
論一個糟糕的大資料碼農的自我修養
本來想寫寫如何成為一名優秀的大資料平臺開發工程師,但說實話,這個話題太簡單了!雖然我沒有被Jeff dean大神附體,也不好意思腆著臉自認為有資格指點江山。但是,講道理,誰不會呢?
好比,炒股票,不就是低買高拋嗎,玩網際網路,不就是拉流量去變現嗎?
而要想成為一名優秀的大資料平臺開發工程師,只要做到深度與廣度並重,鑽研技術,理解產品,能搭架構,能解Bug,那就妥妥的了。
道理如此簡單,還需要多解釋麼?而我們,大概不是輕鬆的碾壓了巴菲特,就是早已經順利的在風口起飛了!

是的,優秀就是這麼簡單,太過無聊,所以,本文的重點,是聊聊如何能夠做到不那麼優秀,要想成為一個糟糕的開發工程師都需要有哪些表現。
我是小白我怕誰,正確的入門姿勢
要想成為一個糟糕的大資料平臺開發工程師,首先你得幹上這行不是,怎麼入門不重要,重要的是,自我修養,要從入門抓起。
大資料開發如何入門,在各種論壇或者技術會議中,時不時的總會有人問起。而提問者的問法往往也很類似:你好,我對大資料開發很感興趣,我想學大資料,但我不知道該怎麼入門,我該學些什麼呢?
每每面對如此切中要害的問題,我總會有一種無比喜悅,乃至脫力的感覺。是的,真正感興趣的同學,一定是激情澎湃,迫不及待的愛上了大資料,調研工作?沒有的事,還需要調研,那不是真的熱愛!況且那樣的話,還怎麼能問出如此粗曠而又犀利的問題呢?
對於這個問題,我也總能估計到提問者的預期答案。應該包括一串技能清單,以及回答問題者自身的成功實踐示範:先看什麼書,再學什麼課程,然後搭建個什麼系統,最好列個完整的學習計劃和清單,要是還有各種職位需求的市場調研,薪資待遇的統計分析什麼的,那就更完美了!
所以,我會懷疑這位同學是真的有興趣,還是無腦跟風熱點,又或者是學習能力/做事方法有問題嗎? 不會,我只會認為,這位同學,簡直太他媽好學了!

至於搞清楚自己到底喜歡什麼,為什麼喜歡,很重要嗎?讓磚家來替我做主,告訴我該學什麼,效率豈不是更高?
敏而好學,不恥下問
學什麼解決了,下一步是怎麼學。
遇到問題前先思考一下,看一下文件,讀點程式碼,分析一下日誌?不存在的!都什麼年代了,社交為王懂不懂?微信里加了這麼多大資料群組幹嘛用的,“討論”問題啊!“敏”而好學,快就一個字!
什麼?有人膽敢拿出“如何問一個好問題”這樣的垃圾文章出來敷衍我這樣好學的同學?傲嬌了是嗎?問一下能死啊?你懂還是不懂?懂就回答,不懂就不要瞎BB!古人不雲麼,不恥下問!你能有回答的機會就是你的榮幸!
好吧好吧,那麼,如果想在這個領域長期耕耘下去,這樣做靠不靠譜呢?據說大資料平臺相關開發工作,面對的問題往往是複雜的,需要從業人員具備良好的學習總結和推理分析的能力。如果不具備主動學習和思考的習慣,聽說也就幾乎不可能成長成為這個領域的專家?
這簡直就是妖言惑眾啊!事實勝於雄辯,你看,明明有好多公司,有很多同學,日常工作中,就是這麼做的。他們也搭過叢集,C&V過程式碼,寫過ETL程式,遇上“特別複雜”的難題,比如叢集莫名其妙起不來了之類的,百度一下專家推薦的配置引數,搜尋一下出錯資訊,就搞定了,還經常寫點我司資料平臺的踩坑經驗和實戰的分享,你就說牛不牛吧!
