python學習(三)scrapy爬蟲框架(三)——爬取桌布儲存並命名
寫在開始之前
按照上一篇介紹過的scrapy爬蟲的建立順序,我們開始爬取桌布的爬蟲的建立。
首先,再過一遍scrapy爬蟲的建立順序:
- 第一步:確定要在pipelines裡進行處理的資料,寫好items檔案
- 第二步:建立爬蟲檔案,將所需要的資訊從網站上爬取下來,並傳遞給pipelines檔案處理
- 第三步:pipelines接收spiders傳遞過來的資料,並做出相應的處理,如:桌布的下載和儲存
- 第四步:一定要記得在settings開啟pipelines
在開始之前,我們先按照上面的步驟來分析一下程式碼怎麼寫:
- 第二步:確定items,我們要下載桌布並且按照網站上的名字進行命名,下載桌布需要獲取桌布的連結image_url,命名需要桌布的名字image_name
- 第三步:編寫spiders的程式碼從網頁中獲取我們image_url和image_name
- 第四步:下載圖片並命名儲存
- 第五步:到settings裡開啟pipelines
下面正式開始敲程式碼<( ̄︶ ̄)↗[GO!]
第一步:建立scrapy爬蟲專案
開啟命令列,依次輸入如下命令:
#建立scrapy爬蟲專案
scrapy startproject bizhi_zol
#開啟新建立的爬蟲專案
cd bizhi_zol
#在專案裡建立spiders,domain為desk.zol.com.cn
scrapy genspider zol "desk.zol.com.cn" 第二步:items.py
專案建立完成後,我們按照上面的順序,先寫items
# -*- coding: utf-8 -*-
#items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class BizhiZolItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field 第三步:spiders
xpath路徑如下:
#注意!!!
#pic-list2(兩個空格)clearfix
//ul[@class="pic-list2 clearfix"]/li/a通過xpath我們得到的是桌布下載頁面的連結
再通過連結獲取桌布下載頁面,再在下載頁面內獲得桌布連結和名字
細節不再贅述,xpath路徑如下:
#內容詳情頁 獲取桌布名字
//a[@id="titleName"]/text()
#內容詳情頁 獲取桌布下載頁面
#//dd[@id="tagfbl"]/a[@id="1920x1200"]/@href
//dd[@id="tagfbl"]/a[1]/@href
#桌布下載頁 獲取桌布下載連結
//body/img[1]/@srcspiders程式碼如下:
# -*- coding: utf-8 -*-
#zol.py
import scrapy
from bizhi_zol.items import BizhiZolItem
class ZolSpider(scrapy.Spider):
name = 'zol'
#allowed_domains = ['desk.zol.com.cn']
start_urls = ['http://desk.zol.com.cn/dongman/1920x1080/']
#主站連結 用來拼接網址
base_site = 'http://desk.zol.com.cn'
def parse(self, response):
#獲取內容詳情頁連結
load_page_urls = response.xpath('//ul[@class="pic-list2 clearfix"]/li/a/@href').extract()
for load_page_url in load_page_urls:
url = self.base_site + load_page_url
#獲取內容詳情頁頁面 交給getInfo處理
print(url)
yield scrapy.Request(url, callback=self.getInfo)
def getInfo(self, response):
#定義item儲存資訊
item = BizhiZolItem()
#獲取桌布名字
item['image_name'] = response.xpath('//a[@id="titleName"]/text()').extract()[0]
print(item['image_name'])
#獲取桌布下載頁面連結
#load_page = self.base_site + response.xpath('//dd[@id="tagfbl"]/a[@id="1920x1200"]/@href').extract()[0]
#測試時發現並不是所有的桌布都有1920x1200的解析度,所以將程式碼修改如下,獲得桌布最大解析度的連結
load_page = self.base_site + response.xpath('//dd[@id="tagfbl"]/a[1]/@href').extract()[0]
#獲取桌布下載頁面 並將item作為引數傳遞給getLoadUrl
request = scrapy.Request(load_page, callback=self.getLoadUrl)
request.meta['item'] = item
