
李巨集毅機器學習 P18 Tips for Training DNN 筆記

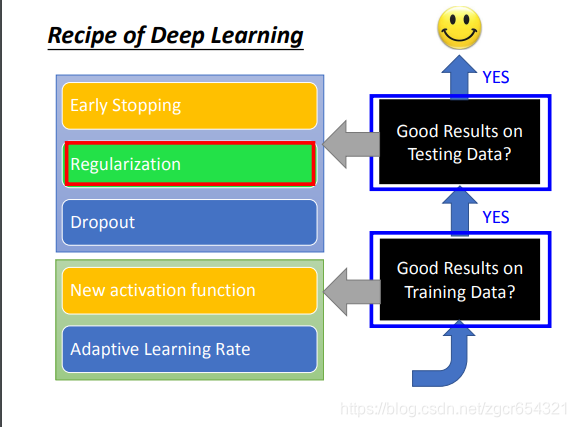
假如deep learning得到不好的結果,應該從哪個方向進行改進呢?
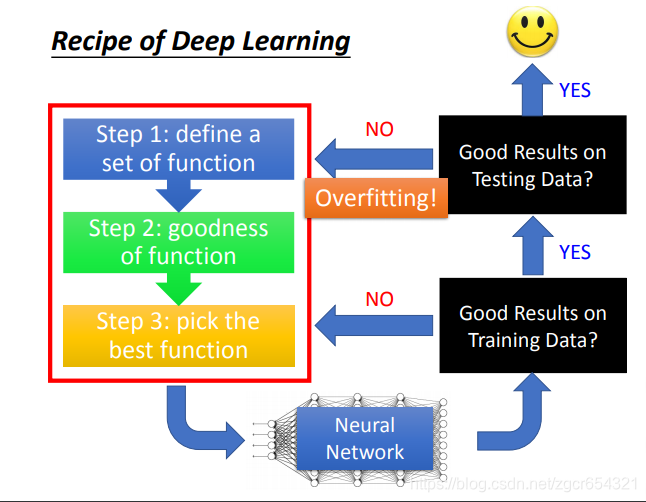
首先檢查neural network在training data上是否得到好的結果。
如果在training data上得到好的結果,而在testing data上沒有得到好的結果,那麼這種情況就叫做overfitting。
如果在training data和testing data上都能得到好的結果,那麼你就得到一個可以用的模型。
注意在神經網路層數不同時,層數更多的網路需要更多的訓練次數才能訓練好,如果比較兩個層數不同的模型時,有時會發現一個層數少的模型的training error比層數多的模型還要下降的快,但這種情況有可能只是層數深的模型還沒有訓練好,需要更多訓練次數。
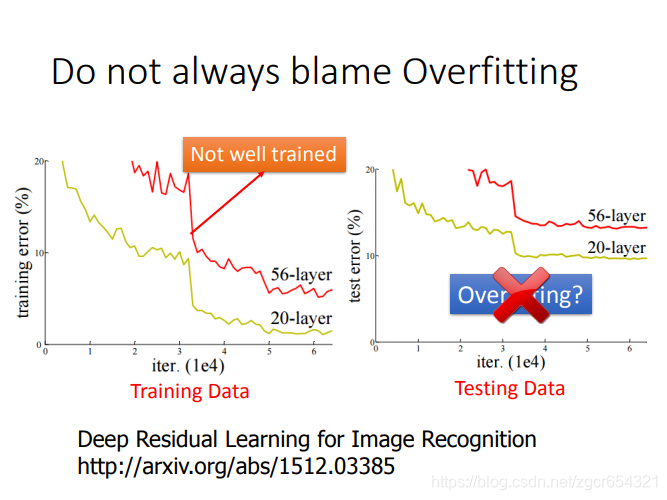
當然層數深的模型也不一定就比層數淺的模型表現要好。
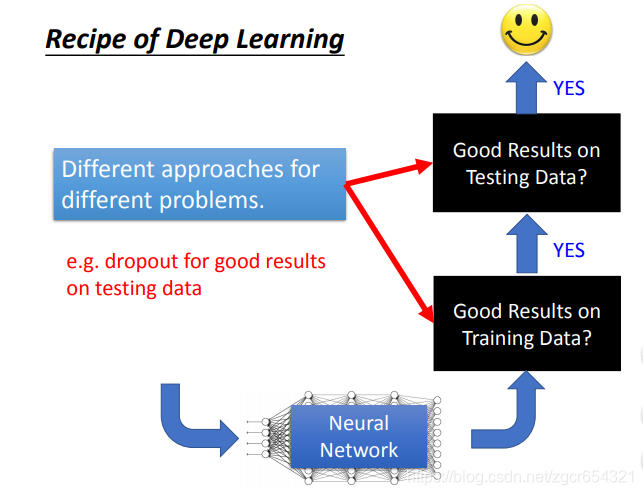
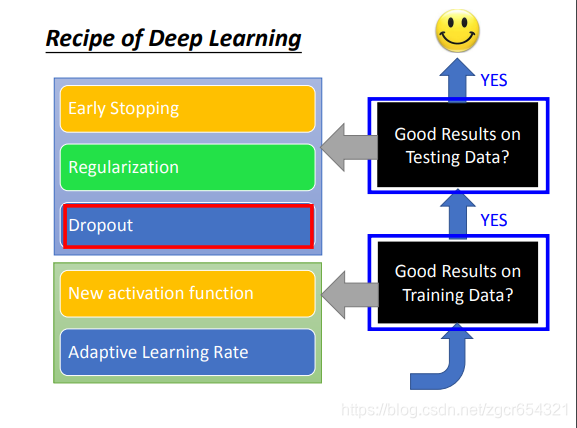
不同的方法應對不同的情況。有的是為了提升training set上的表現,而有的是提升testing set上的表現。
比如dropout是為了提升在testing set上的表現,而會使在training set上的表現變差。
有哪些常用的方法:

