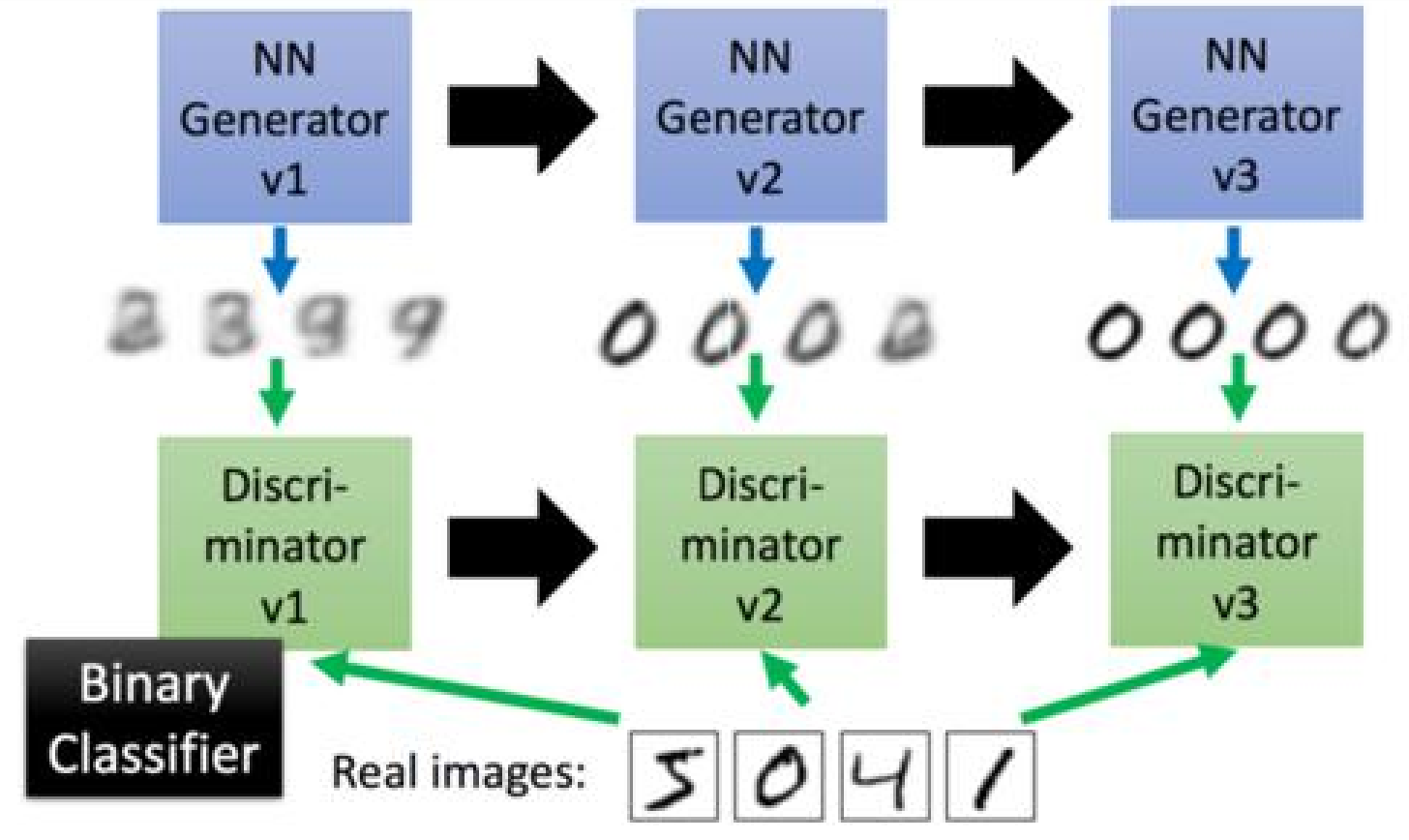
那麼,問題就來了,如何訓練新一代的G來騙過上一代的D呢?
我們可以把新一代的G和上一代的D連起來形成一個新的NN,我們訓練最終的輸出接近1,然後我們那中間的結果當做我們新的圖片的輸出。
優化函式
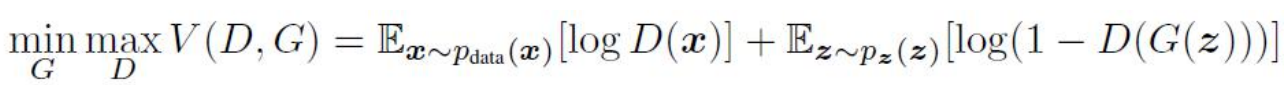
生成器G固定之後,使用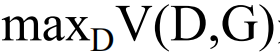 來評價Pdata和Pz之間的差異。優化方式,對於生成器優化而言,我們要最小化價值函式,對於判別器而言,我們要優化最大價值函式,不斷的交替進行之後,能夠達到有個平衡點,稱之為納什均衡點。
來評價Pdata和Pz之間的差異。優化方式,對於生成器優化而言,我們要最小化價值函式,對於判別器而言,我們要優化最大價值函式,不斷的交替進行之後,能夠達到有個平衡點,稱之為納什均衡點。
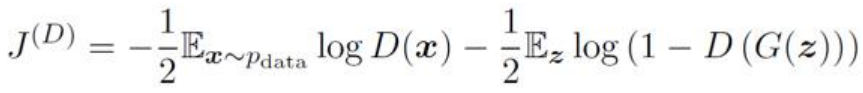

生成器最小化目標即為判別器將生成資料識別為假的概率的log值,對於上述提到的均衡點,它是判別代價函式的鞍點。
對於GAN的訓練演算法,步驟如下:
a、執行D-step的minibatch優化k次:
1.從先驗分佈p(z)隨機生成m個隨機噪聲向量z
2.從資料集分佈p(x)裡隨機獲取m個樣本x
3.使用隨機梯度上升優化判別器的代價函式
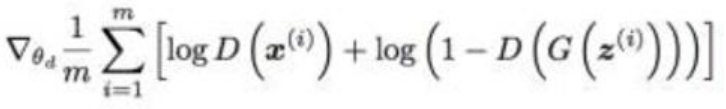
b.執行G-step的minibatch優化1次:
1.從先驗分佈p(z)隨機生成m個隨機噪聲向量z
2.使用梯度下降優化生成器的代價函式
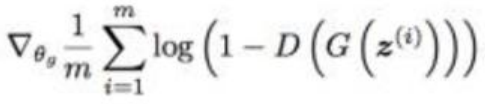
我們可以通過下面的曲線進一步理解訓練過程:
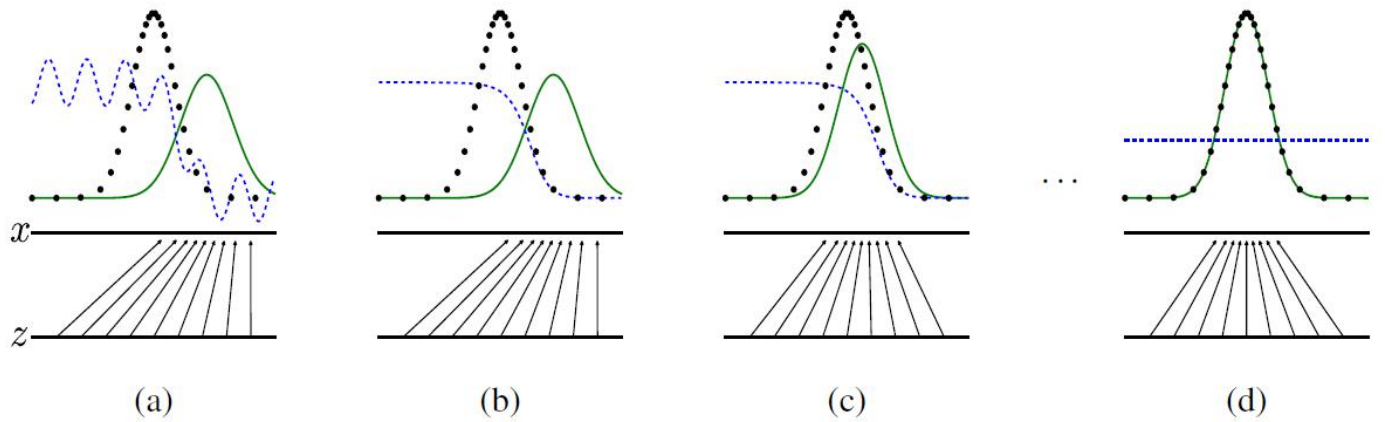
其中,綠線為生成器的資料分佈,黑線為真實資料的分佈,藍線為判別器的結果分佈。
GAN的問題:
GAN的訓練比較困難,主要存在收斂難,很難達到納什均衡點,並且無法有效監控收斂狀態,另一方面,模型容易崩潰,判別器快速達到最優,能力明顯強於生成器,生成器將資料集中生成在判別器最認可的空間上,即輸出多樣性低,不使用於離散輸出(不可微分)。
&n