
用 JSON 表現樹的結構兼談佇列、堆疊的練習(二)
樹的查詢
查詢,又叫作搜尋 search。查詢跟遍歷的概念不同,遍歷是全部的節點都要走一遍,而查詢,找到目標節點就立刻返回,不會繼續遍歷了。當然,如果什麼都沒查詢到,就是一次完整的遍歷過程了。
查詢的依據是什麼?假設我們對 K/V 結構,也就是 Map,對其增加 id 欄位,用來作為查詢的依據,那麼使用者輸入如果符合 id 就返回節點,表示查詢成功。
單層的查詢很好做,在遞迴的函式裡 if(id = map.get("id") ) 判斷一下就可以了。JSON 是多層的,怎麼做多層的呢?
還是那個 json 例子,已經有 id 欄位存在了。我們希望輸入查詢條件如 "product/new/yuecai" 返回 {id:yuecai, name : 粵菜} 這個節點。
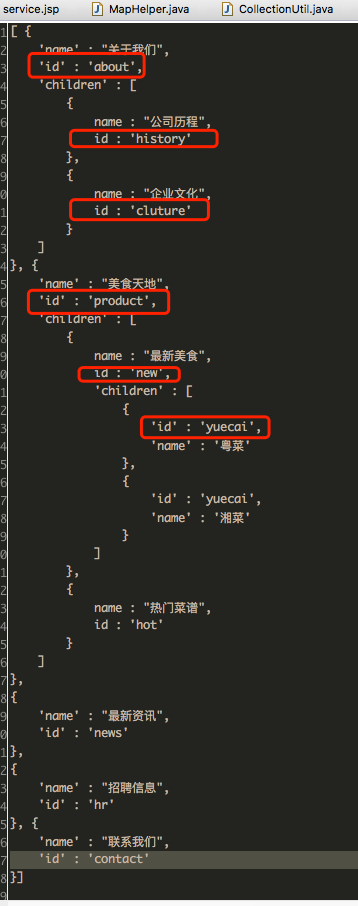
呼叫方式如下
JsonStruTraveler t = new JsonStruTraveler();
assertEquals("關於我們", t.findByPath("about", list).get("name"));
assertEquals("企業文化", t.findByPath("about/cluture", list).get("name"));
assertEquals("粵菜", t.findByPath("product/new/yuecai", list).get("name"));findByPath 返回是 map 型別,就是這個節點。如果你有了解過 JSONPath
由於水平有限,當前只能做的從根節點一步一步查詢,非常簡單的原理。不支援從非第一級節點開始的查詢。
查詢的原理
原理還是非常簡單,依然是遞迴的呼叫。不過在輸入條件的處理上,使用了一點技巧,就是佇列的運用。
/** * * 根據路徑查詢節點 * @param str * Key 列表字元 * @param list * 列表 * @return Map */ public Map<String, Object> findByPath(String str, List<Map<String, Object>> list) { if (str.startsWith("/")) str = str.substring(1, str.length()); if (str.endsWith("/")) str = str.substring(0, str.length() - 1); String[] arr = str.split("/"); Queue<String> q = new LinkedList<>(Arrays.asList(arr)); return findByPath(q, list); } /** * 真正的查詢函式 * * @param stack * 棧 * @param list * 列表 * @return Map */ @SuppressWarnings("unchecked") private Map<String, Object> findByPath(Queue<String> queue, List<Map<String, Object>> list) { Map<String, Object> map = null; while (!queue.isEmpty()) { map = findMap(list, queue.poll()); if (map != null) { if (queue.isEmpty()) { break;// found it! } else if (map.get(children) != null) { map = findByPath(queue, (List<Map<String, Object>>) map.get(children)); } else { map = null; } } } return map; }
首先拆分輸入的字串,變為佇列( Queue 窄化了 LinkedList)。當 findMap 函式找到有節點,此時已消耗了佇列的一個元素(queue.poll())。如果佇列已經空了,表示已經查詢完畢,返回節點。否則再看看下級節點 children 是否有,這一步是遞迴的呼叫,私有函式 private Map<String, Object> findByPath 就是專門為遞迴用的函式。
如果不使用佇列,也可以完成,但就比較累,要自己寫多幾行程式碼控制,就操作如下程式碼。
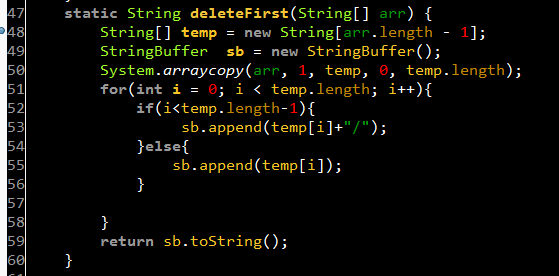
最開始的時候,我先想到的不是 佇列,而是 棧。後來想想了,生成棧的過程比較繁瑣,因為字串 split 之後,是要反轉陣列才能變為棧的:
String[] arr = str.split("/");
Stack<String> stack = new Stack<>();
for (int i = arr.length - 1; i >= 0; i--)
stack.push(arr[i]);而後來想了下既然要反轉陣列,那不與直接使用與棧相反的 佇列 好了。這裡用棧或是佇列是有差別的但差別不大,我們只是避免手寫更多的行數來控制陣列,對精簡程式碼有好處。
扁平化 Map
