
無監督對話資料清洗利器:Data Purification Framework
作者/吳金龍
現在一提到聊天機器人,大家就會想起各種演算法模型,端到端、生成式、深度增強學習。有一種給我足夠多足夠好的資料,我就能用演算法突破圖靈測試的風範。可恨的是,就是沒夠多夠好的資料。相對於英文,中文可用的公開資料集少之又少。
在聊天機器人裡,可用的公開對話資料就更少了,比如閒聊類的也就小黃雞、華為微博資料,而且這些資料也都還不夠好。不論是公開資料還是自己抓的各種資料,使用前的清洗都是必須的。清洗資料是個苦活,資料量大時就算投入大量人力也未必有好的產出。本文介紹愛因互動正在使用的一種資料清洗方法,我們稱之為Data Purification Framework(簡稱DPF)。DPF是無監督的,所以基本不需要人力投入,但最終清洗效果還不錯。雖然本文名為對話資料清洗,但此方法其實可以用在很多其他場景。
資料清洗框架:DPF
DPF的理念很簡單,利用不靠譜的資料訓練一個模型,這個模型在訓練集上準確度通常都很低(如果訓練集上已經完美擬合,那這個方法就不能直接用了)。用訓練好的模型把最不靠譜的那些資料(預測與實際差的最遠)刪掉,然後利用剩下的資料訓練新的模型,之後再用新模型把剩下資料裡最不靠譜的一些資料刪掉,如此重複,直到模型在訓練集上達到較高的準確度。這時候被篩完剩下的資料可能比較少了。
為了召回一些被早期模型誤過濾掉的樣本,我們把最新的模型應用到原始的全量資料上,這樣去除最不靠譜的資料後會留下更多的資料用於接下來的迭代。之後的迭代邏輯和前面的相同,利用模型清除最不靠譜的資料,再用清洗後的新資料訓練新模型。類似此方法的思想在很多地方都出現過,比如一些半監督擴充資料的場景。DPF框架圖如下:
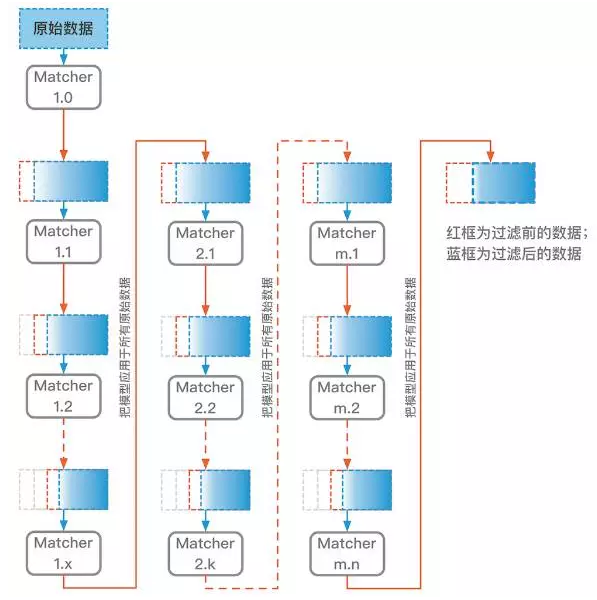
這個方法有效的一個關鍵是用於識別資料靠譜性的匹配模型(圖中的Matcher),需要找到合適的匹配模型來統一衡量每個樣本點的靠譜性。這個匹配模型不一定和資料清洗後最終被使用的模型一致。