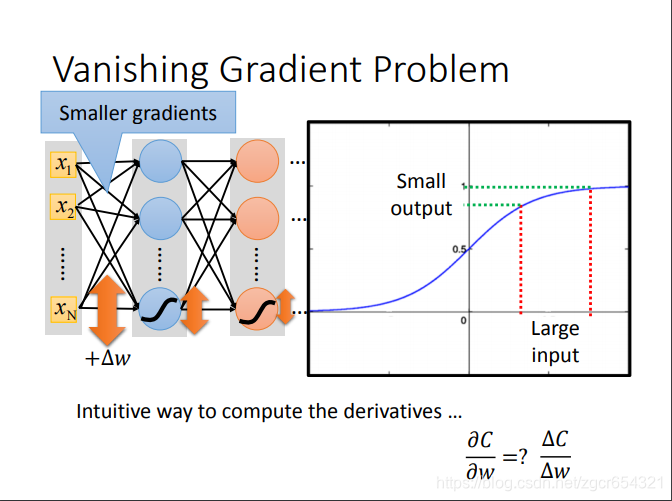
網路層數越深,表現不一定會更好。(梯度消失現象)梯度越小學習速度越慢。

梯度消失現象:由於反向傳播的梯度是鏈式法則求導,最前面幾層的學習率會越來越小,這樣後面的loss到達local minima時,前面幾層的權重還未學習到最合適的值。這也是啟用函式從sigmoid函式改動relu函式的原因。

