
Moments in Time:IBM-MIT聯合提出最新百萬規模視訊動作理解資料集
在過去一年中,視訊理解相關的領域湧現了大量的新模型、新方法,與之相伴的,今年也出現了多個新的大規模的視訊理解資料集。近期,MIT-IBM Watson AI Lab 就推出了一個全新的百萬規模視訊理解資料集Moments-in-Time[1]。雖然沒有之前的YouTube-8M資料集大,但應該是目前多樣性,差異性最高的資料集了。該資料集的任務仍然為視訊分類任務,不過其更專注於對“動作”的分類,此處的動作為廣義的動作或動態,其執行者不一定是人,也可以是物體或者動物,這點應該是該資料集與現有資料集最大的區分。本文中簡單的統稱為“動作”。
資料集概覽
這部分主要對資料集的基本情況和特性進行介紹,大概可以總結為以下幾點
- 共有100,0000個視訊,每個視訊的長度相同,均為3s
- 每個視訊有一個動作標籤(後續版本可能拓展為多標籤),此處的動作僅為動詞,比如“opening”就為一個標籤(與之不同,其他資料集經常會採用動名片語的形式如”opening the door”)
- 動作主體可以是人,動物,物體乃至自然現象。
- 資料集的類內差異和類間差異均很大。
- 存在部分或完全依賴於聲音資訊的動作,如clapping(拍手)
由上述描述可以看出,由於超大的資料量以及多樣性,這個資料集是相當難的,下圖則為該資料集的一個例子。可以看出,一個動作類別可以由多種動作主體完成,從而從視覺上看的差異性相當的大,動作的概念可以說是相當抽象了。

下面我對作者構建這個資料集的方式進行介紹,這部分內容也有助於對該資料集的理解。
資料集的構建
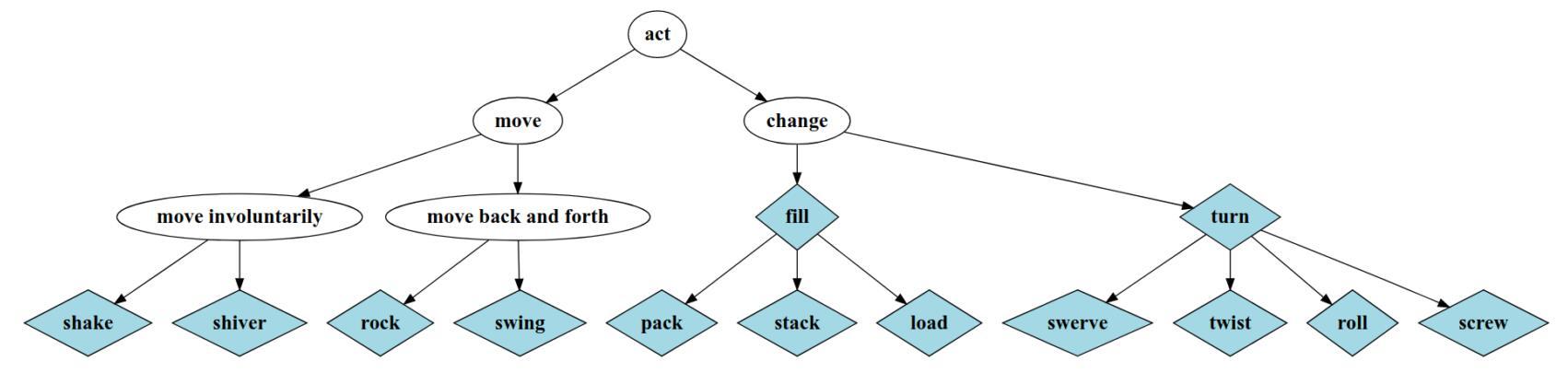
1.建立動作的字典
該資料集採用的是先確定動作標籤,再根據動作標籤構建視訊集合的方式。構建動作標籤集合,在該資料集中即構建一個合適的動作字典。主要通過以下幾個步驟實現
- 參考[2]中的內容,選取4500個美式英語中最常用的動詞
- 按照詞義對這4500個詞進行聚類,一個動詞可以屬於多個聚類
- 迭代的從最常見的聚類中選取最常見的動詞加入目標字典
- 最終從4500個初始動詞中選取339個最常見的動詞作為字典
