
知識圖譜入門 (八) 語義搜尋
本節對語義搜尋做一個簡單的介紹,而後介紹語義資料搜尋、混合搜尋。該部分理解不深,後續會進一步補充。
語義搜尋簡介
什麼是語義搜尋,借用全球資訊網之父Tim Berners-Lee的解釋 “語義搜尋的本質是通過數學來拜託當今搜尋中使用的猜測和近似,併為詞語的含義以及它們如何關聯到我們在搜尋引擎輸入框中所找的東西引進一種清晰的理解方式,
不同的搜尋模式之間的技術差異可以分為:
- 對使用者需求的表示(query model)
- 對底層資料的表示(data model)
- 匹配方法(matching technique)
以前常用的搜尋是基於文件的檢索(document retrieval )。資訊檢索(IR)支援對文件的檢索,它通過輕量級的語法模型表示使用者的檢索需求和資源內容,如 AND OR。即目前占主導地位的關鍵詞模式:詞袋模型。它對主題搜尋的效果很好,但不能應對更加複雜的資訊檢索需求
資料庫(DB) 和知識庫專家系統(Knowledge-based Expert System)可以提供更加精確的答案(data retrieval)。它使用表達能力更強的模型來表示使用者的需求、利用資料之間的內在結構和語義關聯、允許複雜的查詢、返回精確匹配查詢的具體答案。
語義搜尋答題可分為兩類:
DB 和KB 系統屬於重量級語義搜尋系統,它對語義顯示的和形式化的建模,例如 ER圖或 RDF(S) 和OWL 中的知識模型。主要為語義的資料檢索系統。
基於語義的IR 系統屬於輕量級的語義搜尋系統。採用輕量級的語義模型,例如分類系統或者辭典。語義資料(RDF)嵌入文件或者與文件關聯。它是基於語義的文件檢索系統
。
隨著結構化和語義資料的可用性越來越高,資料Web搜尋和文件Web搜尋有逐漸融合的趨勢。
對於Web搜尋,採用傳統上應用於IR 領域的,擴充套件性較好的方法,來處理WEb 資料的質量問題,和與長文字描述相關的資料元素。