JSON 樹變成 MapList 之後,仍然是多層結構,如訪問其中某個值(注意不是“節點”),必須逐級別訪問。每級訪問時都要判斷物件是否為空,這就是要避免的 Java 空指標問題。例如 ((Map<String, Object>)list.get(0)).get("level"),比較繁瑣。於是,我們希望可以寫一個表示式就可以直接訪問某個節點。上述如 product/new/yuecai 路徑的方式是一種思路;這裡再介紹一種不同的方式,它把 / 變成 . 如 product.new.yuecai,而且內部實現完全不同,速度會快很多。這就是扁平化 Map。
之所以強調扁平化 Map 中的 Map ,其意思是隻強調處理 K/V 的 Map,輸入型別要求是 Map,對於遇到 List 型別的 Value 不會去區分那是值還是子節點,一律當作下一級的子節點集合處理。這與“product/new/yuecai” 指定 children 項的方式來處理子集合稍有區別的,後者要求輸入的是 List。而且前者通常是返回某個值,後者返回的是節點(Map),返回的內容其意義不一樣。
首先定義內部介面 TravelMapList_Iterator,有三個方法:
/**
* 遍歷 MapList 的回撥
* @author Frank Cheung [email protected]
*/
public static interface TravelMapList_Iterator {
/**
* 當得到了 Map 的 key 和 value 時呼叫
*
* @param key 鍵名稱
* @param obj 鍵值
*/
public void handler(String key, Object obj);
/**
* 當得到一個新的 key 時候
* @param key 鍵名稱
*/
public void newKey(String key);
/**
* 當退出一個當前 key 的時候
* @param key 鍵名稱
*/
public void exitKey(String key);
}接著定義遞迴函式遍歷 MapList
/**
* 遍歷 MapList,允許 TravelMapList_Iterator 控制
*
* @param map
* 輸入 Map
* @param iterator
* 回撥
*/
@SuppressWarnings("unchecked")
public static void travelMapList(Map<String, Object> map, TravelMapList_Iterator iterator) {
for (String key : map.keySet()) {
Object obj = map.get(key);
if (iterator != null)
iterator.handler(key, obj);
if (obj != null) {
if (obj instanceof Map) {
if (iterator != null)
iterator.newKey(key);
travelMapList((Map<String, Object>) obj, iterator);
if (iterator != null)
iterator.exitKey(key);
} else if (obj instanceof List) {
List<Object> list = (List<Object>) obj;
for (Object item : list) {
if (item != null && item instanceof Map)
travelMapList((Map<String, Object>) item, iterator);
}
}
}
}
}TravelMapList_Iterator 到底有什麼用?說到底是為了進棧和退棧用的。堆疊有後入先出的特性,在這裡使用最適合不過了——用來記錄所在層級。
/**
* 扁平化多層 map 為單層
* @param map
* @return
*/
public static Map<String, Object> flatMap(Map<String, Object> map) {
final Stack<String> stack = new Stack<>();
final Map<String, Object> _map = new HashMap<>();
travelMapList(map, new TravelMapList_Iterator() {
@Override
public void handler(String key, Object obj) {
if (obj == null || obj instanceof String || obj instanceof Number || obj instanceof Boolean) {
StringBuilder sb = new StringBuilder();
for (String s : stack) {
sb.append(s + ".");
}
_map.put(sb + key, obj);
// System.out.println(sb + key + ":" + obj);
}
}
@Override
public void newKey(String key) {
stack.add(key); // 進棧
}
@Override
public void exitKey(String key) {
stack.pop(); // 退棧
