
python unicode-escape編碼問題
有一串編碼如下:
s='\u871c\u7c89/\u6563\u7c89'
檢視型別,為str:
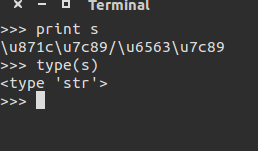
按utf-8先解碼在編碼依然不行。
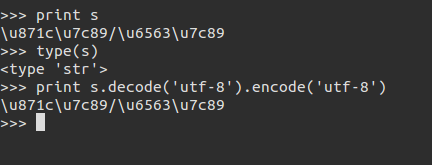
可以這麼做:
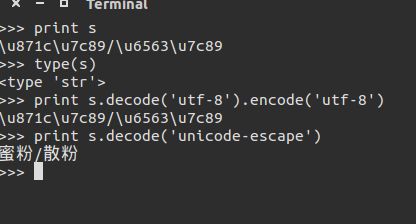
那麼問題來了,這個unicode-escape什麼來的呢
在python中,對於unicode儲存時,可以採用另一種方法:
將unicode的記憶體編碼值進行儲存,讀取檔案時在反向轉換回來。這裡就採用了unicode-escape的方式
對string儲存,python也可以採用相類似的方式,詳細的見下面的
這個博文
相關推薦
python unicode-escape編碼問題
有一串編碼如下: s='\u871c\u7c89/\u6563\u7c89' 檢視型別,為str: 按utf-8先解碼在編碼依然不行。 可以這麼做: 那麼問題來了,這個unicode-escape什麼來的呢 在python中,對於un
python編碼與反編碼 decode('unicode-escape')
“反編碼”我自己起的名字,大概意思就是我得到一串字元,是unicode碼,如:‘\u53eb\u6211’,進行反編碼後得到其對應的漢字。 f='\u53eb\u6211' print f print(f.decode('unicode-escape')) 結
Python Unicode編碼方式
方式 -- logs unicode cnblogs sdn 文獻 article col 編譯時使用--enable-unicode=ucs4 >>> import sys >>> print sys.maxunicode 111
Python Unicode編碼
其中 它的 pick 不能 encode 如果 兼容 type text 使用技巧事實上,只要遵守以下規則,可以規避90%由於Unicode字符串處理引起的bug,剩下的10%通過python的庫和模塊能夠解決。程序中出現字符串時一定要加個前綴u。不要用str()函數,用u
Python中GBK, UTF-8和Unicode的編碼問題
https://www.cnblogs.com/jxzheng/p/5186490.html 編碼問題,一直是使用python2時的一塊心病。幾乎所有的控制檯輸入輸出、IO操作和HTTP操作都會涉及如下的編碼問題: UnicodeDecodeError: ‘ascii’ codec can’
python unicode 及解碼編碼方式簡介
python及編碼原理測試 基於utf—8環境。 #coding:utf-8 unicode為通用編碼。 coding:utf-8的作用是宣告python直譯器及str的編碼方式,並不改變其他sys.getdefaultencoding()的預設編碼
深入理解Python的字元編碼utf-8 & unicode
參考:http://lukejin.iteye.com/blog/598303 一,通過例子理解字元編碼 在Python中有兩個和字元很相關的型別,一個是str型別,一個是unicode型別。 這兩種型別的物件都是sequece序列,其中str是位元組序列,而unicode
【Python】utf8,unicode,ascii編碼的相互轉換
(linux系統為例) 中文字元:腳 對應編碼如下: utf8編碼: unicode編碼:(引號前有 u) ascii編碼: 【1】unicode與ascii互轉 涉及函式:ord()與 ch
python unicode 編碼整理
unicode 是 character set character set 是把每個字元對應成數字的集合,比如unicode中 A對應0041,漢字『我』對應 ‘6211’ unicode 是個很大的集合,幾乎覆蓋世界上所有的字元,現在的規模已經可以容納100萬個字元。 utf-8 是對 unicode
python2 編碼問題小解決;sys;unicode-escape
今天作者想要分享的是自己在爬取網站過程中一些簡單的編碼問題,當然說是簡單問題作者也是搜尋了很久,今天分享下來方便以後自己在遇到這類問題更好的解決。 環境:python2 目標網站種的內容如下圖: 從爬取出來的程式碼來看這些欄位並沒有亂碼,但是啊在作者進
python中關於編碼,json格式的中文輸出顯示
pri 整體 pytho src repr 接口 ensure 輸出 unicode 但我們用requests請求一個返回json的接口時候, 語法是 result=requests.post(url,data).content print type(result),re
python版本與編碼的區別
而是 hang 什麽 and ati 傳統 格式 字符編碼 com 主要編碼介紹 python解釋器在加載 .py 文件中的代碼時,會對內容進行編碼(默認ascill) ASCII(American Standard Code for Information Interch
python字符編碼
height 計算 速度慢 char bytes bit lose line 後來 1. 字符編碼簡介 階段一:現代計算機起源於美國,最早誕生也是基於英文考慮的ASCII ASCII:一個Bytes代表一個字符(英文字符/鍵盤上的所有其他字符),1Bytes=8bit,8b
python---字符編碼
type 分享 utf-8 sci string span py3 unicode轉換 png 1. 無論py2還是py3,字符編碼之間相互轉換,如gbk轉換成utf-8,都需要通過unicode中轉 , 2. 將非unicode轉換成unicode的時候,是需要告知原本是
python實戰之編碼問題:中文!永遠的痛
輸出 == 技術分享 都是 -s dsm font clas ng- 編碼的思維圖譜: 也就是說文件沒有編碼之說,事實上都是按二進制格式保存在硬盤中的。不過在寫入讀取時須使用相應的編碼進行處理,以便操作系統配合相關軟件/字體,繪制到屏幕中給人
python 字符編碼處理問題總結 徹底擊碎亂碼!
解析 有意義 odi span data- posit 網頁 class ack Python中常常遇到這種字符編碼問題,尤其在處理網頁源代碼時(特別是爬蟲中): UnicodeDecodeError: ‘XXX‘ codec can‘t decode bytes in
python字符編碼與轉碼
python字符編碼與轉碼 python2.x字符編碼與轉碼 python3.x字符編碼與轉碼 python 2.x 字符編碼與轉碼打印系統默認編碼格式import sys print(sys.getdefaultencoding())UTF-8 轉 gbk方式:utf-8--轉成--unicod
python - 字符編碼篇
占用 logs utf blank big5 tro 自然 成了 數據庫 本章內容 什麽是字符編碼? python默認編碼 decode(解碼)和encode(編碼) 前言 對於字符編碼的問題,在學習python的過程中,很多新手都為之瘋狂,本人
Python 字符編碼
nic reader n) 文件類型 Coding utf-8 猜想 所有 utf8編碼 采用標準庫codecs模塊 codecs.open(filename, mode=‘r‘, encoding=None, errors=‘strict‘, buffering=1)
Python字符編碼與函數基本使用-day3
you rgs 內置函數 無法 lov 格式 img 這一 day3 解決Python2和Python3中字符編碼的問題 補充Python2中文件操作的說明 函數使用基礎 函數的類型 一、Python2中的字符存在的解碼編碼問題 如果是現在正在用Python2的