
MXnet程式碼實戰之多層感知機
阿新 • • 發佈:2019-02-05
多層感知機介紹
多層感知器(MLP,Multilayer Perceptron)是一種前饋人工神經網路模型。與上文提到的多類邏輯迴歸非常相似,主要區別在:輸入層和輸出層之間插入了一個到多個隱含層。
如下圖,黃色的點為輸入層,中間為隱含層,綠色的點為輸出層:
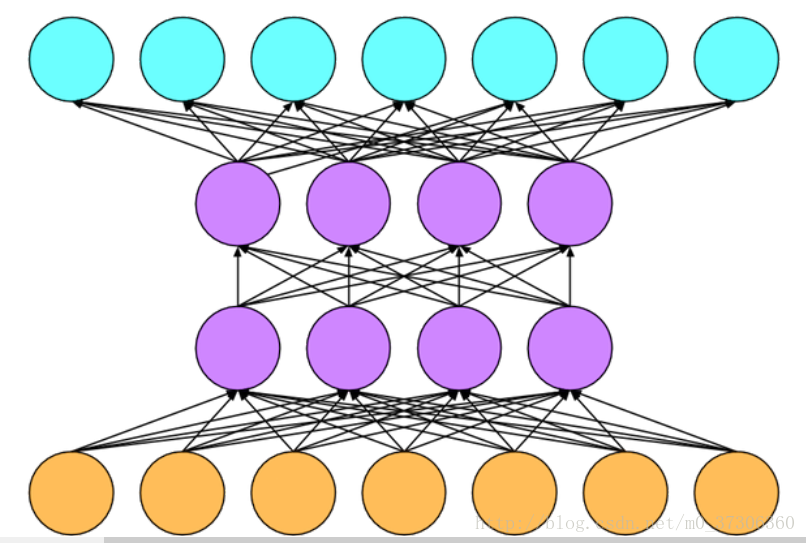
這裡可以思考一個問題:為什麼要使用啟用函式。如果我們不用啟用函式,僅僅使用線性操作,那上圖y^ = X · W1 · W2 = X · W3,這完全等價於用一個隱含層。推廣到一般情況,即使設定了一百個隱含層,也會等價於只用一個隱含層。所以我們要在層之間插入非線性的啟用函式。
從0開始學習實現多層感知機
程式碼
#!/usr/bin/env python 多層感知機—使用 Gluon
程式碼:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#Author: yuquanle
#2017/10/14
#沐神教程實戰之多層感知機做分類
#本例子使用一個類似MNIST的資料集做分類,MNIST是分類數字,這個資料集分類服飾
from mxnet import ndarray as nd
import utils
batch_size = 256
train_data, test_data = utils.load_data_fashion_mnist(batch_size)
num_inputs = 28*28
num_outputs = 10
num_hidden = 256
weight_scale = 0.01
W1 = nd.random_normal(shape=(num_inputs, num_hidden), scale=weight_scale)
b1 = nd.zeros(num_hidden)
W2 = nd.random_normal(shape=(num_hidden, num_outputs), scale=weight_scale)
b2 = nd.zeros(num_outputs)
params = [W1, b1, W2, b2]
for param in params:
param.attach_grad()
# 定義激勵函式
def relu(X):
return nd.maximum(X, 0)
# 定義模型
def net(X):
# 輸入資料轉換成? * num_inputs。?為輸入樣本條數
X = X.reshape((-1, num_inputs))
# h1為隱藏層的輸出
h1 = relu(nd.dot(X, W1) + b1)
# 通過全連線將隱藏層的輸出對映到輸出層
output = nd.dot(h1, W2) + b2
return output
#
from mxnet import gluon
softmax_cross_entropy = gluon.loss.SoftmaxCrossEntropyLoss()
#
from mxnet import autograd as autograd
learning_rate = 0.5
for epoch in range(5):
train_loss = 0.
train_acc = 0.
for data, label in train_data:
with autograd.record():
output = net(data)
loss = softmax_cross_entropy(output, label)
loss.backward()
utils.SGD(params, learning_rate / batch_size)
train_loss += nd.mean(loss).asscalar()
train_acc += utils.accuracy(output, label)
test_acc = utils.evaluate_accuracy(test_data, net)
print("Epoch %d. Loss: %f, Train acc %f, Test acc %f" % (
epoch, train_loss / len(train_data),
train_acc / len(train_data), test_acc))