}
});
return _map;
}外界呼叫 API 其實就是這個 flatMap 方法。
呼叫例子:
Map<String, Object> f_map = JsonStruTraveler.flatMap(map);
assertEquals(7, f_map.get("data.jobCatalog_Id"));輸入 JSON
{
"site" : {
"titlePrefix" : "大華•川式料理",
"keywords" : "大華•川式料理",
"description" : "大華•川式料理飲食有限公司於2015年成立,本公司目標緻力打造中國新派川菜系列。煒爵爺川菜料理系列的精髓在於清、鮮、醇、濃、香、燙、酥、嫩,擅用麻辣。在服務出品環節上,團隊以ISO9000為藍本建立標準化餐飲體系,務求以嶄新的姿態面向社會各界人仕,提供更優質的服務以及出品。煒爵爺宗旨:麻辣鮮香椒,美味有訣竅,靚油用一次,精品煮御賜。 ",
"footCopyright":"dsds"
},
"dfd":{
"dfd":'fdsf',
"id": 888,
"dfdff":{
"dd":'fd'
}
},
"clientFullName":"大華•川式料理",
"clientShortName":"大華",
"isDebug": true,
"data" : {
"newsCatalog_Id" : 6,
"jobCatalog_Id" :7
}
}最後得到 map 結構是這樣子的,根節點的話則沒有 . (點)。
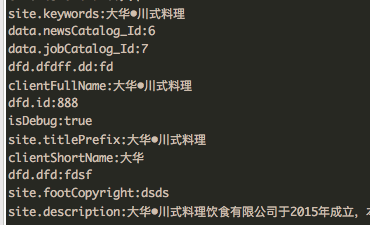
由於是 map 查詢,所以查詢的速度會很快。
格式化 JSON
如果對棧的技術不甚明瞭,可以嘗試通過格式化 JSON 這個例子去理解。儘管這例子沒有使用的棧,但是有相仿的地方,都是異曲同工的,大家可以細細品味。
/**
* 格式化 JSON,使其美觀輸出到控制或其他地方 請注意 對於json中原有\n \t 的情況未做過多考慮 得到格式化json資料 退格用\t
* 換行用\r
*
* @param json
* 原 JSON 字串
* @return 格式化後美觀的 JSON
*/
public static String format(String json) {
int level = 0;
StringBuilder str = new StringBuilder();
for (int i = 0; i < json.length(); i++) {
char c = json.charAt(i);
if (level > 0 && '\n' == str.charAt(str.length() - 1))
str.append(StringUtil.repeatStr("\t", "", level));
switch (c) {
case '{':
case '[':
str.append(c + "\n");
level++;
break;
case ',':
if (json.charAt(i + 1) == '"')
str.append(c + "\n"); // 後面必定是跟著 key 的雙引號,但 其實 json 可以 key 不帶雙引號的
break;
case '}':
case ']':
str.append("\n");
level--;
str.append(StringUtil.repeatStr("\t", "", level));
str.append(c);
break;
default:
str.append(c);
break;
}
}
return str.toString();
}其中,level 表示縮排數,level++ 可看著“進棧”的操作,反之,level-- 為“退棧”,這一退一進是不是與棧的 push/pop 很像?
StringUtil.repeatStr 是重複字串多少次的函式,比較簡單,這裡就不貼出了。
相關推薦
用 JSON 表現樹的結構兼談佇列、堆疊的練習(二)
樹的查詢查詢,又叫作搜尋 search。查詢跟遍歷的概念不同,遍歷是全部的節點都要走一遍,而查詢,找到目標節點就立刻返回,不會繼續遍歷了。當然,如果什麼都沒查詢到,就是一次完整的遍歷過程了。查詢的依據是什麼?假設我們對 K/V 結構,也就是 Map,對其增加 id 欄位,用來
【資料結構】棧與佇列的面試題(二)
一.使用兩個佇列實現(實現棧先進後出的特點) 思路: 1.建立兩個佇列的結構體,並將這倆個佇列(Queue1和Queue2)的結構體封裝到一個結構體裡。 2.入棧:判斷哪個佇列中為空(Queue1和
A1—淺談JavaScript中的原型(二)
js原型是什麽?想要了解這個問題,我們就必須要知道對象。對象根據w3cschool上的介紹:對象只是帶有屬性和方法的特殊數據類型。我們知道,數組是用來描述數據的。其實呢,對象也是用來描述數據的。只不過有一點點的區別,那就是數組的下標只能是數字。所以,數組最好只用來裝同樣意義的內容。比如說[1,2,3,4,5]
淺談我的MongoDB學習(二)
如果 自動 淺談 查詢 技術分享 刪除 insert 工作經歷 posit 上一篇簡單講了mongodb的安裝,mongo的windows服務安裝,這樣服務器重啟windows服務會自動重啟mongodb的server,然後我們就可以用客戶端去管理數據了。mongod
