
大資料-Hadoop-MapReduce (二) WrodCount單詞計算
阿新 • • 發佈:2019-02-05
Hadoop-MapReduce (二) -WrodCount單詞計算
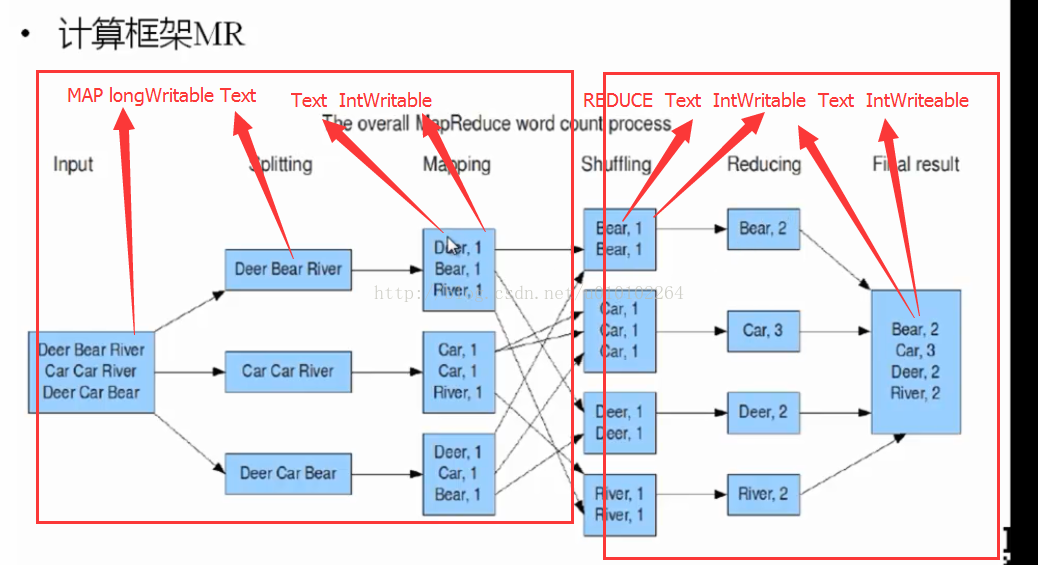
1)Map 將每一行的單詞計數為1 Map<word,1>
一句話理解: 將很多很多的文字檔案遍歷計算出每一個單詞出現的次數
-擴充套件閱讀TF-IDF詞頻-逆向文件頻率
(WordCount).單詞計算
有文字如下: a b c b b c c d c 需得到結果為: a 1 b 3 c 4 d 1 原理如圖:1)Map 將每一行的單詞計數為1 Map<word,1>
2)Shuffling 對每一個單詞進行分類合併 Map<word,<1,1>> 3)Reduce 對每一個單詞累加 word = 1 + 1// 輸入為一行行的資料 其中 LongWritable key為下標,Text value 為這一行文字 // 假設這一行資料為 b c d e e e e public static class TokenizerMapper extends Mapper { protected void map(LongWritable key, Text value, org.apache.hadoop.mapreduce.Mapper.Context context) throws IOException, InterruptedException { String lineStr = value.toString();// 得到一行文字 // 使用空格分離 預設引數為空格 StringTokenizer words = new StringTokenizer(lineStr); while (words.hasMoreElements()) { String word = words.nextToken();// 得到這個單詞 //if(word.contains("Maturity")) // 交這個單詞計數+1 context.write(new Text(word), new IntWritable(1));// 輸出到map } } }
4)Job運算// input e1 e1 e1 e1 // output e4 //public static class IntSumReducer extends Reducer { public static class IntSumReducer extends Reducer { public void reduce(Text key, Iterable values, Reducer.Context context) throws IOException, InterruptedException { int count = 0; // String word = key.toString(); for (IntWritable intWritable : values) { // 迴圈 count += intWritable.get(); } // 輸出 context.write(key, new IntWritable(count)); } }
轉載請註明出處,謝謝!public class WordCount { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String inputPath = "input/wordcount"; String outputPath = "output/wordcount"; // String[] otherArgs = (new GenericOptionsParser(conf, // args)).getRemainingArgs(); String[] otherArgs = new String[] { inputPath, outputPath }; /* 直接設定輸入引數 */ // delete output Path outputPath2 = new Path(outputPath); outputPath2.getFileSystem(conf).delete(outputPath2, true); // run if (otherArgs.length < 2) { System.err.println("Usage: wordcount [...] "); System.exit(2); } Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(WordCount.TokenizerMapper.class); //job.setCombinerClass(WordCount.IntSumReducer.class); job.setReducerClass(WordCount.IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //output file total //job.setNumReduceTasks(1);//reducer task num for (int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); System.exit(job.waitForCompletion(true) ? 0 : 1); }