對於文件Web搜尋,資料庫和語義搜尋技術被應用到IR系統中,以便在搜尋過程中結合運用日益增加的,高度結構化和表達能力強的資料。
語義搜尋的流程圖如下圖所示:
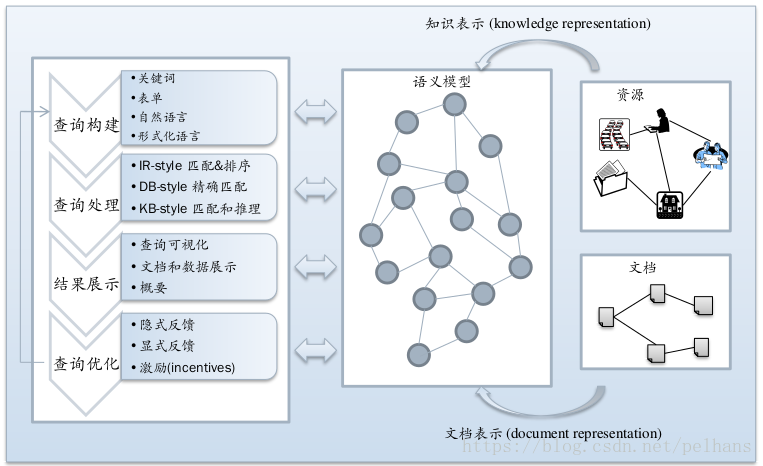
語義資料搜尋
語義資料搜尋具有以下難點:
- 可擴充套件性: 語義資料搜尋對連結資料的有效利用要求基礎架構能擴充套件和應用在大規模和不斷增長的內鏈資料上。
- 異構性: 資料來源的異構性、多資料來源查詢、合併多資料來源的查詢結果。
- 不確定性: 使用者需求的表示不完整
下面介紹一些基於三元組儲存的語義資料搜尋最佳實踐及其對應原理。
基於IR:Sindice, FalconS;是單一資料結構和查詢演算法,針對文字資料進行排序檢索來優化。它的資料是高度可壓縮的,可訪問的。排序是組成部分。但不能處理簡單的select,join等操作。
基於DB:Oracle的RDF擴充套件,DB2的SOR;具有各種索引和查詢演算法,以適應各種對結構化資料的複雜查詢。優點是能夠完成複雜的selects,joins,…(SQL, SPARQL),能夠對高動態場景(許多插入/刪除)。缺點是由於使用B+樹,空間的開銷大和訪問的侷限性。同時來自葉子節點的結果沒有整合對檢索結果的排序。
原生儲存(Native stores):Dataplore, YARS, RDF-3x;優點是高度可壓縮,可訪問。類似於IR的檢索排序。類似於DB的selects和joins操作。可在亞秒級實踐內在單臺機器上完成對TB資料的查詢。支援高動態操作。缺點是沒有事務、恢復等。
儲存和索引(Semplore,Dataplore的前身)
重用IR 索引來索引語義資料。它的核心想法是將RDF轉換稱具有fields 和terms的虛擬文件。IR索引基於以下概念:
- 文件
- 欄位(field),例如標題、摘要、正文、作者….
- 詞語(terms)
- Posting list 和Position list
下面以一個例子來理解上面的術語:
