
資料傾斜是多麼痛?spark作業調優祕籍
有的時候,我們可能會遇到大資料計算中一個最棘手的問題——資料傾斜,此時Spark作業的效能會比期望差很多。資料傾斜調優,就是使用各種技術方案解決不同型別的資料傾斜問題,以保證Spark作業的效能。
資料傾斜是多麼痛?!!!
資料傾斜如果能夠解決的話,代表對spark執行機制瞭如指掌。
資料傾斜倆大直接致命後果。
2 執行速度慢,特別慢,非常慢,極端的慢,不可接受的慢。
我們以100億條資料為列子。
個別Task(80億條資料的那個Task)處理過度大量資料。導致拖慢了整個Job的執行時間。這可能導致該Task所在的機器OOM,或者執行速度非常慢。
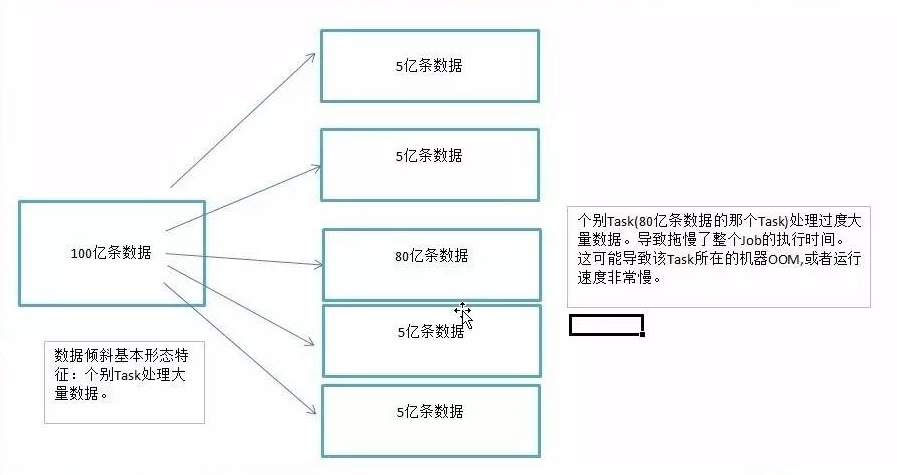
而這樣的場景太常見了。二八定律可以證實這種場景。
搞定資料傾斜需要:
2 搞定業務場景
4 搞定OOM的根本原因等。
告訴大家一個屢試不爽的經驗結論:一般情況下,OOM的原因都是資料傾斜。某個task任務資料量太大,GC的壓力就很大。這比不了Kafka,因為kafka的記憶體是不經過JVM的。是基於Linux核心的Page.
資料傾斜發生的原理
資料傾斜只會發生在shuffle過程中。這裡給大家羅列一些常用的並且可能會觸發shuffle操作的運算元:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。出現數據傾斜時,可能就是你的程式碼中使用了這些運算元中的某一個所導致的。
首先要看的,就是資料傾斜發生在第幾個stage中。
如果是用yarn-client模式提交,那麼本地是直接可以看到log的,可以在log中找到當前執行到了第幾個stage;如果是用yarn-cluster模式提交,則可以通過Spark Web UI來檢視當前執行到了第幾個stage。此外,無論是使用yarn-client模式還是yarn-cluster模式,我們都可以在Spark Web UI上深入看一下當前這個stage各個task分配的資料量,從而進一步確定是不是task分配的資料不均勻導致了資料傾斜。
比如下圖中,倒數第三列顯示了每個task的執行時間。明顯可以看到,有的task執行特別快,只需要幾秒鐘就可以執行完;而有的task執行特別慢,需要幾分鐘才能執行完,此時單從執行時間上看就已經能夠確定發生資料傾斜了。此外,倒數第一列顯示了每個task處理的資料量,明顯可以看到,執行時間特別短的task只需要處理幾百KB的資料即可,而執行時間特別長的task需要處理幾千KB的資料,處理的資料量差了10倍。此時更加能夠確定是發生了資料傾斜。
知道資料傾斜發生在哪一個stage之後,接著我們就需要根據stage劃分原理,推算出來發生傾斜的那個stage對應程式碼中的哪一部分,這部分程式碼中肯定會有一個shuffle類運算元。精準推算stage與程式碼的對應關係,需要對Spark的原始碼有深入的理解,這裡我們可以介紹一個相對簡單實用的推算方法:只要看到Spark程式碼中出現了一個shuffle類運算元或者是Spark SQL的SQL語句中出現了會導致shuffle的語句(比如group by語句),那麼就可以判定,以那個地方為界限劃分出了前後兩個stage。