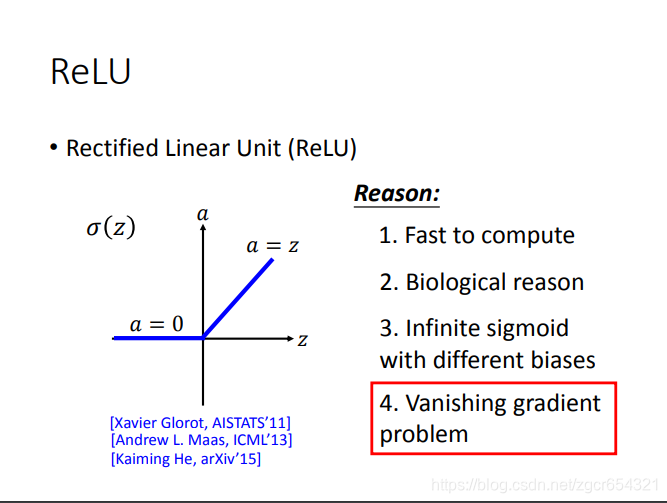
看sigmoid函式的特性:input變化很大時,output的變化相對來說並不大。
而relu函式則不會發生這樣的情況,因為它的函式是下面這樣的:
即輸入值大於0,則輸出等於輸入值;輸入值小於0,則輸出值為0。
比如現在有一個兩層的模型,都用relu作啟用函式:
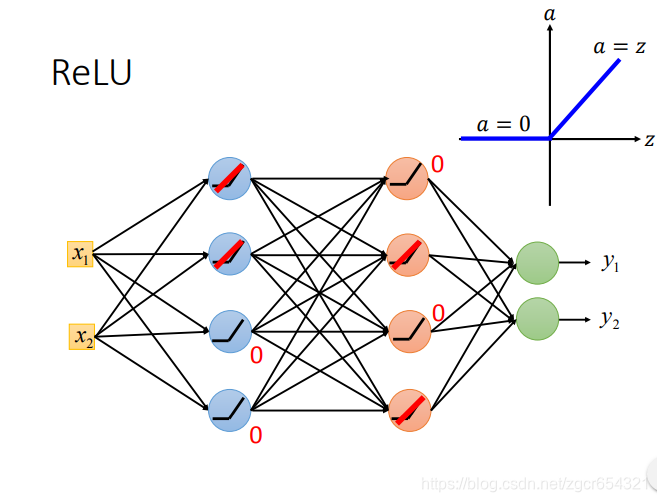
對於input大於0的神經元,這個神經元就相當於線性變換;對於input小於0的神經元,這個神經元的輸出就是0,在反向傳播的時候,計算這裡引數的梯度是0,也就相當於不用更新。
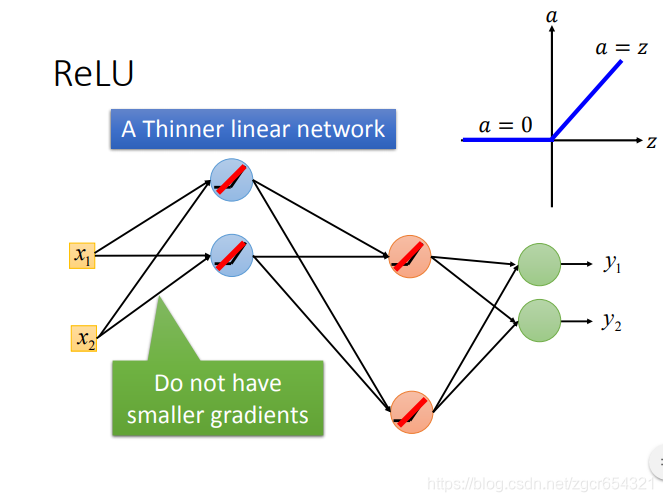
如果是線性的變換,那麼就不會出現梯度消失的問題。這樣這個模型中只有一部分神經元是線性的,而且不同層中作線性變換的神經元不一樣,這樣對於整個模型來說,模型就不是線性的,這樣模型就可以模擬非線性的情況。
relu還有很多變形:
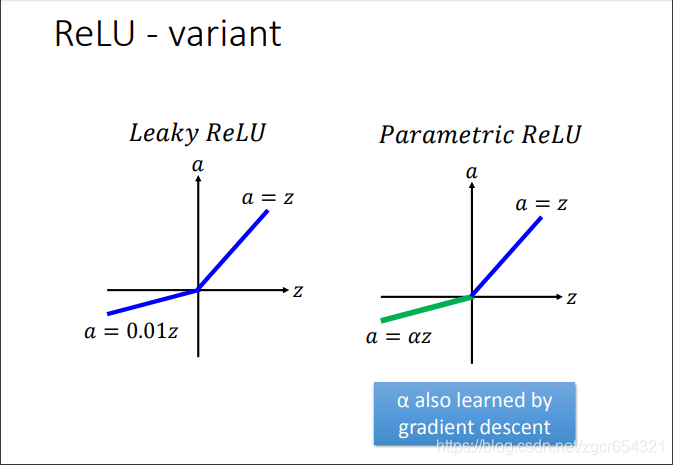
除此之外,還有之後提出來的ELU啟用函式。
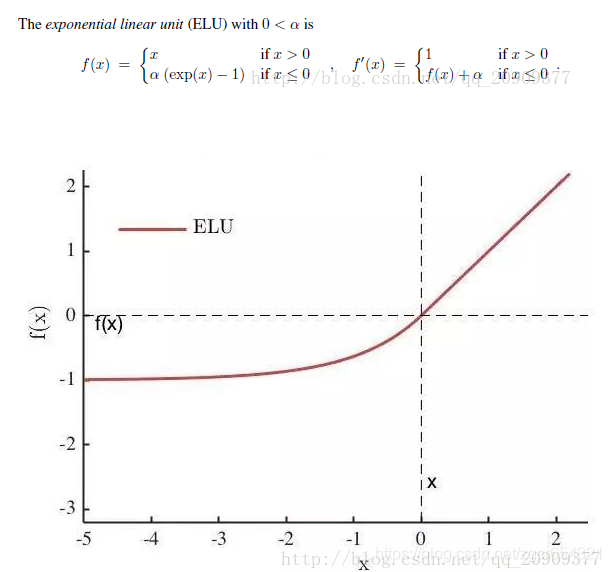
其中α是一個可調整的引數,它控制著ELU負值部分在何時飽和。
右側線性部分使得ELU能夠緩解梯度消失,而左側軟飽能夠讓ELU對輸入變化或噪聲更具有魯棒性。
ELU的輸出均值接近於零,所以收斂速度更快。
事實上,Relu是Maxout的一種特殊情況。
