
深度學習反向傳播---隨機梯度下降法
一、誤差準則函式與隨機梯度下降:
數學一點將就是,對於給定的一個點集(X,Y),找到一條曲線或者曲面,對其進行擬合之。同時稱X中的變數為特徵(Feature),Y值為預測值。
如圖:
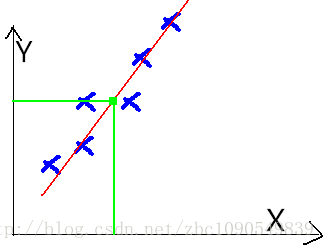
一個典型的機器學習的過程,首先給出一組輸入資料X,我們的演算法會通過一系列的過程得到一個估計的函式,這個函式有能力對沒有見過的新資料給出一個新的估計Y,也被稱為構建一個模型。
我們用X1、X2...Xn 去描述feature裡面的分量,用Y來描述我們的估計,得到一下模型:
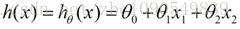
我們需要一種機制去評價這個模型對資料的描述到底夠不夠準確,而採集的資料x、y通常來說是存在誤差的(多數情況下誤差服從高斯分佈),於是,自然的,引入誤差函式:
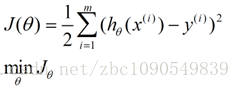
關鍵的一點是如何調整theta值,使誤差函式J最小化。J函式構成一個曲面或者曲線,我們的目的是找到該曲面的最低點:
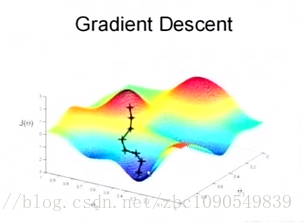
假設隨機站在該曲面的一點,要以最快的速度到達最低點,我們當然會沿著坡度最大的方向往下走(梯度的反方向)
用數學描述就是一個求偏導數的過程:
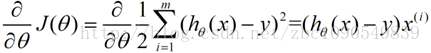
這樣,引數theta的更新過程描述為以下:
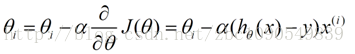
二、不同梯度下降演算法的區別:
-
梯度下降:梯度下降就是我上面的推導,要留意,在梯度下降中,對於的更新,所有的樣本都有貢獻,也就是參與調整.其計算得到的是一個標準梯度。因而理論上來說一次更新的幅度是比較大的。如果樣本不多的情況下,當然是這樣收斂的速度會更快啦~
-
隨機梯度下降:可以看到多了隨機兩個字,隨機也就是說我用樣本中的一個例子來近似我所有的樣本,來調整,因而隨機梯度下降是會帶來一定的問題,因為計算得到的並不是準確的一個梯度,容易陷入到區域性最優解中
-
批量梯度下降:其實批量的梯度下降就是一種折中的方法,他用了一些小樣本來近似全部的,其本質就是我1個指不定不太準,那我用個30個50個樣本那比隨機的要準不少了吧,而且批量的話還是非常可以反映樣本的一個分佈情況的。
三、演算法實現與測試:
通過一組資料擬合 y = theta1*x1 +theta2*x2
- #Python 3.3.5
- import random
- # matrix_A 訓練集
- matrix_A = [[1,4], [2,5], [5,1], [4,2]]
- Matrix_y = [19,26,19,20]
- theta = [2,5]
- #學習速率
- leraing_rate = 0.005
- loss = 50
- iters = 1
- Eps = 0.0001
- #隨機梯度下降
- while loss>Eps and iters <1000 :
- loss = 0
- i = random.randint(0, 4)
- h = theta[0]*matrix_A[i][0] + theta[1]*matrix_A[i][1]
- theta[0] = theta[0] + leraing_rate*(Matrix_y[i]-h)*matrix_A[i][0]
- theta[1] = theta[1] + leraing_rate*(Matrix_y[i]-h)*matrix_A[i][1]
- Error = 0
- Error = theta[0]*matrix_A[i][0] + theta[1]*matrix_A[i][1] - Matrix_y[i]
- Error = Error*Error
- loss = loss +Error
- iters = iters +1
- print ('theta=',theta)
- print ('iters=',iters)
- """
- #梯度下降
- while loss>Eps and iters <1000 :
- loss = 0
- for i in range(4):
- h = theta[0]*matrix_A[i][0] + theta[1]*matrix_A[i][1]
- theta[0] = theta[0] + leraing_rate*(Matrix_y[i]-h)*matrix_A[i][0]
- theta[1] = theta[1] + leraing_rate*(Matrix_y[i]-h)*matrix_A[i][1]
- for i in range(4):
- Error = 0
- Error = theta[0]*matrix_A[i][0] + theta[1]*matrix_A[i][1] - Matrix_y[i]
- Error = Error*Error
- loss = loss +Error
- iters = iters +1
- print ('theta=',theta)
- print ('iters=',iters)
- """
- """
- #批量梯度下降
- while loss>Eps and iters <1000 :
- loss = 0
- sampleindex = random.sample([0,1,2,3],2)
- for i in sampleindex :
- h = theta[0]*matrix_A[i][0] + theta[1]*matrix_A[i][1]
- theta[0] = theta[0] + leraing_rate*(Matrix_y[i]-h)*matrix_A[i][0]
- theta[1] = theta[1] + leraing_rate*(Matrix_y[i]-h)*matrix_A[i][1]
- for i in sampleindex :
- Error = 0
- Error = theta[0]*matrix_A[i][0] + theta[1]*matrix_A[i][1] - Matrix_y[i]
- Error = Error*Error
- loss = loss +Error
- iters = iters +1
- print ('theta=',theta)
- print ('iters=',iters)
- """
求解結果:
- >>>
- theta= [2.9980959216157945, 4.001522800837675]
- iters= 75
- matrix_A = [[1.05,4], [2.1,5], [5,1], [4,2]]
- >>>
- theta= [3.0095950685197725, 3.944718521027671]
- iters= 1000