
李巨集毅機器學習筆記
2018.10.09開始看李巨集毅的機器學習課,把重要的筆記記下來
-
各種模型之間的關係
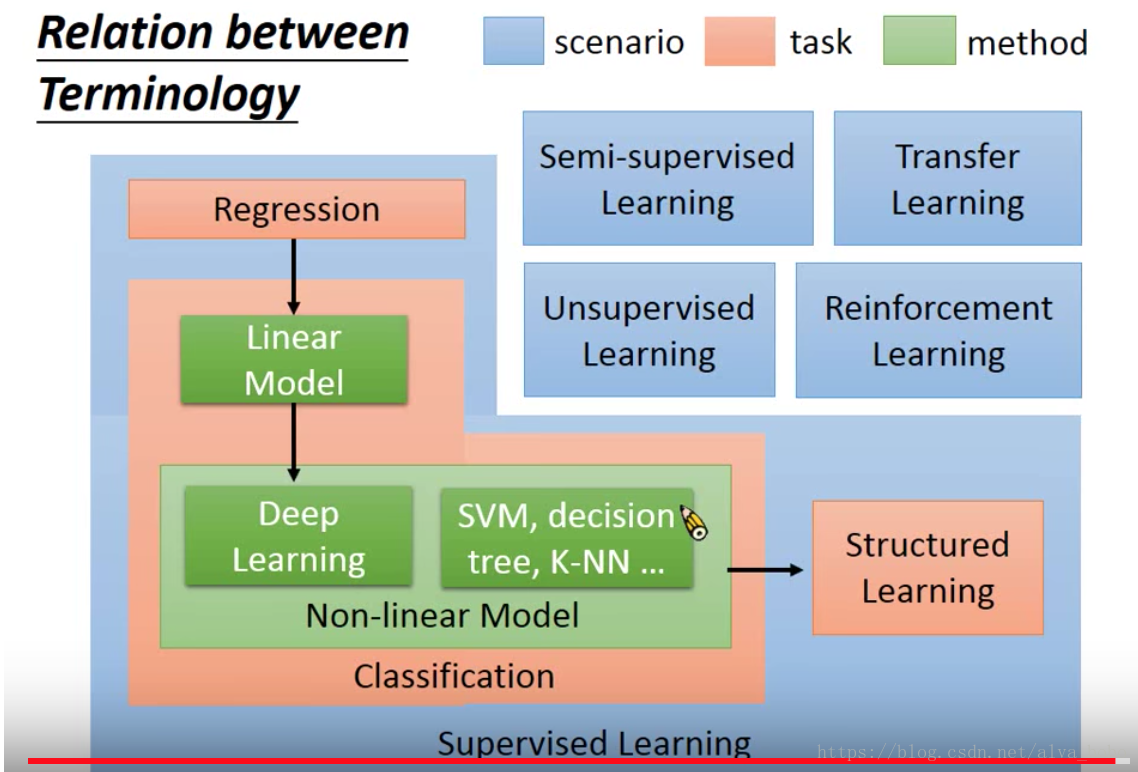
10月10日
-
為什麼要使用Regulation

正則專案的:使目標函式儘可能的平滑,儘量使Wi小一點
Wi小的比較好(因為輸入值有很大變化,對輸出的影響相對沒有那麼大)
λ越大,函式越平滑
但是λ太大了,就太平滑,不能正確擬合函數了
正則項不考慮b, 因為b對函式的平滑程度沒有影響
10月11日
bias VS variance

bias: 樣本點平均離中心遠近
variance: 樣本點有多散
| variance 大 | overfitting | 增加data, 正則化 |
| bias 大 | underfitting | 修正model(增加data沒用的) |
10.12
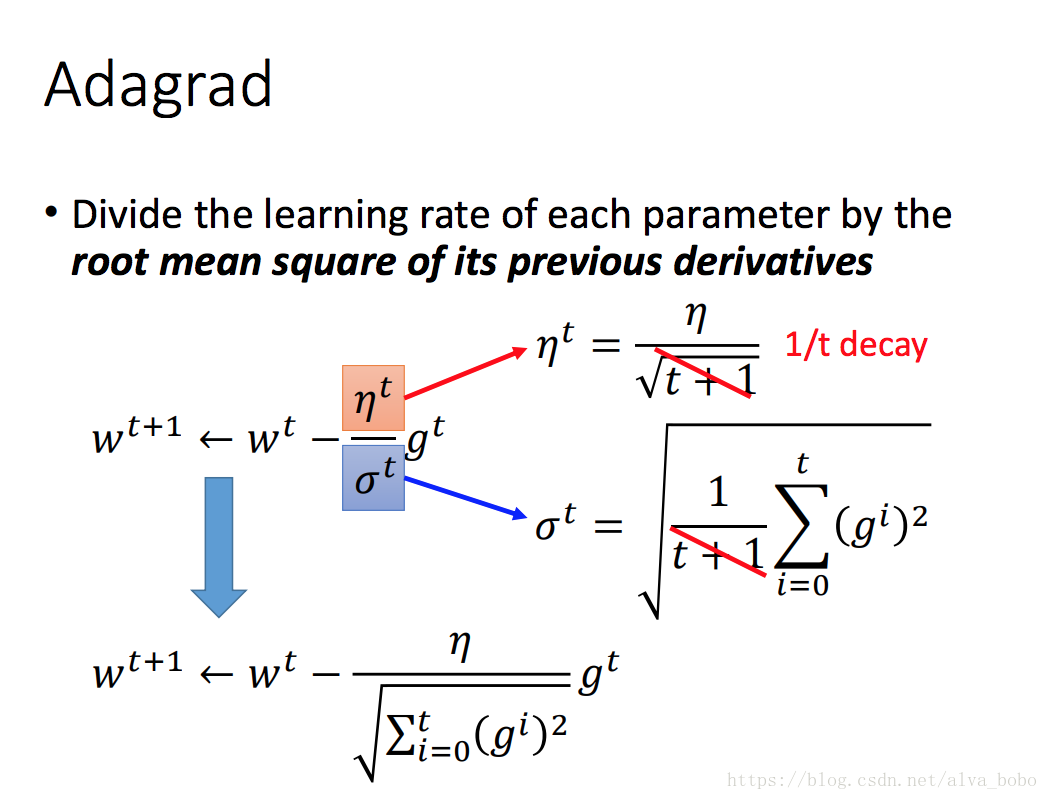
Adagrad: 考慮前面每一步的梯度,全域性學習率逐引數的除以歷史梯度平方和的平方根,使得每個引數的學習率不同

10 .17
Probabilistic Generative Model
找出一個分佈,最有可能選出目前已有的資料


相關推薦
【ML】 李巨集毅機器學習筆記
我的github連結 - 課程相關程式碼: https://github.com/YidaoXianren/Machine-Learning-course-note 0. Introduction Machine Learning: define a set of function
李巨集毅機器學習筆記——02.Where does the error come from ?
傳送門: 在上節課講到,如果選擇不同的function set就是選擇不同的model 在testing data上會得到不同的error,而且越複雜的model不見得會給你越低的error,我們要討論的問題就是error來自什麼地方? error有兩個來源,偏
[機器學習入門] 李巨集毅機器學習筆記-1(Learning Map 課程導覽圖)
在此就不介紹機器學習的概念了。 Learning Map(學習導圖) PDF VIDEO 先來看一張李大大的總圖↓ 鑑於看起來不是很直觀,我“照虎
[機器學習入門] 李巨集毅機器學習筆記-5(Classification- Probabilistic Generative Model;分類:概率生成模型)
[機器學習] 李巨集毅機器學習筆記-5(Classification: Probabilistic Generative Model;分類:概率生成模型) Classification
[機器學習入門] 李巨集毅機器學習筆記-15 (Unsupervised Learning: Word Embedding;無監督學習:詞嵌入)
[機器學習入門] 李巨集毅機器學習筆記-15 (Unsupervised Learning: Word Embedding;無監督學習:詞嵌入) PDF VIDEO