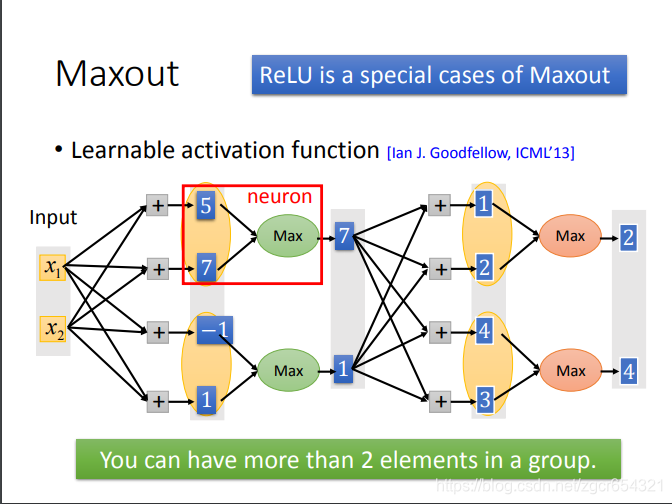
Maxout就是自動學習啟用函式。模型可以自己學習每個神經元需要什麼樣的啟用函式。
Maxout的原理:
比如上圖x1和x2分別與4個神經元做運算,得到4個輸出值,正常情況下,這4個輸出值應該都要再經過啟用函式的計算。
而在Maxout中是將這4個值分兩組,第一組取其中最大值7,第二組取其中最大值1(有點像池化操作)。
後面一層的做法也類似。
為什麼Maxout可以對不同的神經元產生不同的啟用函式?
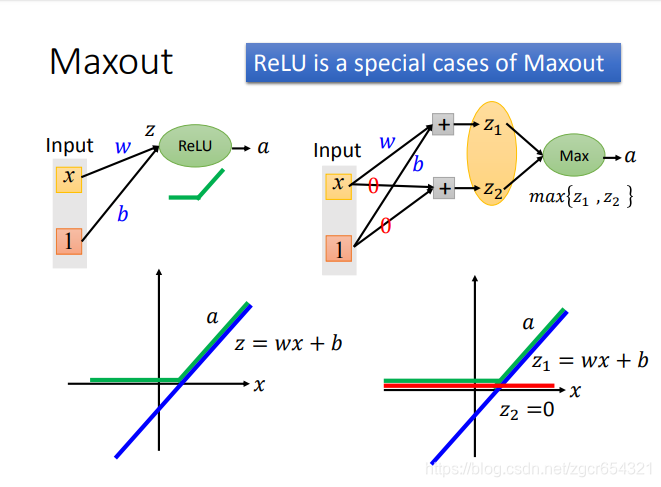
如果啟用函式是relu時:
z=wx+b,是左圖上的藍色直線,是線性的。
而a是z經過relu處理的值,這時a就不是線性的了。
如果採用Maxout:
我們先計算出z1和z2,然後取max{z1,z2}。
我們可以看到z1和左圖的藍色直線一樣,而z2是z2=0的直線。
這樣我們可以發現通過max{z1,z2}所得的值在x的整個區間上就和relu函式得到的值一模一樣了。
這就是用Maxout學習出來的啟用函式就和relu函式一模一樣了。對其他的啟用函式也類似。
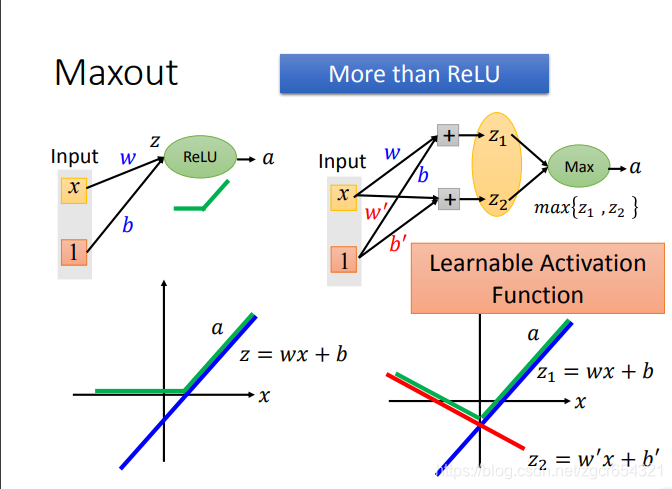
當然我們要注意Maxout學習出來的啟用函式是分段的線性函式。
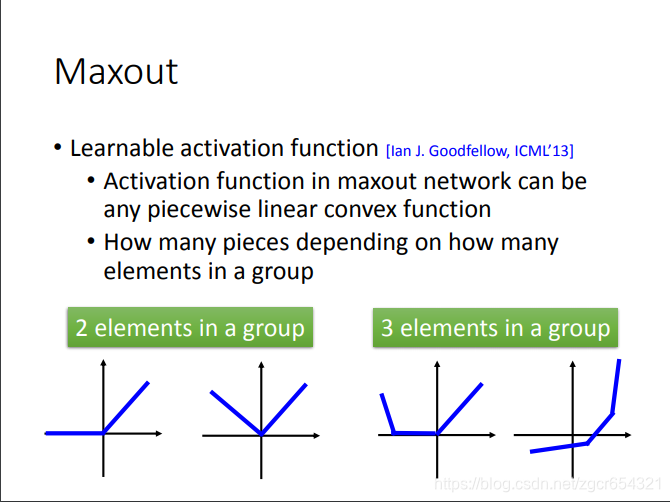
有多少段就取決於你的分組中有多少個神經元。
如何去train這個Maxout呢?

