
文件排序--相似度模型--VSM
說明:文章內容來源於課程視訊和課程ppt。我只學習了課程沒有做習題。文章不是翻譯,是我對課程的理解。
上文提到文件排序函式是TR的核心。文件排序函式的實現有幾種思路,其中一種是基於相似度的模型。這種模型具體是用空間向量模型(Vector Space Model)實現。這篇文章就介紹VSM。
VSM概念
什麼是VSM
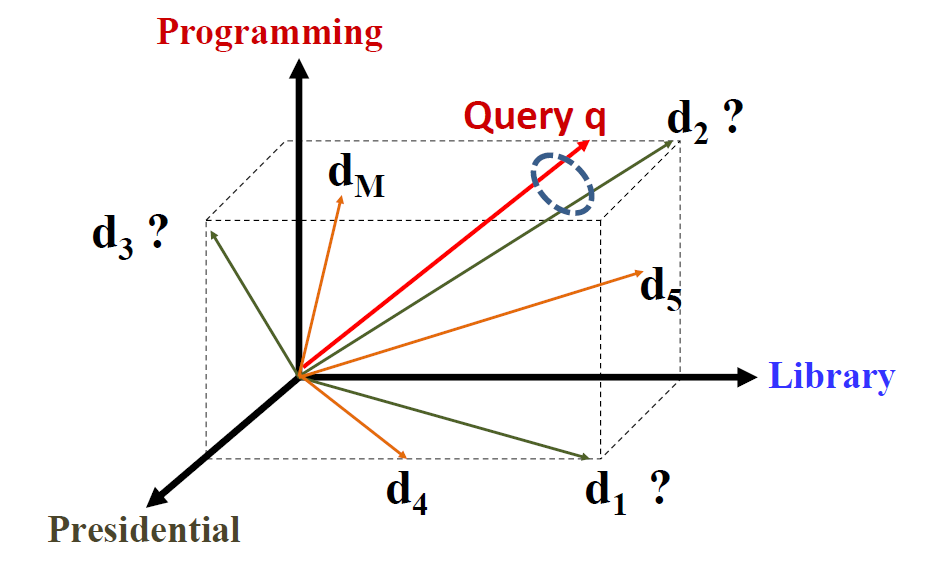
VSM定義了兩點。
第一,用詞向量(term vector)來表示查詢語句、表示文件。英文中的term vector,我們翻譯為詞向量。但是這裡的“詞”並不是指漢語中的一個詞,具體含義是:基本概念,可以是一個字、一個詞、一個短語。每個詞表示一個維度,N個詞就可以定義N維空間。如上圖所示,programming,libarary,presidential,分別定義了三個維度。查詢語句的向量表示:
第二,查詢語句和文件的相關度正比於查詢語句和文件的相似度:
VSM沒有定義的
1 怎麼定義或者說怎麼選擇term。只說term是文件集中的基本概念,並未指明什麼可以作為term。
2 向量的表示。用什麼值來計算查詢向量和文件向量。
3 相似度怎麼計算。
基於以上幾點說VSM其實是一個框架frame。在實踐中有好多版本的實現。繼續往下看。
VSM實現
來源於ppt的例子。
query=”news about presidential campaign”
d1:”… news about …”
d2:”… news about organic food campaign…”
d3:”… news of presidential campaign …”
d4:”… news of presidential campaign … … presidential candidate …”
d5:”… news of organic food campaign… campaign…campaign…campaign…”
在這個例子中很理想的排序大概應該是:d4,d3。d1,d2,d5其實是不相關文件。
簡單實現
BOW+bit-vector+dotproduct 這是一個最簡單的實現。
1 用文件中的每一個詞定義一個維度。稱為詞袋模型(Bag of Word=BOW)。
2 用Bit-Vector 表示向量。如果詞出現則記為1,否則為0。。
3 相似度通過點積(dot product)計算。
最終表示
計算一下例子。
V= {news, about, presidential, campaign, food …. }
q= (1, 1, 1, 1, 0, …)
d1= (1, 1, 0, 0, 0, …)
d2= (1, 1, 0, 1, 0, …)
d3= (1, 0, 1, 1, 0, …)
…
f(q,d1)=1*1+1*1+0…=2
f(q,d2)=1*1+1*1+0+1*1+…=3
…
本演算法中sim(q,d)函式的實質就是表示有多少個不同的查詢詞出現在文件中。
在d2,d3,d4文件中各出現了3次,值為3,;在d1,d5文件中各出現了2次,值為2。
進階實現
BOW+term frequency+dotproduct
問題:d4中 “presidential ”的次數要比d2多,應該排在前面才對。
解決策略就是使用詞頻這個資訊。
最終表示
是詞在查詢語句中出現次數
是詞在文件中出現次數
計算一下例子。
f(q,d4)=1*1+1*0+1*2+1*1+0+…=4
f(q,d2)=….
….
TD-IDF
BOW+TF-IDF+dotproduct

問題:d2與d3,雖然都命中3個詞,但是顯然命中presidential比命中about得分要高。presidential含有更重要的資訊嘛。
解決策略:使用逆文件頻率IDF,在越多文件中出現,權重越低。