[機器學習入門] 李巨集毅機器學習筆記-6 (Classification: Logistic Regression;邏輯迴歸)
[機器學習] 李巨集毅機器學習筆記-6 (Classification: Logistic Regression;Logistic迴歸) PDF VIDEO Three steps Step 1: Function Set
[機器學習入門] 李巨集毅機器學習筆記-14 (Unsupervised Learning: Linear Dimension Reduction;無監督學習:線性降維)
[機器學習入門] 李巨集毅機器學習筆記-14 (Unsupervised Learning: Linear Dimension Reduction;線性降維) PDF VI
李巨集毅機器學習筆記-6 深度學習簡介(Brief Introduction of Deep Learning)
Brief Introduction of Deep Learning - 深度學習簡介 1. 前言 deep learning 在近些年非常熱門,從2012年開始,深度學習的應用數目幾乎是呈指數增長的。 深度學習的發展史如下圖:
李巨集毅機器學習筆記
2018.10.09開始看李巨集毅的機器學習課,把重要的筆記記下來 各種模型之間的關係 10月10日 為什麼要使用Regulation 正則專案的:使目標函式儘可能的平滑,儘量使Wi小一點 Wi小的
李巨集毅機器學習 P14 Backpropagation 筆記
chain rule:求導的鏈式法則。 接著上一節,我們想要minimize這個loss的值,我們需要計算梯度來更新w和b。 以一個neuron舉例: 這個偏微分的結果就是輸入x。 比如下面這個神經網路: 下面我們要計算這個偏微分:。這裡的以si
李巨集毅機器學習 P13 Brief Introduction of Deep Learning 筆記
deep learning的熱度增長非常快。 下面看看deep learning的歷史。 最開始出現的是1958年的單層感知機,1969年發現單層感知機有限制,到了1980年代出現多層感知機(這和今天的深度學習已經沒有太大的區別),1986年又出現了反向傳播演算法(通常超過3
李巨集毅機器學習 P12 HW2 Winner or Loser 筆記(不使用框架實現使用MBGD優化方法和z_score標準化的logistic regression模型)
建立logistic迴歸模型: 根據ADULT資料集中一個人的age,workclass,fnlwgt,education,education_num,marital_status,occupation等資訊預測其income大於50K或者相反(收入)。 資料集: ADULT資料集。
李巨集毅機器學習P11 Logistic Regression 筆記
我們要找的是一個概率。 f即x屬於C1的機率。 上面的過程就是logistic regression。 下面將logistic regression與linear regression作比較。 接下來訓練模型,看看模型的好壞。 假設有N組trainin