Maxout是可以train的。給定一組輸入值x1和x2,我們假設紅框是每個分組裡的最大值,那麼train引數時就將分組中其他較小的值當做不存在,這時我們就發現Maxout還是一個線性的函式,我們就可以用反向傳播演算法來更新每層的權重了。
而分組的其他值在其他不同的輸入值時可能是最大值,故在其他不同的輸入值時,它們也可以用反向傳播演算法來更新權重。
自適應學習率:
Adagrad的公式:
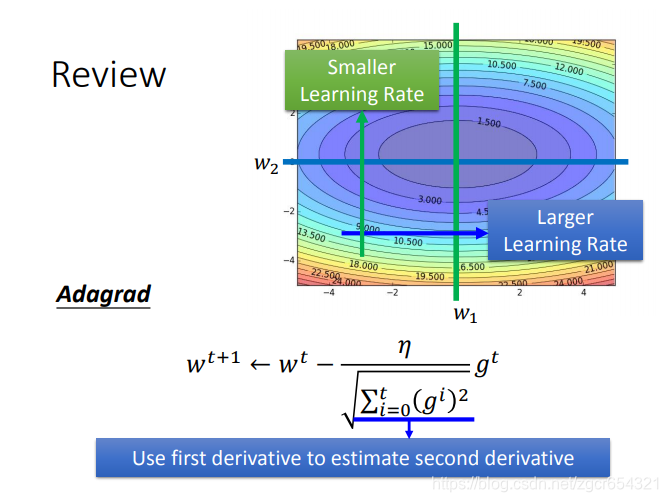
有時候我們需要不同的學習率。
我們可以看到在w2值不同時需要的learning rate的大小不同。
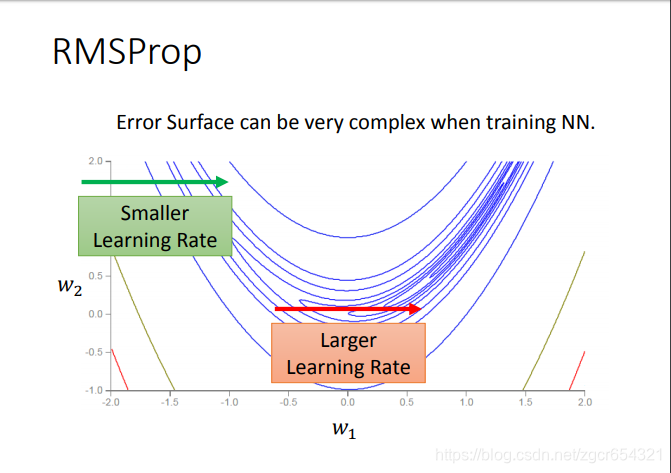
這時候我們就要用RMSProp方法了。
RMSProp方法:

