
Cassandra的一致性雜湊(Consistent Hashing)和虛擬節點(Virtual Nodes)的關係
一致性雜湊所要解決的問題
一般的雜湊演算法存在的問題是:當“模”發生變化時,所有的值都需要重新雜湊,而一致性雜湊演算法的特別之處就是它能把這種變化帶來的影響降低到最小。關於這一點不再贅述,可以參考http://www.cnblogs.com/haippy/archive/2011/12/10/2282943.html,講的非常明白。簡單地說,就是在新增和刪除節點的時候,只有失效節點上的資料會受影響,需要重新雜湊,所有其他的節點的資料的都不受影響。
一致性雜湊和虛擬節點的關係
為了理清現兩者之間的關係,讓我們先分開考慮。下圖是Cassandra官方文件中提供的一致性雜湊和虛擬節點的對比圖,上半部分是單純使用一致性雜湊的情形,下圖是一致性雜湊+虛擬節點的情形。
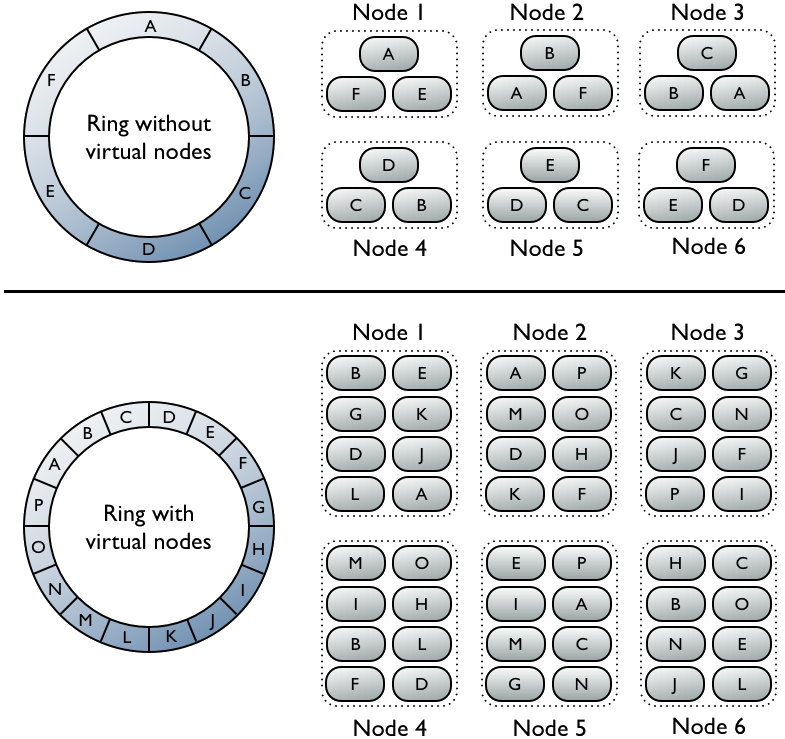
關於上半部分,首先每個節點只對應一個分割槽,1->A,2->B,…,然後,你可以看到,資料的副本都是連續儲存的,就是說A的三份副本一定是放在結點1,2,3上,B的三份副本一定是放在結點2,3,4上,依次類推, 這樣做的目的也是適應一致性雜湊演算法的需要,因為當某一節點失效時,比如Node 1, A區間會併入B區間,演算法會引導客戶去緊鄰的下一個節點也就是Node 2上去讀寫資料,所以在一開始,我們就讓Node 2來冗餘Node 1的資料,就是為這個場景做準備。
再來看下半部分,讓我們先忽略虛擬節點的存在,假定整個區間就被切分成了16個區間,對應16個物理節點,需要強調的是這時的區間(虛擬節點)依然是連續排列的),一致性雜湊演算法依然工作如初。現在,假定我們用6臺高效能的物理機替換現有的16臺物理機,原有的16個分割槽(也包括它們的副本)將分配或者對映到這6臺機器上。需要特別註明的是,根據官方文件的表述,這種分配或者對映的過程是隨機的,且不像單純使用一致性雜湊時那樣是把副本分配到本連續的節點上的(randomly selected and non-contiguous),基於這種新情形,讓我們重新分析一下資料的讀寫過程:如果一條資料屬於虛擬節點A,則寫入時會同步寫入虛擬節點B和虛擬節點C(這裡我們假定replia的數量是3),當虛擬節點A失效(其實是虛擬節點A對應的物理節點失效)時,系統會去下一個臨近節點B去讀寫冗餘資料,應該說到目前為止,都來還是按照一致性雜湊的邏輯在進行,與未引入虛擬node之前沒有任何差異,接下來不同的就是:B只是一個虛擬節點,系統需要從虛擬節點<->物理節點的對映關係中找到B對應的物理節點之後,再進行讀寫,這是引入虛擬節點之後的不同之處,也就是多了一步二次對映的計算過程。
那麼引入虛擬節點之後到底帶來了什麼收益呢?總的來說,引入VNode的主要收益是在系統的拓撲結構發生變化和重建節點時可以保證整個系統的高可用性。關於一點,《Cassandra 3.x High Availability, 2nd Edition》一書有一幅插圖形象地說明了問題。
下圖是重建Node 2節點的示意圖,Node 2儲存的3份資料副本F,B,A分別從Node 1,4,3上獲取,也就是說只有1,4,3節點參與了Node 2的重建,整體上看這帶給1,4,3節點比較大的負載,如果5,6兩個節點可以參與的話無疑會分攤一些壓力。同樣地,我們也可以用這個圖來考慮一下Node 2失效時的情形,那就所以對B的請求會轉嫁到Node 3上,這會使Node 3的負載增加一倍。

我們再來對比地看一下采用虛擬節點之後的情形:同樣考慮Node 2重建的過程,它上面的8個數據分割槽將來自全部已存在的節點,也就是說所有節點都參與了Node 2的重建,最而最大限度地分攤了系統負載。一樣的,當Node 2失效時,存放在上面的兩個(或三個)分割槽會由另外的兩個(或三個)節點接管,這和前面由單一節點接管相比也分攤了系統的負載。

小結
無論是否引入虛擬節點,一致性雜湊一直工作於Canssandra上,它解決的主要問題是避免節點(模)失效時導致所有已存在的hash對映關係失效。
虛擬節點的作用在於:讓物理節點host更多個分割槽(即多個虛擬節點),由於每一個分割槽都有另外多份副本放在另外多個物理節點上,這帶來的實際效果是密切了各個物理節點之間的關聯性,從互為主被的角度來看,就如同將每一個節點和所有其他節點連上線,形成了N*N的關聯關係,每一個物理節點都可能包含所有其他節點的某一小部分資料副本,所以每個節點都有可能參與到任意節點的重建工作中去,而當某一節點失效,所有其他節點都有可能來分攤失效節點的負載。總結起來,引入虛擬節點的收益是:
- 無需為每個節點計算、分配token
- 新增移除節點後無需重新平衡叢集負載
- 重建死掉的節點更快
- 允許在同一叢集使用不同效能的機器