
讀書筆記 -- 005_資料探勘_度量資料的相似性和相異性
1、概述
相似性和相異性都成為鄰近性(Proximity)。相似性和相異性是有關聯的。典型地,如果兩個物件i和j不相似,則他們的相似性度量將返回0。
2、資料矩陣和相異性矩陣
假設我們有n個物件,每個物件由p個屬性進行刻畫。那麼得到物件集X = (x1, x2, x3, …. xn) ,物件xi的屬性集為 P = (pi1, pi2, pi3 … pip) , 1 < i < n。
資料矩陣(data matrix)
或稱物件-屬性結構。這種資料結構用關係表的形式或 n x p(n個物件 x p個屬性)矩陣存放n個數據物件:

相異性矩陣(dissimilarity matrix)
或稱物件-物件結構。存放n個物件兩兩之間的鄰近度,通常用一個n x n矩陣表示:

其中d(i, j)是物件i和物件j之間的相異性值。一般而言,d(i, j)是一個非負的數值。相似性可以表示成相異性度量的函式:sim(i, j) = 1 – d(i, j)。
資料矩陣由兩種實體或者“事物”組成,即行(代表物件)和列(代表屬性)。因而,資料矩陣經常被稱之為二模(two mode)矩陣。相異性矩陣只包含一類實體,因此被稱之為一模(one mode)矩陣。許多聚類和最鄰近演算法都在相異性矩陣上執行。在使用這些演算法之前,可以把資料矩陣轉換成相異性矩陣。
3、標稱屬性的鄰近性度量
標稱屬性可以去兩個或者多個狀態,類似於java語言中的列舉型別。設一個標稱屬性的狀態的數目是M。這些狀態可以用字母、數字或者一組整數表示。注意這些整數只是用於資料處理,並不代表任何特定的順序。兩個物件i和j之間的相異性可以根據不匹配率來計算:
d(i, j) = (p - m)/p
其中,m是匹配的數目(即i和j取值相同狀態的屬性值),而p是刻畫物件的屬性總數。我們可以通過賦予m較大的權重,或者賦給有多狀態的屬性的匹配更大的權重來增加m的影響。
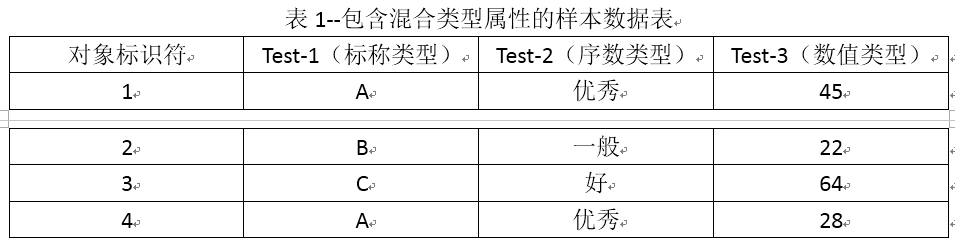
例如:因為表1中只有Test-1的資料型別是標稱型的,於是我們得到相異矩陣:

標稱屬性刻畫的物件之間的鄰近性也可以使用編碼方案計算。標稱屬性可以按以下方法用非對稱的二元屬性編碼:對M種狀態的每個狀態建立一個新的二元屬性。對於一個具有給定狀態值得物件,對應於該狀態的二元屬性值為1,而其餘的二元屬性值都設定為0。
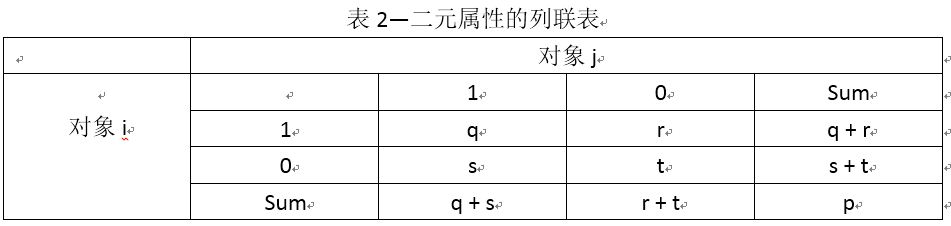
4、 二元屬性的鄰近性度量
我們考察用對稱和非對稱的二元屬性刻畫物件間的相異性和相似性度量。二元屬性的狀態只有兩種:0和1,其中0表示該屬性不出現,1表示該屬性出現。像對待數值一樣來處理二元屬性會誤導。因此,要採用特定的方法來計算二元資料的相異性。
一種方法涉及由給定的二元資料計算相異性矩陣。如果所有的二元都被看作具有相同的權重,則我們得到一個二元屬性的列聯表(表2),其中q是物件i和j都取1的屬性數,r是物件i取1、在物件j取0的屬性數,s是物件i取0、物件j取1的屬性數,t是物件i和物件j都取0的屬性數。屬性的總數是p。其中p = q + r + s + t 。
對稱的二元屬性
對於對稱的二元屬性,每個狀態都同樣重要。基於對稱二元屬性的相異性稱作對稱的二元相異性。如果物件i和j都用對稱的二元屬性刻畫,則物件i和j的相異性為:
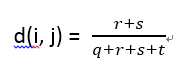
非對稱的二元屬性
非對稱的二元屬性的兩種狀態不是同等重要的。給定兩個非對稱的二元屬性,兩個都取1的情況(正匹配)被認為比兩個都取0的情況(負匹配)更有意義。因此,這樣的二元屬性經常被認為是“一元”的(只有一種狀態)。基於這種屬性的相異性被稱之為非對稱的二元相異性,其中負匹配t被認為是不重要的,因此在計算中被忽略,如下所示:
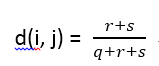
互補地,我們可以基於相似性而不是基於相異性來度量兩個二元屬性的差別。例如,物件i和j之間的非對稱的二元形似性可以用下式來計算:
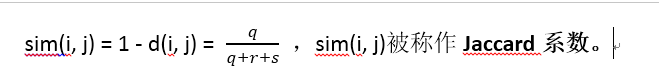
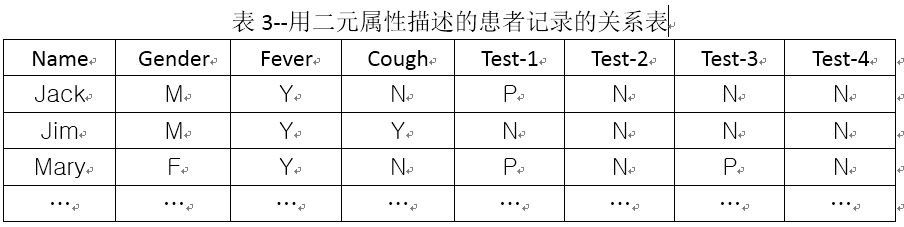
例:假設一個患者記錄表(表3—用二元屬性描述的患者記錄的關係表)包含屬性name、gender、fever、cougn、test-1、test-2、test-3和test-4,其中name是物件識別符號,gender是對稱屬性,其他的是非對稱屬性。
對於非對稱屬性,值Y(yes)和P(position)被設定成1,值N(no或者negative)被設定成0。假設物件(患者)之間的距離只是基於非對稱屬性來計算。那麼,三個患者倆倆之間的距離(相異性)如下:
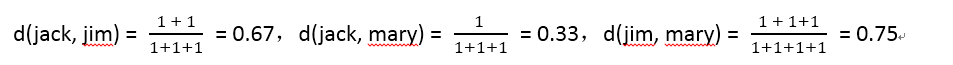
5、數值屬性的相異性:閔科夫斯基距離
歐幾里得距離
即,直線或者“烏鴉飛行”距離。令i = (xi1, xi2, ….. , xip)和j = (xj1, xj2, ….. , xjp)是兩個被p個數值屬性描述的物件。物件i和j之間的歐幾里得距離定義為:
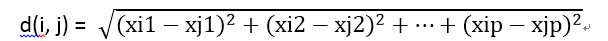
曼哈頓(或城市塊距離)距離,曼哈頓距離定義為:
d(i, j) = |xi1 – xj1| + |xi2 – xj2| + …. + |xip - xjp|
歐幾里得距離和曼哈頓距離有如下數學性質:
非負性 : d(i, j) >= 0 距離是一個非負的數值;
同一性 : d(i, j) == 0 物件到自身的距離為0;
對稱性 : d(i, j) = d(j, i) 距離是一個對稱函式;
三角不等式 :d(i, j) <= d(i, k) + d(k, j) 從物件i到物件j的直接距離不會大於途徑任何其他物件k的距離。
滿足這些條件的測度(measure)稱作度量(metric)。
閔科夫斯基距離(Minkowski distance)是歐幾里得距離和曼哈頓距離的推廣,定義為:
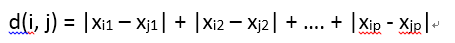
在某些文獻中這種距離被稱之為Lp 範數(norm)。當p = 1時,它表示曼哈頓距離;當p = 2時,它表示歐幾里得距離。
上確界距離
又稱之為Lmax ,L∞ 範數和切比雪夫(Chebyshev)距離。是h→∞時閔科夫斯基的推廣。定義為:
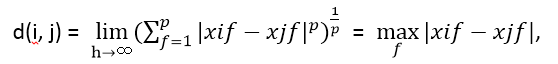
L∞ 範數也稱之為一致範數。
如果對每個變數根據其重要性賦予一個權重,則加權的歐幾里得距離可以用下式計算:
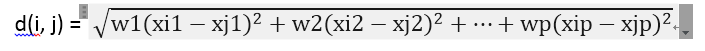
6、混合型別屬性的相異性
在許多實際的資料庫中,物件被混合型別的屬性描述。一般來說,一個數據庫可能包含標稱的、對稱二元的、非對稱二元的、數值的和序數的資料型別。那麼,如何計算這些由混合資料型別刻畫的物件之間的相異性呢 ?一種可取的辦法是將所有的屬性一起處理,只做一次分析。一種這樣的技術將不同的屬性組合在單個相異性矩陣中表,把所有有意義的屬性轉換到共同的區間[0.0, 1.0]。