這個方法的核心就是在梯度越平坦的方向步子越大,梯度越陡峭的方向步子越小。
RMSProp與Adagrad的區別:
這是Adagrad:

這是RMSProp:
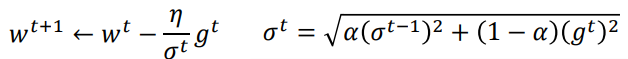
實際上就是分母由原來的所有步次的梯度和改為![]() 。(更多考慮上一步梯度的影響)
。(更多考慮上一步梯度的影響)

Momentum方法:
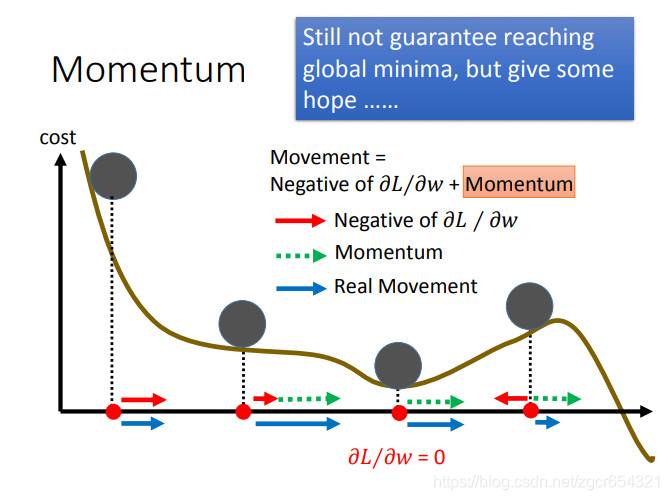

Momentum其實就是保留了上一步的梯度的跨步的幅度。
複習:一般的梯度下降方法:
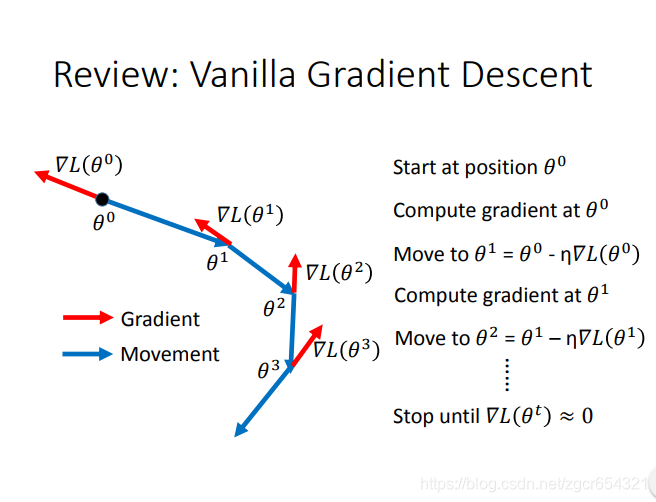
如果把RMSProp和Momentum的合併起來,就是Adam演算法。

如何在testing data上也具有比較好的表現?
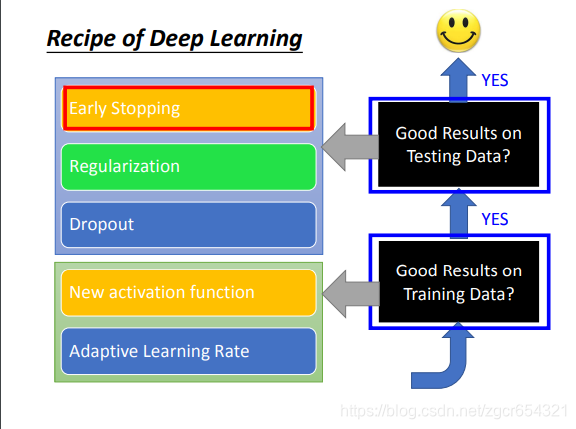
我們可以使用validation set來測試其testing error,這樣可以及早在testing error升高前停下來。
實際應用時,就是train一段時間就用validation set來測試一下模型。

正則化也可以用來減少testing error。
如L2正則化:

其做梯度下降時:

加上正則項時,更新引數時,現在前面是![]() 。前面括號內總是一次小於1的項,這樣wt每次都會越來越小。
。前面括號內總是一次小於1的項,這樣wt每次都會越來越小。
後面這項 會與前面這項取得平衡。
會與前面這項取得平衡。
L1正則化:

dropout方法:
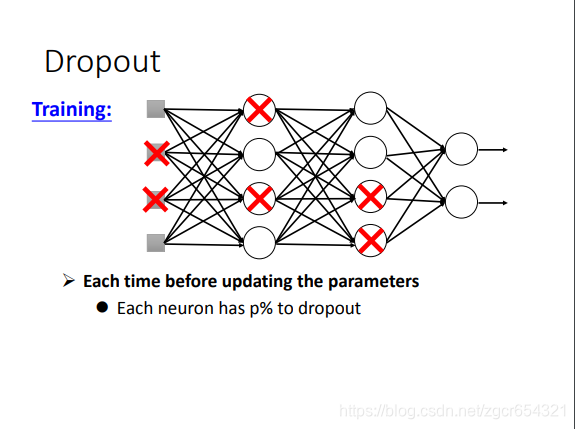
dropout就是丟掉一部分神經元的輸出值。然後將剩下的輸出值輸入下一層。
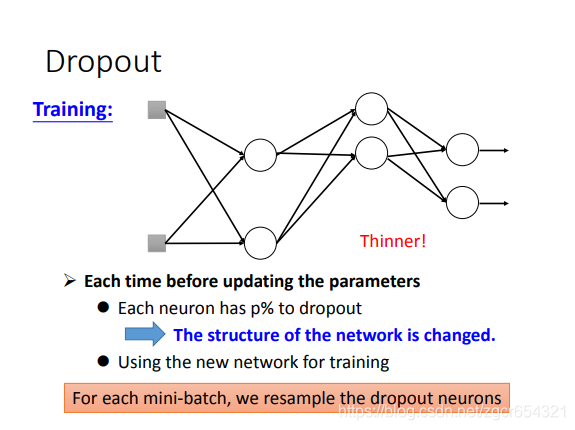
注意:
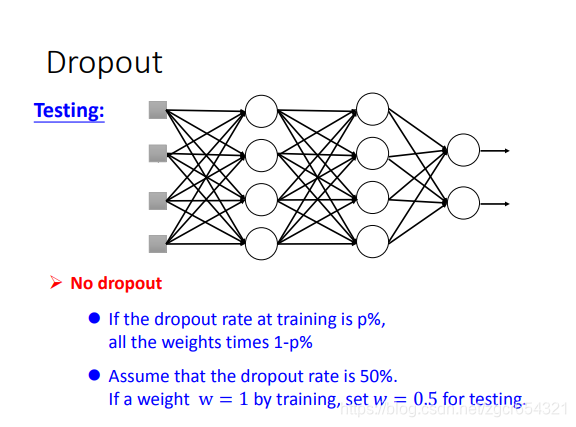
testing的時候是不dropout的。training時才dropout。
訓練時多批樣本會將所有神經元的權重都訓練到,不需要擔心訓練不到的情況。
dropout可以看作是一種ensemble的方式。
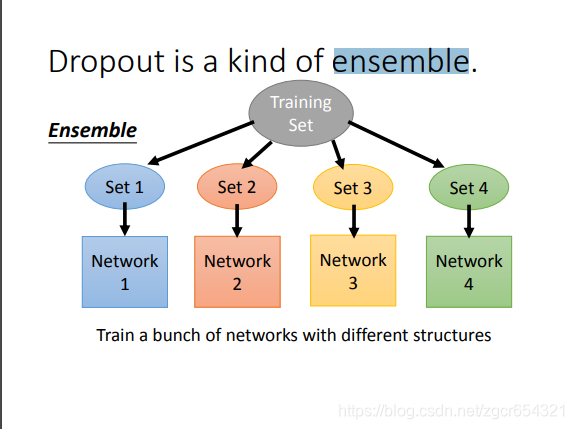
如果一個模型中有m個神經元,則經過dropout後可能產生2的m次方個的模型。