2. 資料收集與標註
在確定好動詞字典後,作者對每個動詞,在多個視訊網站上進行視訊的爬取。這裡的視訊網站比較多,包含YouTube,Flicker,Vine等十幾個網站,比起只用YouTube的ActivityNet,Kinectic等資料集在來源的豐富性上要高不少。
在爬完資料後,每個視訊都是以 視訊-動詞 對的形式呈現,標註工作的主要目的就是確定視訊是否可以用動詞描述,所以是一個二分類的標註任務(此處作者的解釋是,多分類的標註對於標註者難度太高,也容易錯,故採用二分類的標註方式)。標註工作在近來大量資料集都採用的Amazon Mechanical Turk實現。
對於每個標註者,都會被分配64個待標註的動詞-視訊對以及10個已知真值的動詞-視訊對。在10個已知真值的動詞-視訊對中,只有標對9個及以上,該標註者的標註結果才會被認為是有效的。剩下的所有動詞-視訊對,都會被交由2個標註者,只有倆人的標註結果一致,該結果才會被採用。所以從標註角度來看,這個資料集的標籤質量應該還是不錯的。標註介面的樣式如下圖所示,可以看出還是相當簡潔明瞭的。

資料集的資料分佈
接下來我主要對該資料集的資料分佈進行介紹,由於該資料集目前還沒有正式放出,所以所有資料和圖表均來自論文。
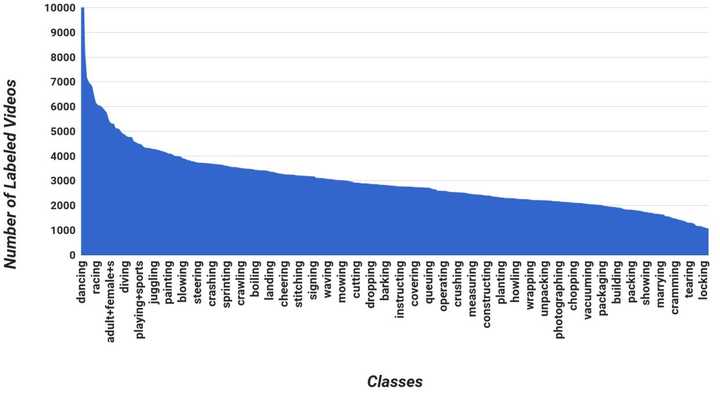
首先是資料集的類別分佈:
- 對於339個動作類別,共有超過100000個標註視訊
- 每個類別至少有1000個視訊,每個類別視訊數量的平均值是1757,中值是2775
類別與類別視訊數量的關係圖如下圖所示。
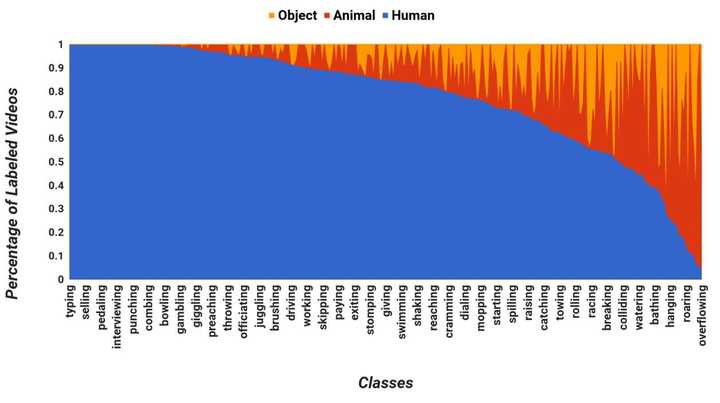
接下來,作者介紹了資料集中動作主體的分佈情況,如前所述動作主題可能是人,動物或一般物體。作者統計了不同類別視訊中各類動作主題所佔比例的分佈,如下圖所示。左側的極端是“typing“,主體全部是人類,右邊的極端是”overflowing”,動作主題基本不是人類。
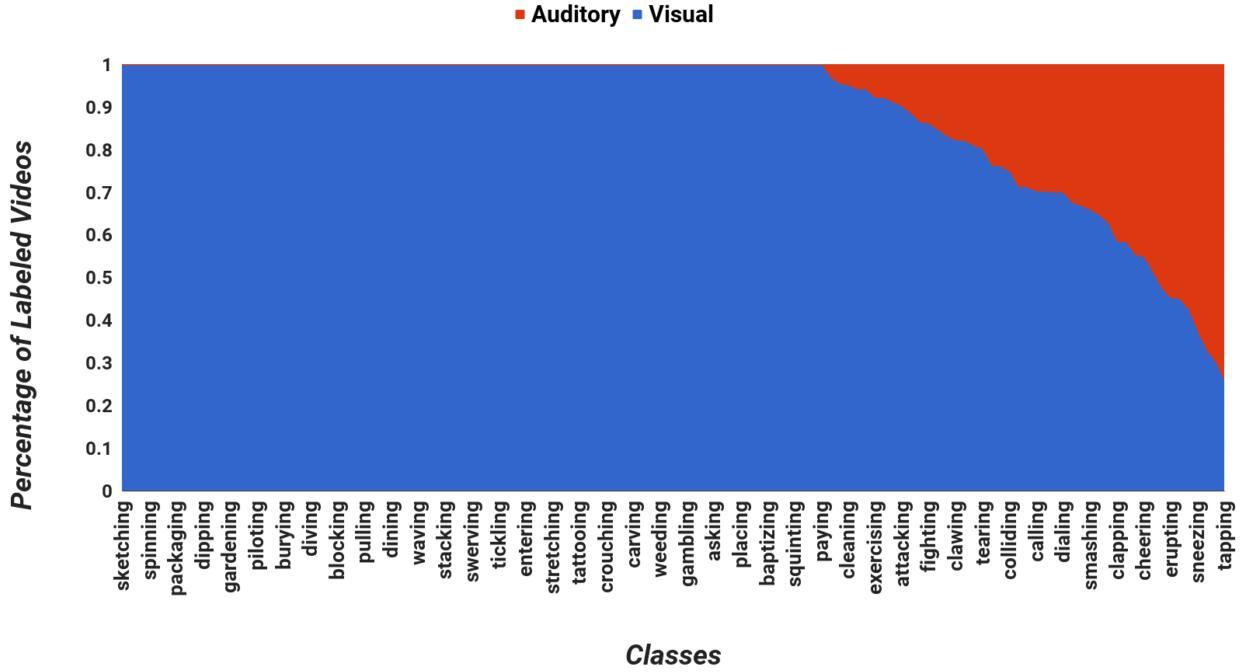
最後,作者分析了資料集各個類別中依賴於聲音的視訊所在的比例。此處,依賴於聲音的視訊是指該視訊無法從影象上判斷出其包含的動作,而必須要聽聲音。從下圖可以看出,有相當比例的視訊是依賴於聲音的,這點要增加了該資料集的挑戰性。