對DPF框架圖中的主要元件(下圖)做個簡單說明。
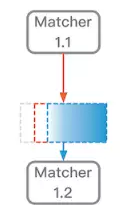
- 紅色箭頭連線一個模型和一個數據集,表示把此模型用於預測此資料集。這裡表示使用Matcher1.1預測紅框中的資料集。利用預測的匹配值,對紅框中資料進行排序,清除掉匹配度最差的一部分資料,剩下的就是藍框所表示的資料。
- 藍色箭頭連線一個數據集和一個模型,表示使用此資料集訓練出此模型。這裡匹配演算法使用藍框資料進行訓練獲得Matcher1.2。
清洗小黃雞對話資料
小黃雞資料
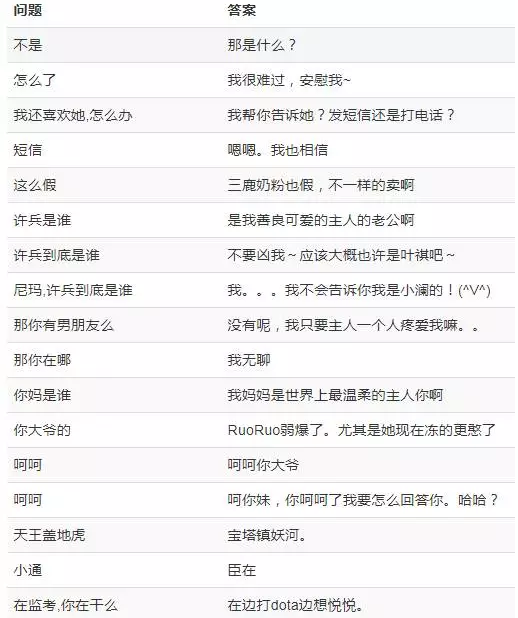
小黃雞資料是小黃雞與使用者的聊天qa對,包括了35w+ qa對。除了很多黃暴的樣例,還有很多答案與問題壓根不匹配的樣例。一些樣例見下圖,每行中左邊是問題,右邊是答案。我們的初衷是使用小黃雞資料來訓練seq2seq閒聊模型,但直接使用效果很差,而且還容易生成罵人的答覆。
選擇Matcher模型
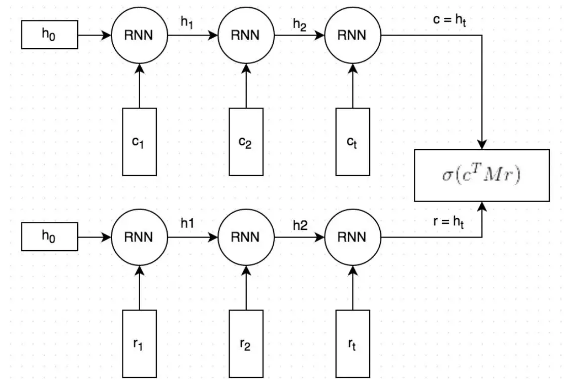
在具體清洗流程開始前,還需要確定使用什麼模型作為DPF中的Matcher模型。 對於qa對話資料,我們發現dual encoder模型是一個好的選擇。dual encoder首先利用RNN把問題和答案都向量化,然後以這兩個向量的匹配程度來說明這個問答對的匹配程度。
接下來說明清洗小黃雞對話資料的具體流程。
清洗流程
- 訓練Matcher1.0,清除噪音資料
在訓練Match1.0時,我們把所有的小黃雞qa對作為正樣本,然後隨機抽取一些q和其他的a生成相同數量的負樣本。從預測準確度來看,Match1.0在訓練集上只能到0.75左右,在測試集上大概0.65,很差。
把訓練好的Match1.0用於預測其訓練集中的所有正樣本(也即原始的小黃雞qa對),並按照預測的匹配概率對qa對進行排序。然後把匹配概率低於某個閾值的qa對全部刪掉(如果刪除過多,可以設定一個刪除的最高比例)。比如在這裡我們設定了0.5的匹配閾值。