每一個模型都用一個minibath的樣本去train它。注意它們的引數是共用的。所有的模型的引數拼起來就是完整的網路中的所有引數。
而在test時:
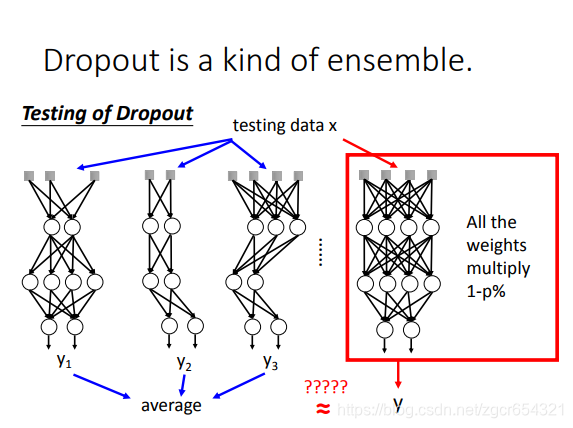
test時,所有的weights都乘以1-p%。
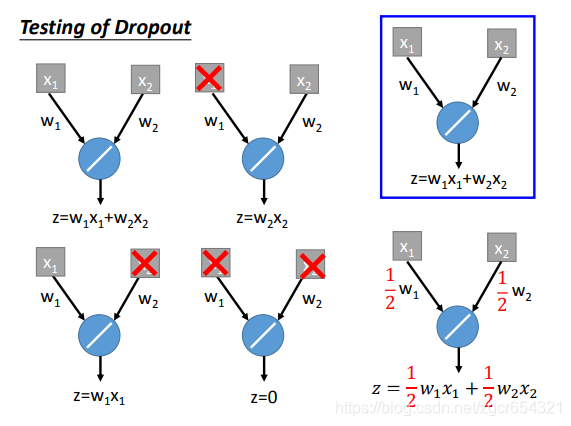
舉例:
相關推薦
李巨集毅機器學習 P18 Tips for Training DNN 筆記
假如deep learning得到不好的結果,應該從哪個方向進行改進呢? 首先檢查neural network在training data上是否得到好的結果。 如果在training data上得到好的結果,而在testing data上沒有得到好的結果,那麼這種
李巨集毅機器學習 P12 HW2 Winner or Loser 筆記(不使用框架實現使用MBGD優化方法和z_score標準化的logistic regression模型)
建立logistic迴歸模型: 根據ADULT資料集中一個人的age,workclass,fnlwgt,education,education_num,marital_status,occupation等資訊預測其income大於50K或者相反(收入)。 資料集: ADULT資料集。
【ML】 李巨集毅機器學習筆記
我的github連結 - 課程相關程式碼: https://github.com/YidaoXianren/Machine-Learning-course-note 0. Introduction Machine Learning: define a set of function
李巨集毅機器學習 P14 Backpropagation 筆記
chain rule:求導的鏈式法則。 接著上一節,我們想要minimize這個loss的值,我們需要計算梯度來更新w和b。 以一個neuron舉例: 這個偏微分的結果就是輸入x。 比如下面這個神經網路: 下面我們要計算這個偏微分:。這裡的以si
李巨集毅機器學習 P13 Brief Introduction of Deep Learning 筆記
deep learning的熱度增長非常快。 下面看看deep learning的歷史。 最開始出現的是1958年的單層感知機,1969年發現單層感知機有限制,到了1980年代出現多層感知機(這和今天的深度學習已經沒有太大的區別),1986年又出現了反向傳播演算法(通常超過3
李巨集毅機器學習P11 Logistic Regression 筆記
我們要找的是一個概率。 f即x屬於C1的機率。 上面的過程就是logistic regression。 下面將logistic regression與linear regression作比較。 接下來訓練模型,看看模型的好壞。 假設有N組trainin
李巨集毅機器學習 P15 “Hello world” of deep learning 筆記
我們今天使用Keras來寫一個deep learning model。 tensorflow實際上是一個微分器,它的功能比較強大,但同時也不太好學。因此我們學Keras,相對容易,也有足夠的靈活性。 李教授開了一個玩笑: 下面我們來寫一個最簡單的deep learning mo
線性迴歸 李巨集毅機器學習HW1
本文是李巨集毅老師機器學習的第一次大作業,參考網上程式碼,寫了一下自己的思路。 李巨集毅 HM1: 要求:本次作業使用豐原站的觀測記錄,分成train set跟test set,train set是豐原站每個月的 前20天所有資料。test set則是從豐原站剩下的資料中取樣出來。 trai
李巨集毅機器學習課程--迴歸(Regression)
李老師用的是精靈寶可夢做的比喻,假設進化後的寶可夢的cp值(Combat Power)與未進化之前的寶可夢的cp值相關,我們想找出這兩者之間的函式關係,可以設進化後的cp值為y,進化之前的cp值為x:y = b + w*x (不只可以設一次項,還可以設定二次項,三次項