場景、物體與動作之前的相關性探索
最後,作者通過一組簡單的實驗探索了各個資料集中 物體-場景-動作 之間的相關性。此處分析的視訊資料集除了Moments in Time外, 還包括UCF-101, ActivityNet 1.3 以及Kinetics資料集。
這裡的實驗設定還蠻有趣的。作者分別採用了一個在ImageNet上訓練的Resnet50用於物體分類,一個在Places資料集上訓練的Resnet50用作場景分類。對於每個視訊,均勻抽取3幀並利用兩個網路進行檢測並平均結果,可以得到一個物體label以及一個場景label。對於物體或場景label,作者通過貝葉斯公式來推斷對應的動作類別,其中先驗概率在資料集的訓練集上計算獲得。
實驗結果如下表所示,可以得到以下幾點結論:
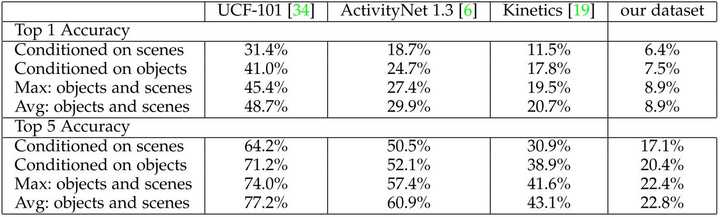
- 動作與場景以及物體均是相關的。
- Moments in Time資料集中,動作與物體以及場景的相關性顯著弱於其他幾個資料集,這表明該資料集有更高的挑戰性以及更大的難度。
個人討論
Moments-in-Time資料集我覺得還是相當有趣以及有挑戰性的,估計很快就會有不少人跟進來做這個資料集(顯而易見需要比較大的計算資源…)。下面是我對於該資料集的一些討論內容,包括優點以及一些個人存在疑惑的地方。
優點:
- 資料集的大小和豐富程度很高,足以訓練較複雜的視訊分類模型。
- 視訊的長度統一為3s,這樣的設計方便實驗時進行處理,也使得資料集的尺寸不至於過大。
- 資料標註的策略應該還是比較靠譜的,應該不太會有錯誤標註。
以上是幾點明顯的優點,但對於作者強調的幾個資料集優點,我則存在一些疑惑:
- 僅用動詞定義動作:這個應該是這個資料集和其他資料集相比最大的一個差異點。作者認為通過該資料集能夠學習一個泛化能力很強的動作概念,但在我看來這樣的定義有些太過寬泛了。動詞的含義常常依賴於其主語和謂語,單獨的動詞即便對於人類而言也常常是含義模糊的。此處可以參考今年ICCV上的[3]一文,我此前也寫過一篇筆記:https://zhuanlan.zhihu.com/p/29227174 介紹這篇文章。這篇文章中一個重要的觀點是,動作應該用動詞-名詞組合來定義,從而明確其含義。不過該資料集也是故意在此處模糊化從而增加類內差異,現在也不能夠知道是否是一個好的設計了。