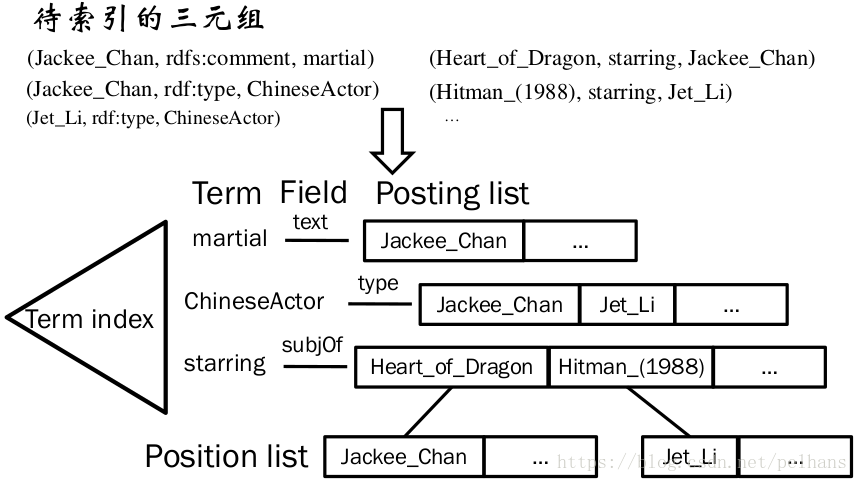
當新插入元素時,不可能完全重建索引,因此需要使用增量索引。當前的增量索引需要遍歷Posting list,非常耗時,因此需要將Posting list 進行分塊,但更多的快需要更多的隨機訪問來定位這些塊,同時更多的快需要更多的空間開銷。因此需要權衡索引更新,搜尋和索引大小。
排序和索引
上面建立的索引並存儲。現在我們需要對其進行檢索,對於檢索我們需要支援四種基本的操作:
- 基礎的檢索:(f, t)
- 歸併排序:m(S1, op, S2)
概念表示式計算: ,如
關係擴充套件(Relation Expansion): ,
如,這個是需要我們去完善的
那麼如何進行復雜的查詢呢?下圖給出一個例子:
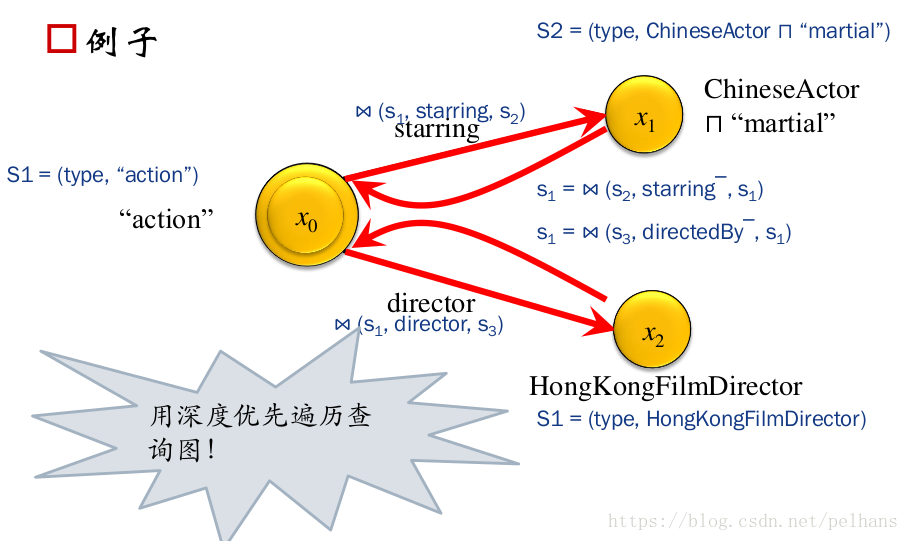
其大致流程為先從x0出發到x1,x1返回結果到x0,在將該結果傳到x2進行查詢,最終再返回x0。 遍歷圖的方式為深度優先遍歷查詢。
查詢時我們還需要對其進行排序,排序有兩個原則:
- 質量傳播原則:一個元素的分數可以看成是其質量(quality)的度量,質量傳播即通過更新這個分數同時反應該元素的相鄰元素的質量。
- 數量聚合:除質量外,還考慮鄰居的數量。因此,如果有更多的鄰居,元素排名會更高。
如何將排序緊密結合到基本操作中呢?
- Ascending IntegerStream (AIS)
- 基本檢索:給定field f和 term t, b(f, t) 從倒排索引中檢索出posting list, 並輸出一個Ascending Integer List (AIS)。
- 歸併排序:S1 和 S2 是兩個AIS , 計算S1 and S2的交集
- 關係擴充套件:給定關係R和AIS S,計算集合 並將其作為AIS返回
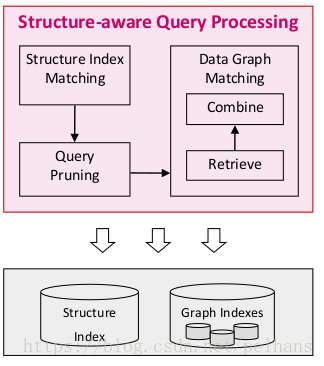
基於結構的分割槽和查詢