- 訓練Matcher1.1,進一步清除噪音資料
以上一步清洗後的資料作為正樣本,隨機產生等量的負樣本。利用這些正負樣本訓練Matcher1.1。把訓練好的Match1.1用於預測其訓練集中的所有正樣本,並按照預測的匹配概率對qa對進行排序。然後把匹配概率低於某個閾值的qa對全部刪掉(如果刪除過多,可以設定一個刪除的最高比例)。這個流程跟上面一樣,但這裡的匹配閾值可以設定得更高,比如0.6,因為此時訓練資料和模型都比Matcher1.0更好了。Match1.1在訓練集上的準確度能到0.82左右,在測試集上大概0.7。
- 訓練Matcher1.2 –> Matcher1.x,逐步迭代清除噪音資料
和上面的流程一致,對上面清洗好的資料做進一步的清洗。此時的匹配閾值可以再高點,比如0.7。Match1.2在訓練集上的準確度能到0.89左右,在測試集上大概0.76。
這個迴圈繼續,直到Matcher1.x在訓練集上的準確度達到預設值(比如0.98),或者被清除的資料量低於預設數量,或者迭代次數達到預設值(比如10次)。在這個過程中,匹配閾值可以設定得越來越高,最高可以到0.9甚至0.95。因為後面模型的精度逐漸變高,所以閾值更高也不會刪除很多資料(應該讓被清除的資料量逐漸降低)。在小黃雞資料上,Matcher1.8在訓練集上的準確度超過了0.98。它的訓練集裡的正樣本只有清洗後剩下的7w+條qa對。
迭代到這步,其實可以像之前的迭代那樣對訓練資料進行清洗,然後把剩下的資料作為我們最終的資料結束整個清洗過程。但很多時候我們希望能從已被清洗的資料中再找回一些靠譜的資料。畢竟早期用於清洗的模型本身也並不是那麼靠譜。 所以我們可以把Match1.8用於最初的全量資料上,預測它們的匹配概率。這就是框架圖裡第一列到第二列的連線線。和之前的步驟一樣,按匹配概率排序,把低於設定閾值的樣本去掉。小黃雞裡如果我們設定閾值為0.9,清洗後可以剩下11w+的qa對。下圖中展示了一些匹配概率最低(左上角紅框)和最高(右下角藍框)的樣本。每行代表一個樣本,格式為問題||答案||匹配概率值。可以看出區分度還是很明顯的。