什麼,這種情況長久不了,這類工作遲早會被替代,尤其是在偏底層的基礎平臺開發工作環境中?那得多久的將來啊?什麼AWS和阿里雲,他們平臺上的標準化服務?沒聽過,我們要有自主智慧財產權啊!
效率優先,中文至上
能百度就不穀歌;能找到不知道誰寫的搭建筆記,就堅決不讀官網的Tutorial,要是還有手把手的教學視訊,那就更好了。
叢集如何調優,問題如何解決?根據錯誤資訊,搜尋踩坑指南啊,別管花多少時間,在多麼犄角旮旯的部落格也要搜出來。官網的FAQ或者Tuning Guide?抱歉,沒時間看。Mailing list,Jira?那是什麼東東?
怎麼,不行麼?這也沒啥大不了啊,我不是看不懂英文,但是還是更習慣看中文,效率更高,如果不到山窮水盡,能用中文用中文唄。

或許吧,但除非你想永遠玩別人早就玩剩下的東西,否則,儘可能接觸第一手的資訊。英語差,看英文文件代價高?篩選過時或錯誤資訊的代價可能更高!
流行的就是最好的
什麼技術熱門就學什麼,這還用問麼?別管行不行,先看賺不賺錢啊~~~
這種現象,不光大資料,各個技術領域都是如此,從這幾年我所接觸的求職者的求職意願上就能很明顯的看出來。
無論校招還是社招,無論是剛從別的方向轉行想做大資料,還是在大資料領域內已經有過一些簡單業務開發經驗的同學,幾乎90%以上的應聘者,都會把自己將來工作和實時計算掛上鉤,越是“初生牛犢”的同學越是積極。可不,不玩Spark,不玩Flink,還怎麼跟上時代,人家都說Hadoop已經被淘汰了!
而在985以上好一點的院校的應屆生中,把技能點和求職方向放在演算法和機器學習相關領域的同學更是大幅上升。決策樹,向量機,貝葉斯,xNN , 天池競賽,哪個沒玩過都不好意思投簡歷。而大資料生態系中底層儲存,計算元件,分散式原理架構等相關領域有過深入學習或實踐的同學則明顯呈下降趨勢。
這也很容易理解,一方面機器學習和人工智慧這一兩年來風頭正勁,Alpha狗,Alpha狗元,Alpha元賺足了眼球,另一方面,學習演算法的門檻多低啊,即使沒有工業環境,實踐起來也相對容易,擼一下NG的課,做幾個Demo,參加兩個比賽,大多數理論知識也就能說個七七八八,還有滿地的AI公眾號,AI速成培訓班等等(早幾年則是各種大資料公眾號和速成班,再早,是Java/Spring之類?),沒幾個月時間,就“略有小成”了啊~~~

而大資料平臺的開發工作,屬於偏底層工程技術的領域,如果沒有合適的實踐環境,多數同學靠看論文,讀程式碼,想要真正入門其實難度還是不小的(事實上,這兩年也很少有同學願意花時間這麼去做),即使相關實驗室的專案,通常也偏理論,和現實問題相距甚遠,動手能力堪憂。至於能靠參與開源專案進階的同學更是鳳毛麟角了。多數在中小公司實習的同學,也就是搭個Flume,做一下日誌統計之類的工作。
當然,這沒有貶低演算法工程師的意思,事實上,優秀的演算法工程師永遠都是匱乏的,但和早幾年的大資料一樣,機器學習目前正處於技術成熟度曲線的第二個階段,即期望膨脹階段,有大量的人群擁入,加上早期具備相關知識的人也比較缺乏,所以蹭熱點的同學,不管實際能力如何,就業情況也還不錯。
不過,很明顯的,這個領域也開始往第三階段前進,人員開始沉澱,簡單工作開始標準化,對從業人員的要求早晚也將不再是速成班出來的同學就能滿足的了。不信,你去了解一下這兩年阿里系招聘演算法工程師的標準和待遇的變化。
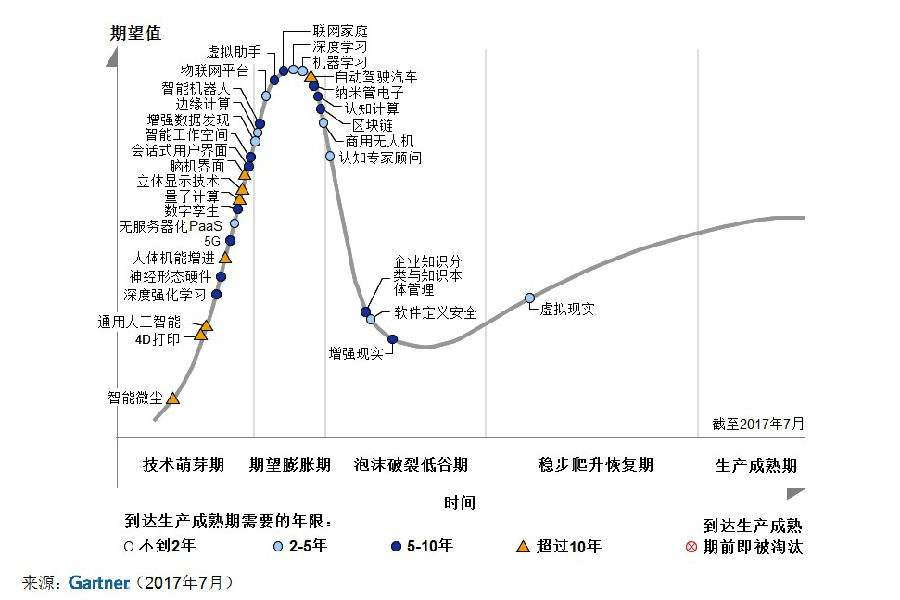
而大資料平臺開發工作,在當前階段,基本就屬於速成的同學很難進一步發展的階段,因為這個領域的部分基礎設施,已經差不多渡過谷底第三階段來到爬升,甚至穩定階段了,簡單的工作很快都要被成熟的服務或解決方案所替代。不具備進入下一階段能力的同學,就業和成長的空間會越來越窄。
浙大的老校長竺可楨曾經說過,諸位在校:有兩個問題要自己問問,第一:到浙大來做什麼? 第二:將來要做什麼樣的人? 很顯然,認清自己,是做任何事情的第一要務。
我相信,多數同學的答案當然不會是:1: 混,2: 混混。但是隨波逐流,大家怎麼做我就怎麼做,卻可能是不少同學在實際行動中給出的答案。
說這麼多,其實就想說,蹭熱點,本身問題不大,不過要想長期發展的話,關鍵是你本身也要具備對應的實力,大家都想做的事,你憑什麼能比得過別人,就算眼下沒問題,過幾年等該領域成熟了呢?與其琢磨哪裡是熱點,不如想想自己適合做什麼樣的工作,如何讓自己在技術的變革中持續的成長。
我們的征途,是星辰大海
也有同學會說,我並不是跟風追熱點,只是,當前的工作,真的不適合我,我希望去做更有價值,更有挑戰的事。至於為什麼現在的工作不適合呢? 比如:
- 業務太煩,瑣事太多,沒有時間學習
- 幹了很長時間,重複勞動,沒有長進的空間
- 系統很成熟了,沒有什麼可做的了
- 做的事沒挑戰,發揮不出我的能力
- 做的事太Low,覺得沒前途
- 問題太多,團隊技術水平太差
總之,就是我行,但是,這事不行,環境不行,所以我要換方向,我要換地方。

誠然,上述情況未必不客觀,他們很可能也是這些同學在工作過程中的真實感受,但我敢說,如果這就是全部原因的話,那麼,有一多半的可能,根源不在環境,而在我們自身。因為上述情況,只是問題和現象,不是答案和原因。
- 瑣事太多,重複勞動太多?有沒有思考過如何化繁為簡,還是隻會用體力勞動代替腦力勞動?
- 系統成熟,沒什麼可做的?是系統真的完美無瑕了,還是我們坐井觀天,眼界太低,不知道該如何改進?
- 做的事沒挑戰,做的事太Low?是事情本身太Low,還是我們做事的目標和方法太Low?
- 問題太多?是周邊同事能力太差,還是自己只會頭痛醫頭,解決問題不徹底,又或者是沒有能力推進複雜問題的解決?
當然,每個人都希望在一個最好的環境中工作,這本身並沒有錯,但如果你只是單純的迴避問題,而未曾解決過這些問題,那麼十有八九,在新的環境中,你早晚還是會遇上同樣的問題。
書中自有顏如玉,讓我看一下程式碼先
有些同學,特別是經常和開源相關元件打交道的同學,會特別喜歡閱讀程式碼。
閱讀程式碼,當然沒錯,說實話,愛讀程式碼的同學現如今也不好找了。而且由於大資料環境下的底層元件在程式碼,流程和併發邏輯上的複雜性,再加上上層業務繁多,關係複雜。所以再成熟的系統,在生產過程中,也難免會遇上各種各樣的疑難問題。如果還要做效能優化,那更需要對系統有深入的瞭解。所以不願意看程式碼,只依靠百度的同學一定做不好相關的工作。

但是,過猶不及,畢竟閱讀和熟悉程式碼只是手段,而非最終目的。遺憾的是,有時候,很多同學往往並沒有認識到這一點,舉些例子:
我們曾經有個同學特別喜歡閱讀某個開源元件的程式碼,而且非常願意把程式碼的閱讀理解寫成文件,發表在部落格上。這本身並非壞事,你甚至會覺得,這簡直太好學了不是!
但非常遺憾的是:
一來,這位同學的部落格基本寫的都是程式碼微觀層面的流程理解,比如:要做件事,那麼是怎麼做到的呢?你看,程式碼是這樣這樣的。缺乏更高層的抽象歸納,需不需要這樣做,為什麼這樣做,背後的思想是什麼,有沒有更好的方式等等
二來,他看程式碼的過程對日常工作的解決,往往沒有什麼幫助。比如遇到業務出錯,任務執行緩慢,叢集不穩定啦之類的問題,要不然覺得都是小問題,不屑一顧;要不然就是隻會照本宣科,你看程式碼邏輯是這樣的,遇到這種場景,就是這種現象。而幾乎不會思考這樣的場景下,就算程式碼本身沒有bug,邏輯是不是合理,可以怎麼改良,能否有其他方式規避等等。
第三點,最重要的,還是思想認識,總覺得程式碼讀得多就牛逼了,這不,部落格文件有人點贊,還能給社群貢獻程式碼呢(雖然大多patch,都是哪裡文件錯誤,哪個引數預設設定有問題,哪個邏輯,程式碼分支流程有缺失之類的補丁),至於工作沒做好?那是這個工作太簡單,不適合自己,發揮不了自己的能力,從來不認為是自己並沒有真正具備解決問題的能力。所以,這位同學後來另謀高就了,而我一點都不覺得可惜。
寫出來也不是為了噴這位同學,純粹就事論事,也真心希望他在將來能慢慢意識到這一點。
多讀點程式碼總沒有壞處?
你可能會說,這只是個極端的例子,多數同學還是會針對問題和工作內容來學習程式碼的。即便如此,還是有很多時候,我覺得,有些同學程式碼看得過多了。
比如在還沒有梳理清楚問題的核心矛盾是什麼,可選的方案的優缺點有哪些之前,熱愛閱讀程式碼的同學可能就會將大量的時間投入到程式碼的深度閱讀中去,總覺得多讀點程式碼沒有什麼壞處。
這些同學可能未必不明白全域性評估的重要性,但是他們很可能慣性的認為只有依靠完全徹底的理解程式碼,才能得到第一手的資料,才能“更好”的評估實施方案。
而事實上,這往往事與願違,一方面,你可能迷失在一些無關痛癢的區域性細節上,另一方面可能忽視了真正需要儘早找出答案的問題。

實際上,這其實在某種程度上來說,也是一種用戰術上的勤快來掩蓋戰略上的懶惰的行為表現。因為閱讀程式碼可能是程式設計師最習慣做的事。但是,採用其它可能的方式去評估或熟悉一個未知的系統呢?
比如詳細閱讀官方文件,進行功能驗證,Demo測試,對類似系統進行橫向比較,收集他人踩坑經驗,尋找問題的其它可能解決途徑等等,這些工作往往有可能更加快速全面的幫你瞭解一個系統,並做出合理的方案設計,但是這麼做,因為涉及到持續的思考,分析,判斷和嘗試的過程,所以有時候很多同學往往反而不願意在上面多費力氣
“迷”之問題的“謎”之解決方式
相比程式碼閱讀的執著,很多同學在分析問題時的表現卻往往相反。
分散式環境下的問題往往錯綜複雜,如果一個問題不是明顯的確定性邏輯錯誤,而是比如跑得慢,效能差,莫名隨機Crash,timeout等等,不少同學很容易就快速陷入迷茫中。而為了將自己從迷茫中掙脫出來,往往會在問題排查過程中,輕易的將某些故障的現象歸結為故障的原因,進而以治標不治本的方式來解決問題。
比如發現程式Crash或者跑得慢,存在GC或OOM的現象,就去調大記憶體或者調整GC配置引數,至於什麼原因導致GC,什麼情況會發生GC,誰在使用記憶體,合不合理,程式邏輯有Bug嗎?就不想分析或者不會分析了;簡單的歸因為資料量變大啦,資料可能傾斜啦,宇宙射線爆發啦等等
再比如發現程式失敗是因為某些方法呼叫過程超時,那就調大併發執行緒數,調大服務超時時間引數,增加機器資源等等,至於能否解釋為什麼偏偏這時候神祕超時,超時的現象合不合理?抱歉,現象無法復現,日誌資訊不足,分析不出來。。。
總之,看起來就是迷之問題,經過迷之自信的推理,得到一個迷之解決方案,就算治標,上述引數該怎麼調,調多少,調完以後能不能有效,也是迷之結果,反正,先觀察一段時間吧。。。
而做的好一點的程式碼流派的同學則可能在排查問題過程中,發現一個Error或Warning日誌,還會去閱讀相關的程式碼,最後花了幾天閱讀完程式碼,可能分析出了什麼流程會打印出了這個Error日誌,但卻不知道,或者解釋不了為什麼當時程式會走到這個流程;再然後,同樣也就排查不下去了。

上述情況,通常可能還是方法論問題,不知道如何把握問題的重點,在問題自身資訊尚未收集清楚的時候,就過早的聚焦在某個收益未知的現象上。而對於進一步的動作,比如
- 質疑問題,考證現象,現有的結論是否站的住腳,是否還有疑點
- 能否再多方面收集一些資訊,或者換一個角度,嘗試別的方式分析問題
- 能否想辦法復現問題,或者學習新的技能解鎖進一步分析問題的能力
- 能否改進日誌,爭取下一次問題出現時能收集到更多資訊
- 在自以為修復問題後,能否針對性的進行後續的監控分析,看看是否真的解決了問題
在類似這些工作方面,往往就沒有表現出應有的執著了。
你可能要問,那我怎麼知道資訊收集完整了沒有呢?這一方面,固然依靠你對系統的瞭解和過往的經驗。但其實,多數情況下,你只需要將問題的現象(結果)和你懷疑的原因進行充分的因果對照,多數情況下就能避免過早的陷入一個錯誤的方向。你需要做的就是問自己三個問題:
- 歷史分析,由果推因:如果問題的出現是由於這個原因,那麼之前沒有出現這個問題的時候,這個原因存在麼?
- 當前現狀,由因推果:如果這個原因會導致這個問題,那麼他還會導致其它什麼問題嗎?那些問題是否存在?
這兩個問題檢驗因果之間的相關性,就是因果關係要進行正反論證,而不僅僅是單方面推理。但這有時候還不夠,你還需要問第三個問題來驗證因果性自身。
- 這個原因是源頭麼?還是也可能只是一個和問題強相關的共生現象?