基於結構的索引和分割槽,需要將結構上相似的節點聚合到一起,同時結構上相似的節點在硬碟上連續儲存。基於結構感知(Structure-aware)的查詢處理需要分兩階段匹配,第一個是隻檢索出匹配所查詢的結構的資料,第二個是通過剪枝減少join和IO。其流程如下圖所示
一個數據圖的索引建立和查詢例子如下圖所示:


首先用結構索引匹配查詢在答案空間裡檢索和join,產生一組包含的資料元素匹配查詢中的結構的結構索引。而後根據匹配的結構索引計算最終答案,其中剪枝僅包含非標識(non-distinguished)變數的樹形查詢部分。在資源空間檢索和join:驗證答案空間匹配中的元素是否也匹配具體的查詢實體,即常量和標識(distinguished)變數。
使用結構索引做結構匹配的有點是降低IO開銷和union 和join操作的次數。
多資料來源搜尋–以Hermes 為例
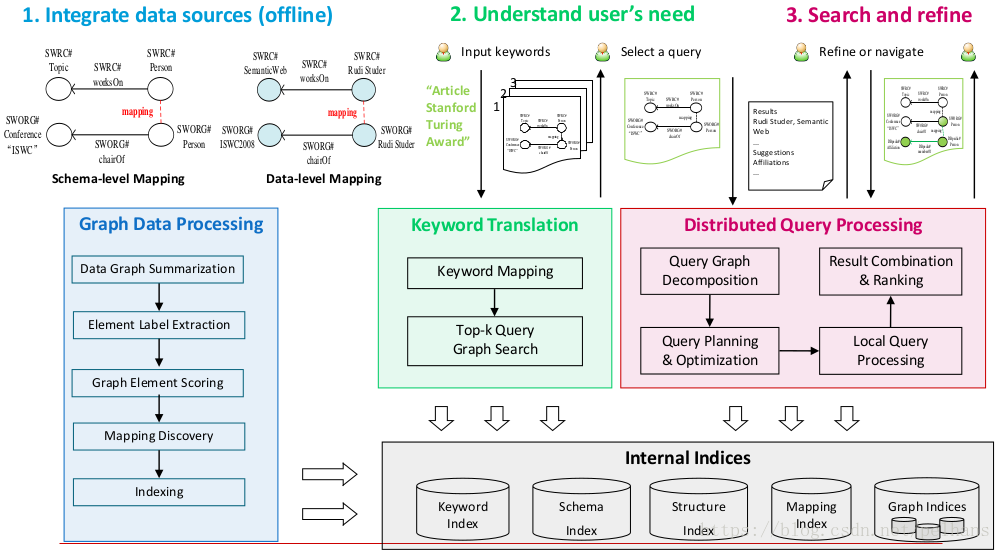
可以看出其大體分為三塊,第一部分是資料來源融合部分,第二部分是理解使用者需求,最終是搜尋和提煉。
其知識融合部分流程為:

混合語義搜尋
下一代語義搜尋系統結合了一系列技術,從基於統計的IR排序方法,有效索引和查詢處理的資料庫方法,到推理的複雜推理技術等等。一個混合的語義搜尋系統應:
- 結合文字,結構化和語義資料
- 以整體的方式管理不同型別的資源
- 支援結果為資訊單元(文件,資料)的整合的檢索。
一個典型的系統架構是。其流程圖如下圖所示:
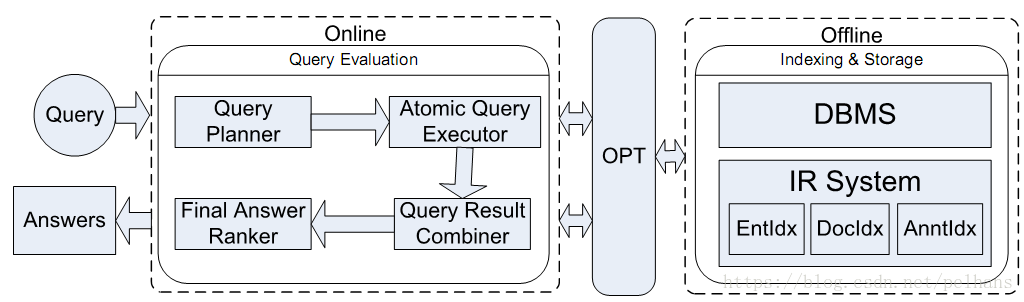
上圖中的OPT(occur probity table, 發生概率表)分為線上和線下兩個步驟。對於線下步驟,資料圖儲存於DBMS中,除Entldx中的三元組(個體,關鍵詞,”xxx”)外,Doc 圖儲存在Docldx中,註釋儲存在Anntldx中。線上步驟將混合查詢分解為一組原子查詢(atomic queries);使用DB和IR引擎執行原子查詢;根據生成的查詢樹合併部分結果;對最後的答案排序。