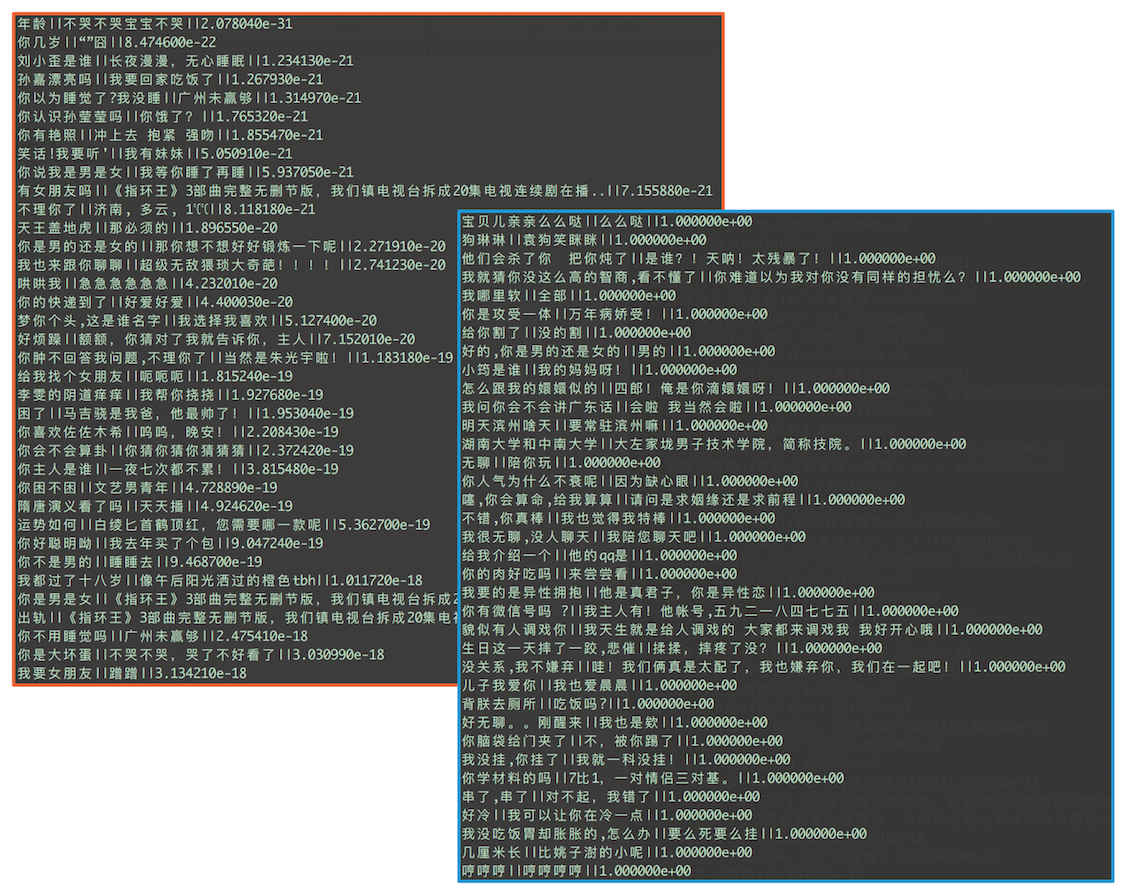
清洗後的結果資料可以作為最終結果返回,也可以進一步進行提純,把它作為Matcher2.1的訓練集,繼續迭代……
實際執行時,我們在小黃雞資料上跑到Matcher1.8就結束了,在微博資料上我們跑到了Matcher3.5,訓練集上的準確度達到0.981。
DPF的清洗過程雖然無需人工干預,但每步迭代都需要重新訓練模型,在資料量大時整個過程還是很耗時的。一個降低訓練時間的方法是每次訓練新模型時,把其引數初始化為前一個模型的訓練結果。
Seq2seq+Attention模型結果
我們把上面Matcher1.8清洗獲得的7.1w+小黃雞qa資料作為訓練集,以單字模式訓練seq2seq+attention對話生成模型。
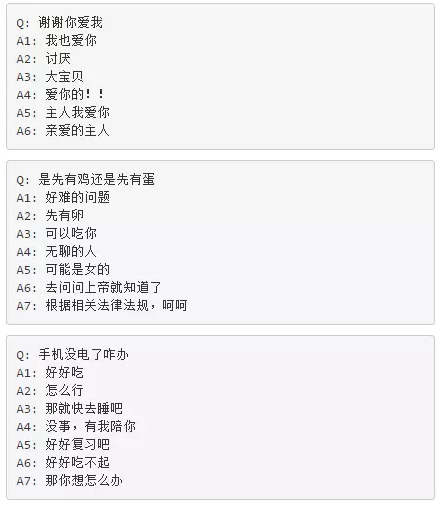
下面是一些模型結果(我們對基本模型做了一些改進,具體請見我們之後的文章)。其中Q表示問題,A表示使用beam search產生的topN答案,A後面的數字表示序號,比如A2表示排名第二的結果。
注:有些候選結果被某些後處理步驟過濾掉了。

作者簡介:吳金龍,個人微博和部落格分別為@breezedeus和http://breezedeus.github.io。2010年獲得北京大學數學院計算數學專業博士學位,期間研究方向為推薦系統中的協同過濾演算法。畢業後加入阿里雲,主要從事PC和雲手機的輸入法開發。2011年加入世紀佳緣,負責世紀佳緣使用者推薦系統的開發。作為世紀佳緣資深總監,領導世紀佳緣技術部,負責佳緣資料和AI相關的各項工作,並負責開發了中文對話機器人(bot)建立平臺『一個AI』。2017年初作為合夥人加入愛因互動,負責演算法部門工作。