這個問題有時候不太好回答,也沒有固定的套路來排查,但如果對於這個原因本身,你並沒有找到一個明確的變更點,那無論它有多麼的強相關,也不要過早的認為它就是根源。
總之,事出必有因,排查問題的過程,你要針對的是疑點,哪裡解釋不通,就針對哪裡收集資訊;這並不是說你不能去猜想可能的原因,不能快速的做決定,但猜想不是一廂情願,需要資訊來支撐,需要和現象相比對。
世間繁華,盡是過眼雲煙
作為一個有夢想的工程師,你一定會去關注新技術。
如果方法得當,在短期內,靠深入閱讀文件,翻閱核心程式碼等等手段,你往往是可以快速的在幾天內對一個系統形成基本的認知。
只可惜,大資料領域的技術日新月異,加上很多系統相對複雜的架構特點,決定了這些新技術,往往資訊量不小,如果你沒有真正深入的實踐過,通常很難形成有效的長期知識記憶。可能再過一個月,你剛掌握的內容,就都忘得一乾二淨了。
於是,無論你多麼勤奮努力的去拓展你的知識面,到頭來可能的結果就是,所有這些努力,都打了水漂,在你腦海中留下的,就只是各種人雲亦云的皮毛概念和廣告用語了。

按照網際網路領域的說法,這是花了很多時間精力去拉新,但是在留存環節,效果慘淡。
這種現象其實很普遍,畢竟人的腦容量是有限的,理論上,要解決不外乎就幾條路
- 天賦異稟,容量超人,過目不忘
- 重要知識,印象深刻,選擇性留存
- 藉助外部儲存單元
第一條,你這把年紀了,估計很難有質的變化。
第二條,最常見的就是通過實踐,加深認識,反覆接觸相關知識,不斷重新整理鞏固。但是如果你要追求知識面,很顯然你無法在所有的方向都投入這麼多的時間。
第三條,該備份的沒備份,就算備份了,載入不回來又怎麼辦 ;)
所以,怎麼辦呢?有什麼最佳實踐麼?個人以為,可行的方法之一,是對相關的知識及時進行總結而不是僅僅瀏覽。如何總結呢?這一點,固然沒有絕對適合每個人的最佳方式,但是撰寫一些具有分享性質的文件,不管是以外部的部落格文章,公眾號文章的形式,還是以內部ppt分享的形式,通常都會是一個相對有效的方法。
可能也會有很多同學說,我其實也是有記筆記,但是我沒有時間整理,另外,我也沒想過要通過分享揚名立萬,就自己學習嘛,所以也沒有寫這類文件的需求。
對此我想說,分享固然是寫這類文件的目的之一,但其實,它只是一個副產品,更重要的是幫助自己提升知識留存的能力。如果你的學習筆記只是對各種知識點的copy/paste性質的摘要文件,缺乏整理,沒有分享的價值,那麼,這種型別的筆記,對於你自己的價值,可能也遠低於你的想象。
總之,花過的時間,就要產生價值,想辦法燕過留毛。做好留存的工作,在一個需要長期積累的領域,很多時候可能比拉新更加重要,將來的啟用成本也會低很多。
小結
掙扎了很久,還是寫出了一篇俗套乏味的文章,好吧,我盡力了,從雞湯的角度再總結一下吧:
- 有“錢途”的方向,未必適合你,除非你具備戰勝80%以上的跟風者的能力
- “快速”學習的結果通常是欲速則不達,請學會思考,請閱讀第一手資料
- 閱讀程式碼很重要,但比閱讀程式碼更重要的,是閱讀問題。
- 知識面決定了你的廣度的,但資訊不等於知識面,人云亦云的概念一錢不值。
- 在抱怨工作之前,先審視自身問題,畢竟改變自己更加容易,也更加普遍有效。
最後再補充一句在食品安全反反偽科學中常說的一句話:“脫離劑量談毒性,都是耍流氓”,上述所有問題,並無絕對對錯,重要的是程度的把握,你是否認清了自己的目標,你所做事情與你所想要結果是否能夠匹配。
常按掃描下面的二維碼,關注“大資料務虛雜談”,務虛,我是認真的 ;)