yield request
def getLoadUrl(self, response):
#接收引數
item = response.meta['item']
#獲取桌布下載連結
item['image_url'] = response.xpath('//body/img[1]/@src').extract()[0]
#將item傳遞給pipelines處理
yield item第四步:pipelines.py
圖片的名字和和連結已經通過spiders獲得了,接下來我們只要對圖片進行下載然後再命名儲存即可。
下載圖片和之前的下載小說不同,這裡要用到ImagesPipeline中的get_media_requests方法來進行下載,這裡簡單介紹一下get_media_requests方法:
選中get_media_requests然後轉到定義,可以看到get_media_requests方法的原型為:
def get_media_requests(self, item, info):
return [Request(x) for x in item.get(self.images_urls_field, [])]可以看到get_media_requests有三個引數,
第一個是self,這個不必多說;
第二個是item,這個就是通過spiders傳遞過來的item
第三個是info,看名字就知道這是用來儲存資訊的,至於什麼資訊呢,info其實是一個儲存了圖片的名字和下載連結的列表
但是我們要重新命名的話必須得有圖片的路徑,這時候就需要item_completed方法了,原型如下:
def item_completed(self, results, item, info):
if isinstance(item, dict) or self.images_result_field in item.fields:
item[self.images_result_field] = [x for ok, x in results if ok]
return item注意到item_completed裡有個results引數,results引數儲存了圖片下載的相關資訊,我們將它打印出來看看:
[(True, {'url': 'https://desk-fd.zol-img.com.cn/t_s1920x1200c5/g5/M00/01/04/ChMkJ1q2H1-IDTMjAAT0D9iUubUAAm_uwJN1eoABPQn240.jpg', 'path': 'full/fedfedc2f28c22996af50ff8d4759e7031950517.jpg', 'checksum': '06bde14f40a64c288bd251ebbe17bc1e'})]瞭解了這些後,問題就簡單了,我們只需要在get_media_requests中scrapy.Request()發起請求,然後scrapy會自動將圖片下載儲存,接下來我們只要將儲存後的圖片重新命名
程式碼如下:
# -*- coding: utf-8 -*-
#pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.pipelines.images import ImagesPipeline
from bizhi_zol.settings import IMAGES_STORE as image_store
import scrapy
import os
class BizhiZolPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
#發起桌布下載請求
yield scrapy.Request(item['image_url'])
def item_completed(self, results, item, info):
#對桌布進行重新命名
os.rename(image_store + '/' + results[0][1]['path'], image_store + '/' + item['image_name'] + '.jpg')
def __del__(self):
#完成後刪除full目錄
os.removedirs(image_store + '/' + 'full')
第五步:settings.py
這裡settings檔案需要注意的是,要新增一個IMAGES_STORE變數來確定下載後圖片儲存的目錄,其他的設定不再多說,貼上程式碼:
#settings.py
BOT_NAME = 'bizhi_zol'
SPIDER_MODULES = ['bizhi_zol.spiders']
NEWSPIDER_MODULE = 'bizhi_zol.spiders'
IMAGES_STORE = './IMAGE'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'bizhi_zol.pipelines.BizhiZolPipeline': 300,
}
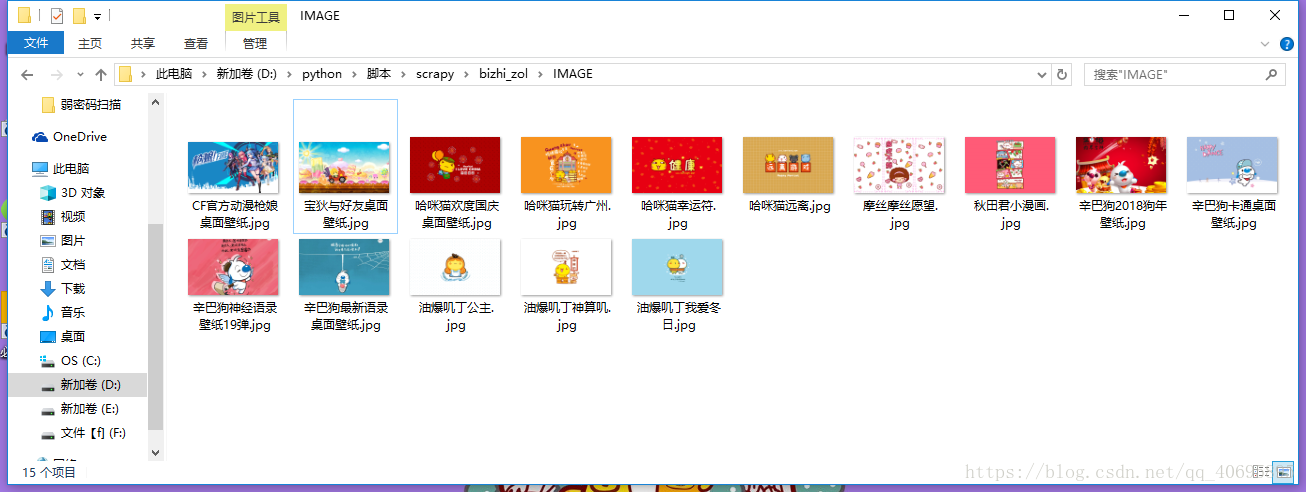
寫到這裡整個爬蟲程式就完成了,不過這個爬蟲程式只能爬取一頁的桌布,不能夠自動翻頁。要實現自動翻頁,就留給讀者自己動腦筋了(ps:自動翻頁很簡單,只需在原來程式碼的基礎上增加幾行程式碼就可以了)
上個圖: