Scrapy學習筆記(3)爬取知乎首頁問題及答案
阿新 • • 發佈:2019-02-04
目標:爬取知乎首頁前x個問題的詳情及問題指定範圍內的答案的摘要
power by:
- Python 3.6
- Scrapy 1.4
- json
- pymysql
Step 1——相關簡介
Step 2——模擬登入
知乎如果不登入是爬取不到資訊的,所以首先要做的就是模擬登入
主要步驟:
獲取xsrf及驗證碼圖片
填寫驗證碼提交表單登入
登入是否成功獲取xsrf及驗證碼圖片:
def start_requests(self): yield scrapy.Request('https://www.zhihu.com/', callback=self.login_zhihu) def login_zhihu(self, response): """ 獲取xsrf及驗證碼圖片 """ xsrf = re.findall(r'name="_xsrf" value="(.*?)"/>', response.text)[0] self.headers['X-Xsrftoken'] = xsrf self.post_data['_xsrf'] = xsrf times = re.findall(r'<script type="text/json" class="json-inline" data-n' r'ame="ga_vars">{"user_created":0,"now":(\d+),', response.text)[0] captcha_url = 'https://www.zhihu.com/' + 'captcha.gif?r=' + times + '&type=login&lang=cn' yield scrapy.Request(captcha_url, headers=self.headers, meta={'post_data': self.post_data}, callback=self.veri_captcha)

填寫驗證碼提交表單登入:
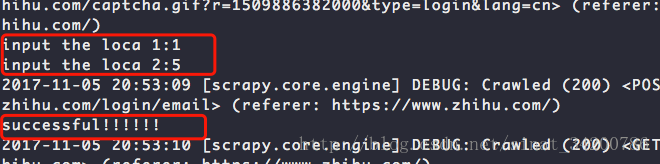
def veri_captcha(self, response): """ 輸入驗證碼資訊進行登入 """ with open('captcha.jpg', 'wb') as f: f.write(response.body) print('只有一個倒立文字則第二個位置為0') loca1 = input('input the loca 1:') loca2 = input('input the loca 2:') captcha = self.location(int(loca1), int(loca2)) self.post_data = response.meta.get('post_data', {}) self.post_data['captcha'] = captcha post_url = 'https://www.zhihu.com/login/email' yield scrapy.FormRequest(post_url, formdata=self.post_data, headers=self.headers, callback=self.login_success) def location(self, a, b): """ 將輸入的位置轉換為相應資訊 """ if b != 0: captcha = "{\"img_size\":[200,44],\"input_points\":[%s,%s]}" % (str(self.capacha_index[a - 1]), str(self.capacha_index[b - 1])) else: captcha = "{\"img_size\":[200,44],\"input_points\":[%s]}" % str(self.capacha_index[a - 1]) return captcha
登入是否成功:
def login_success(self, response):
if 'err' in response.text:
print(response.text)
print("error!!!!!!")
else:
print("successful!!!!!!")
yield scrapy.Request('https://www.zhihu.com', headers=self.headers, dont_filter=True)
Step 3——獲取首頁問題
獲取第一頁的問題只需要將問題URL提取出來即可,不過第一頁只有10個左右的問題,
如果想提取更多的問題就需要模擬翻頁以便獲取問題資料
def parse(self, response):
""" 獲取首頁問題 """
question_urls = re.findall(r'https://www.zhihu.com/question/(\d+)', response.text)
# 翻頁用到的session_token 和 authorization都可在首頁原始碼找到
self.session_token = re.findall(r'session_token=([0-9,a-z]{32})', response.text)[0]
auto = re.findall(r'carCompose":"(.*?)"', response.text)[0]
self.headers['authorization'] = 'Bearer ' + auto
# 首頁第一頁問題
for url in question_urls:
question_detail = 'https://www.zhihu.com/question/' + url
yield scrapy.Request(question_detail, headers=self.headers, callback=self.parse_question)
# 獲取指定數量問題
n = 10
while n < self.question_count:
yield scrapy.Request(self.next_page.format(self.session_token, n), headers=self.headers,
callback=self.get_more_question)
n += 10
def get_more_question(self, response):
""" 獲取更多首頁問題 """
question_url = 'https://www.zhihu.com/question/{0}'
questions = json.loads(response.text)
for que in questions['data']:
question_id = re.findall(r'(\d+)', que['target']['question']['url'])[0]
yield scrapy.Request(question_url.format(question_id), headers=self.headers,
callback=self.parse_question)
Step 4——獲取問題詳情
分析問題頁獲取問題詳情及請求問題指定範圍的指定數量答案
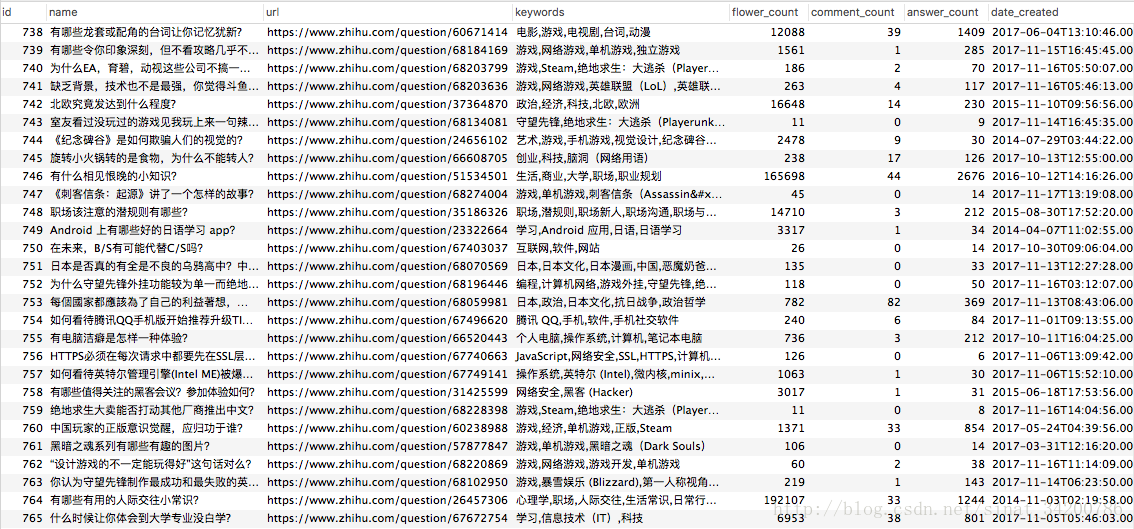
Item結構:
class ZhihuQuestionItem(scrapy.Item):
name = scrapy.Field()
url = scrapy.Field()
keywords = scrapy.Field()
answer_count = scrapy.Field()
comment_count = scrapy.Field()
flower_count = scrapy.Field()
date_created = scrapy.Field()
獲取問題詳情及請求指定範圍答案
def parse_question(self, response):
""" 解析問題詳情及獲取指定範圍答案 """
text = response.text
item = ZhihuQuestionItem()
item['name'] = re.findall(r'<meta itemprop="name" content="(.*?)"', text)[0]
item['url'] = re.findall(r'<meta itemprop="url" content="(.*?)"', text)[0]
item['keywords'] = re.findall(r'<meta itemprop="keywords" content="(.*?)"', text)[0]
item['answer_count'] = re.findall(r'<meta itemprop="answerCount" content="(.*?)"', text)[0]
item['comment_count'] = re.findall(r'<meta itemprop="commentCount" content="(.*?)"', text)[0]
item['flower_count'] = re.findall(r'<meta itemprop="zhihu:followerCount"
content="(.*?)"', text)[0]
item['date_created'] = re.findall(r'<meta itemprop="dateCreated" content="(.*?)"', text)[0]
count_answer = int(item['answer_count'])
yield item
question_id = int(re.match(r'https://www.zhihu.com/question/(\d+)', response.url).group(1))
# 從指定位置開始獲取指定數量答案
if count_answer > self.answer_count:
count_answer = self.answer_count
n = self.answer_offset
while n + 20 <= count_answer:
yield scrapy.Request(self.more_answer_url.format(question_id, n, n + 20),
headers=self.headers, callback=self.parse_answer)
n += 20
Step 5——獲取答案
在parse_question( )中請求的指定範圍答案的url返回json資料
item結構:
class ZhihuAnswerItem(scrapy.Item):
question_id = scrapy.Field()
author = scrapy.Field()
ans_url = scrapy.Field()
comment_count = scrapy.Field()
upvote_count = scrapy.Field()
excerpt = scrapy.Field()
獲取答案:
def parse_answer(self, response):
""" 解析獲取到的指定範圍答案 """
answers = json.loads(response.text)
for ans in answers['data']:
item = ZhihuAnswerItem()
item['question_id'] = re.match(r'http://www.zhihu.com/api/v4/questions/(\d+)',
ans['question']['url']).group(1)
item['author'] = ans['author']['name']
item['ans_url'] = ans['url']
item['comment_count'] = ans['comment_count']
item['upvote_count'] = ans['voteup_count']
item['excerpt'] = ans['excerpt']
yield item
Step 6——問題及答案入庫
class ZhihuPipeline(object):
def __init__(self):
self.settings = get_project_settings()
self.connect = pymysql.connect(
host=self.settings['MYSQL_HOST'],
db=self.settings['MYSQL_DBNAME'],
user=self.settings['MYSQL_USER'],
passwd=self.settings['MYSQL_PASSWD'],
charset=self.settings['MYSQL_CHARSET'],
use_unicode=True
)
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
if item.__class__.__name__ == 'ZhihuQuestionItem':
sql = 'insert into Scrapy_test.zhihuQuestion(name,url,keywords,answer_count,' \
'flower_count,comment_count,date_created) values (%s,%s,%s,%s,%s,%s,%s)'
self.cursor.execute(sql, (item['name'], item['url'], item['keywords'],
item['answer_count'],item['flower_count'],
item['comment_count'], item['date_created']))
else:
sql = 'insert intoScrapy_test.zhihuAnswer(question_id,author,ans_url',\
'upvote_count,comment_count,excerpt)values (%s,%s,%s,%s,%s,%s)'
self.cursor.execute(sql, (item['question_id'], item['author'],
item['ans_url'],
item['upvote_count'],item['comment_count'], item['excerpt']))
self.connect.commit()