- 動作的主體不一定是人:這點也是資料集作者有意設計,從而增加難度以及多樣性。我也持有同樣的對於定義不清晰的疑惑,比如人開門(“opening”)和風吹開了一扇窗戶(”opening“)放在同一個類別中總感覺不太合理。此外,此處還有一個問題,儘管溫中給出了動作主體的分析,但通過詢問作者,第一版的資料集不會提供動作主體的label,而僅包含一個動作label。
- 依賴聲音的動作:這點我覺得倒是蠻好的,可以促進多模態方法的發展。但是同以上一點,該資料集在訓練集中並沒有告知這個視訊中的動作是否是依賴與聲音的。如果有相關的標籤,我覺得會更有助於視訊的理解吧。作者可能會在後續版本加上。
總體而言,這個新資料集還是很有趣且充滿挑戰的,與此前的多個主要關注人類動作的資料集在設定上有較大的差異。針對這個資料集,模型方面應該更注重於對動作概念的理解以及對較大的類內差異性的處理。期待之後針對該資料集的演算法了。
本文投稿於AI科技評論公眾號, 未經許可請勿轉載。
參考文獻
[1] Monfort M, Zhou B, Bargal S A, et al. Moments in Time Dataset: one million videos for
event understanding[J].
[2] Salamon J, Jacoby C, Bello J P. A dataset and taxonomy for urban sound research[C]//Proceedings of the 22nd ACM international conference on Multimedia. ACM, 2014: 1041-1044.
[3] Sigurdsson G A, Russakovsky O, Gupta A. What Actions are Needed for Understanding
Human Actions in Videos?[J]. arXiv preprint arXiv:1708.02696, 2017.