李巨集毅機器學習P7 Gradient Descent (Demo by AOE) 筆記、P8 Gradient Descent (Demo by Minecraft) 筆記
P7 Gradient Descent (Demo by AOE) 筆記: 在進行Gradient Decent時,我們可以類似玩遊戲帝國時代時探索地圖的情況。 在地圖沒有探索前,你的視野範圍只有很小的一個圈,你不知道圈外的黑幕下面有什麼東西。 現在我們假設地圖上的海拔
李巨集毅機器學習PTT的理解(1)深度學習的介紹
深度學習的介紹 機器學習就像是尋找一個合適的函式,我們輸入資料就可以得到想要的結果,比如: 在語音識別中,我們輸入一段語音,函式的輸出值就是識別的結果;在影象識別中,輸入一張照片,函式可以告訴我們分類
卷積神經網路CNN |李巨集毅機器學習
2018年11月10日 15:29:22 小辣油 閱讀數:8 個人分類: 李巨集毅
李巨集毅機器學習筆記——02.Where does the error come from ?
傳送門: 在上節課講到,如果選擇不同的function set就是選擇不同的model 在testing data上會得到不同的error,而且越複雜的model不見得會給你越低的error,我們要討論的問題就是error來自什麼地方? error有兩個來源,偏
李巨集毅機器學習-學習筆記
function set就是model 機器學習3大步驟: 1. 定義模型(function)集合 2. 指定模型(function)好壞的評價指標 3. 通過演算法選擇到最佳的模型(function) alphago下棋模型抽象為棋局向下一步的分類問題: 減少擁有label的data用量的方法: 1.
李巨集毅機器學習2016 第八講 深度學習網路優化小訣竅
Tips for Deep Learning 本章節主要講解了深度學習中的一些優化策略,針對不同的情況適用於不同的優化方法。 主要內容是:新的啟用函式(new activation function),自適應的學習率(adaptive learning
[機器學習入門] 李巨集毅機器學習筆記-1(Learning Map 課程導覽圖)
在此就不介紹機器學習的概念了。 Learning Map(學習導圖) PDF VIDEO 先來看一張李大大的總圖↓ 鑑於看起來不是很直觀,我“照虎
李巨集毅機器學習2016 第十五講 無監督學習 生成模型之 VAE
Unsupervised Learning : Generation本章主要講解了無監督學習中的生成模型方法。1.生成模型(Generative Models)“What I cannot create, I do not understand.” ——Richard Fey
[機器學習入門] 李巨集毅機器學習筆記-5(Classification- Probabilistic Generative Model;分類:概率生成模型)
[機器學習] 李巨集毅機器學習筆記-5(Classification: Probabilistic Generative Model;分類:概率生成模型) Classification
[機器學習入門] 李巨集毅機器學習筆記-15 (Unsupervised Learning: Word Embedding;無監督學習:詞嵌入)
[機器學習入門] 李巨集毅機器學習筆記-15 (Unsupervised Learning: Word Embedding;無監督學習:詞嵌入) PDF VIDEO
2018-3-21李巨集毅機器學習視訊筆記(十三)--“Hello Wrold” of Deep learning
Keras:有關的介紹:總的來說就是一個深度學習框架keras - CSDN部落格https://blog.csdn.net/xiaomuworld/article/details/52076202軟體工程中的框架:一種可複用的設計構件(從巨集觀上大體結構的一種規定約束)軟體