用ASP.NET Core MVC 和 EF Core 構建Web應用 (二)
work nal nta 多個 包括 catch web 應用 自動 選項卡 本節學習如何執行基本的 CRUD (創建、 讀取、 更新、 刪除) 操作。 自定義“詳細信息”頁 學生索引頁的基架代碼省略了 Enrollments 屬性,因為該屬性包含一個集合。 在“詳細信息”
淺談PHP面向物件程式設計(二)
和一些面向物件的語言有所不同,PHP並不是一種純面向物件的語言,包PIP它支援面向物件的程式設計,並可以用於開發大型的商業程式。因此學好面向物件輸程對PHP程式設計師來說也是至關重要的。本章並針對面向物件程式設計在PIP語言中的使用進行詳細講解。 2.1 面向物件概述 面向物件是一種符
從招式與內功談起——設計模式概述(二)
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
專案練習(二)—微博資料結構化
1.ETL概念 ETL,是英文 Extract-Transform-Load 的縮寫,用來描述將資料從來源端經過抽取(extract)、互動轉換(transform)、載入(load)至目的端的過程。 2.專案目標: 本次專案側重於資料的整合(即將檔案中
淺談排序演算法的效率(二)—(Java筆記)
首先:咱也借用一下網上的那張XXX的圖,咯!在下面: 接下來,就是咱的驗證時間了(驗證什麼?當然是各種演算法的時間複雜度比較咯),沒什麼好說的了,直接上碼吧。 程式碼實現: import java.util.Arrays; public class SortSum
細談Type-C、PD原理(二)
目錄 一、Type-C簡介以及歷史 二、Type-C Port的Data Role、Power Role 三、Type-C的Data/Power Role識別協商/Alt Mode 四、如何進行資料鏈路的切換 五、相關引數/名詞解釋 六、PD協議簡介
資料結構內排序之慘死攻略(二)
接上回合《資料結構內排序之慘死攻略(一)》 聽聞今天還要學資料結構,心中堵著一片烏雲。 就算受低潮情緒影響也要堅持學下去啊。 目錄 5 歸併排序 5.1 栗子 5.2 程式碼實現 5.3 歸併演算法優化 5.3.1 R.Sedgewick優化 5.3.2
淺談 SQL 中的鎖(二)餘額問題的處理
上次模擬了 SQL 中併發執行更新餘額的語句,出現餘額負數的問題:http://blog.csdn.net/closurer/article/details/54288628 現在說說它的解決方法。 事務要正確地執行,就需要【隔離性】這個基本要素。更新餘額的語句之所以會偏離
QT迴圈佇列實時處理資料(二)
上一篇多執行緒介紹的是,QT多執行緒處理機制,這篇,將對接收資料,實時處理進行分析。 QT通過socket通訊,從接收緩衝區中讀取資料,交給執行緒進行處理,那麼問題來了,如果執行緒還沒有處理完資料,則執行緒就沒有辦法繼續從緩衝區中取數,那麼當資料量
用連結串列實現一元多項式加減、求導(Java)
Lnode.java package PloyItem; /** *@Author wzy *@Date 2017年11月12日 *@Version JDK 1.8 *@Description */ public class Lnode imp
淺談Linux PCI裝置驅動(二)
我們在 淺談Linux PCI裝置驅動(一)中(以下簡稱 淺談(一) )介紹了PCI的配置暫存器組,而Linux PCI初始化就是使用了這些暫存器來進行的。後面我們會舉個例子來說明Linux PCI裝置驅動的主要工作內容(不是全部內容),這裡只做文字性的介紹而不會涉及具體程
分散式訊息佇列ActiveMQ訊息模型(二)
在ActiveMQ中,一共支援4種訊息型別,分別是TextMessage訊息型別、BytesMessage訊息型別、ObjectMessage訊息型別,還有一種MapMessage訊息型別。 (1) TextMessage訊息型別 TextMessage訊息是
再談資料結構(二)數和二叉樹
1 - 引言 關於樹和二叉樹,我們需要達到的能力有: 熟悉樹和二叉樹的有關概念 熟悉二叉樹的性質 熟練掌握遍歷二叉樹的遞迴演算法,並靈活運用 遞迴遍歷二叉樹及其應用 本文著重在樹和二叉樹實際應用與程式碼實現基本操作,對概念就不再贅述 2 - 二
資料結構實驗之棧與佇列六:下一較大值(二)(因為資料量大所以用棧來操作)
資料結構實驗之棧與佇列六:下一較大值(二) Time Limit: 150 ms Memory Limit: 8000 KiB Problem Description 對於包含n(1<=n<=100000)個整數的序列,對於序列中的每一元素,在序列中查詢
數據結構之二叉樹(二)
創建 int iter out for 結點 spa left nbsp 輸出二叉樹中所有從根結點到葉子結點的路徑 1 #include <iostream> 2 #include <vector> 3 us
學習之路(二)淺談:bash及其特性,命令歷史以及用戶管理及權限,shell的類型
bash 管理權限 過了一周了,進度似乎有點懈怠,不過過了周末重整旗鼓啦shell(外殼)GUI:Gnome,KDE,xfceCLI:sh,csh,ksh,bashbash(父進程)-----bash(子進程)他們相互獨立彼此不知命令歷史:historybash支持的引號:‘ ’命令替換(鍵盤~的按鍵