李巨集毅機器學習 P15 “Hello world” of deep learning 筆記
我們今天使用Keras來寫一個deep learning model。 tensorflow實際上是一個微分器,它的功能比較強大,但同時也不太好學。因此我們學Keras,相對容易,也有足夠的靈活性。 李教授開了一個玩笑: 下面我們來寫一個最簡單的deep learning mo
李巨集毅機器學習P7 Gradient Descent (Demo by AOE) 筆記、P8 Gradient Descent (Demo by Minecraft) 筆記
P7 Gradient Descent (Demo by AOE) 筆記: 在進行Gradient Decent時,我們可以類似玩遊戲帝國時代時探索地圖的情況。 在地圖沒有探索前,你的視野範圍只有很小的一個圈,你不知道圈外的黑幕下面有什麼東西。 現在我們假設地圖上的海拔
李巨集毅機器學習-學習筆記
function set就是model 機器學習3大步驟: 1. 定義模型(function)集合 2. 指定模型(function)好壞的評價指標 3. 通過演算法選擇到最佳的模型(function) alphago下棋模型抽象為棋局向下一步的分類問題: 減少擁有label的data用量的方法: 1.
2018-3-21李巨集毅機器學習視訊筆記(十三)--“Hello Wrold” of Deep learning
Keras:有關的介紹:總的來說就是一個深度學習框架keras - CSDN部落格https://blog.csdn.net/xiaomuworld/article/details/52076202軟體工程中的框架:一種可複用的設計構件(從巨集觀上大體結構的一種規定約束)軟體
李巨集毅機器學習課程筆記10:Ensemble、Deep Reinforcement Learning
臺灣大學李巨集毅老師的機器學習課程是一份非常好的ML/DL入門資料,李巨集毅老師將課程錄影上傳到了YouTube,地址:NTUEE ML 2016 。 這篇文章是學習本課程第27-28課所做的筆記和自己的理解。 Lecture 27: Ensembl
李巨集毅機器學習 P18 Tips for Training DNN 筆記
假如deep learning得到不好的結果,應該從哪個方向進行改進呢? 首先檢查neural network在training data上是否得到好的結果。 如果在training data上得到好的結果,而在testing data上沒有得到好的結果,那麼這種
李巨集毅機器學習課程筆記9:Recurrent Neural Network
臺灣大學李巨集毅老師的機器學習課程是一份非常好的ML/DL入門資料,李巨集毅老師將課程錄影上傳到了YouTube,地址:NTUEE ML 2016 。 這篇文章是學習本課程第25-26課所做的筆記和自己的理解。 Lecture 25,26: Recu