
人類動作識別資料集AVA
教機器理解視訊中的人類動作是計算機視覺領域中的一個基礎研究問題,對個人視訊搜尋和發現、運動分析和手勢交流等應用十分必要。儘管近幾年影象分類和檢索領域實現了很大突破,但是識別視訊中的人類動作仍然是一個巨大挑戰。原因在於動作本質上沒有物體那麼明確,這使得我們很難構建精確標註的動作視訊資料集。儘管很多基準資料集,如 UCF101、ActivityNet 和 DeepMind Kinetics,採用了影象分類的標註機制,併為資料集中的每一個視訊或視訊片段分配一個標籤,但是仍然不存在包含多人不同動作的複雜場景的資料集。
為了推進人類動作識別方面的研究,谷歌釋出了新的資料集 AVA(atomic visual actions),提供擴充套件視訊序列中每個人的多個動作標籤。AVA 包括 YouTube 公開視訊的 URL,使用包含 80 個原子動作(atomic action)集進行標註(如「走路」、「踢(某物)」、「握手」),所有動作都有時空定位,從而產生 57.6k 視訊片段、96k 標註人類動作和 210k 動作標籤。你可以點選 https://research.google.com/ava/ 檢視 AVA 資料集並下載標註。論文地址:https://arxiv.org/abs/1705.08421。
與其他動作資料集相比,AVA 具備以下關鍵特徵:
-
以人類為中心的標註。相比於視訊或片段,每個動作標籤都與人類更加相關。因此,我們能夠向同一場景中執行不同動作的多人分配不同的標籤,而這種場景非常常見。
-
原子視覺動作(Atomic visual actions)。我們將動作標籤限制在固定的時間長度(3 秒),所有動作都是物理動作且有清晰的視覺訊號(visual signature)。
-
真實的視訊材料。我們使用不同型別和國家的電影作為 AVA 的資料來源。因此,資料覆蓋大範圍的人類行為。
為建立 AVA,我們首先從 YouTube 上收集了大量多樣化的資料,主要集中在「電影」和「電視」類別,選擇來自不同國家的專業演員。我們對每個視訊抽取 15 分鐘進行分析,並統一將 15 分鐘視訊分割成 300 個非重疊的 3 秒片段。取樣遵循保持動作序列的時間順序這一策略。
接下來,我們為每個 3 秒片段中間幀的人物手動標註邊界框。對標註框中的每個人,標註者從預製的原子動作詞彙表(80 個類別)中選擇適當數量的標籤來描述人物動作。這些動作可分為三組:姿勢/移動動作、人-物互動和人-人互動。我們對執行動作的所有人進行了全部標註,因此 AVA 的標籤頻率遵循長尾分佈,如下圖所示。
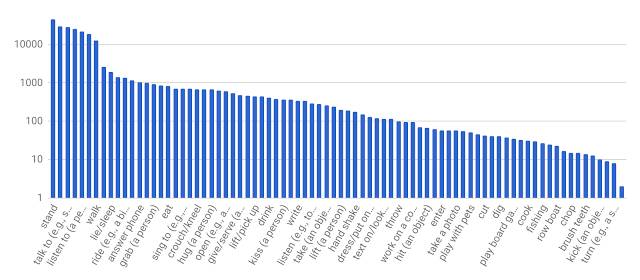
AVA 的原子動作標籤分佈。x 軸所示標籤只是詞彙表的一部分。
AVA 的獨特設計使我們能夠獲取其他現有資料集中所沒有的一些有趣資料。例如,給出大量至少帶有兩個標籤的人物,我們可以判斷動作標籤的共現模式(co-occurrence pattern)。下圖顯示 AVA 中共現頻率最高的動作對及其共現得分。我們確定的期望模式有:人們邊唱歌邊彈奏樂器、擁吻等。
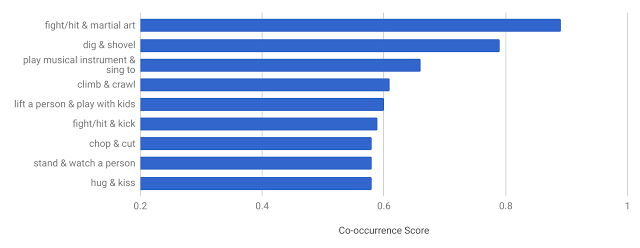
AVA 中共現頻率最高的動作對。
為評估基於 AVA 資料集的人類動作識別系統的高效性,我們使用一個現有的基線深度學習模型在規模稍小一些的 JHMDB dataset 上取得了具備高競爭性的效能。由於存在可變焦距、背景雜亂、攝影和外觀的不同情況,該模型在 JHMDB dataset 上的效能與在 AVA 上準確識別動作的效能(18.4% mAP)相比稍差。這表明,未來 AVA 可以作為開發和評估新的動作識別架構和演算法的測試平臺。
我們希望 AVA 的釋出能夠幫助人類動作識別系統的開發,為基於個人動作精確時空粒度的標籤對複雜活動進行建模提供了機會。我們將持續擴充套件和改進 AVA,並且很樂意獲取社群反饋以幫助我們校正未來方向。加入 AVA 使用者郵件列表(https://groups.google.com/forum/#!forum/ava-dataset-users)即可獲取 AVA 資料集更新。