這裡我們就以Spark最基礎的入門程式——單詞計數來舉例,如何用最簡單的方法大致推算出一個stage對應的程式碼。如下示例,在整個程式碼中,只有一個reduceByKey是會發生shuffle的運算元,因此就可以認為,以這個運算元為界限,會劃分出前後兩個stage。
1、stage0,主要是執行從textFile到map操作,以及執行shuffle write操作。shuffle write操作,我們可以簡單理解為對pairs RDD中的資料進行分割槽操作,每個task處理的資料中,相同的key會寫入同一個磁碟檔案內。
2、stage1,主要是執行從reduceByKey到collect操作,stage1的各個task一開始執行,就會首先執行shuffle read操作。執行shuffle read操作的task,會從stage0的各個task所在節點拉取屬於自己處理的那些key,然後對同一個key進行全域性性的聚合或join等操作,在這裡就是對key的value值進行累加。stage1在執行完reduceByKey運算元之後,就計算出了最終的wordCounts RDD,然後會執行collect運算元,將所有資料拉取到Driver上,供我們遍歷和列印輸出。
val conf = new SparkConf()
val sc = new SparkContext(conf)
val lines = sc.textFile("hdfs://...")
val words = lines.flatMap(_.split(" "))
val pairs = words.map((_, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.collect().foreach(println(_))
解決方案一:使用Hive ETL預處理資料
解決方案二:過濾少數導致傾斜的key
解決方案三:提高shuffle操作的並行度
方案適用場景:對RDD執行reduceByKey等聚合類shuffle運算元或者在Spark SQL中使用group by語句進行分組聚合時,比較適用這種方案。
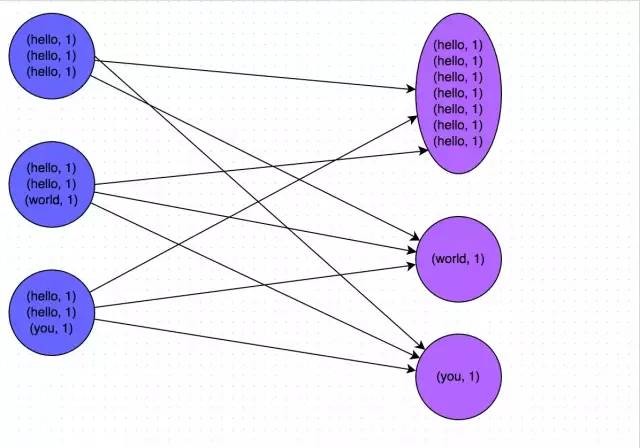
方案實現思路:這個方案的核心實現思路就是進行兩階段聚合。第一次是區域性聚合,先給每個key都打上一個隨機數,比如10以內的隨機數,此時原先一樣的key就變成不一樣的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就會變成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接著對打上隨機數後的資料,執行reduceByKey等聚合操作,進行區域性聚合,那麼區域性聚合結果,就會變成了(1_hello, 2) (2_hello,
2)。然後將各個key的字首給去掉,就會變成(hello,2)(hello,2),再次進行全域性聚合操作,就可以得到最終結果了,比如(hello, 4)。
方案實現原理:將原本相同的key通過附加隨機字首的方式,變成多個不同的key,就可以讓原本被一個task處理的資料分散到多個task上去做區域性聚合,進而解決單個task處理資料量過多的問題。接著去除掉隨機字首,再次進行全域性聚合,就可以得到最終的結果。具體原理見下圖。
方案優點:對於聚合類的shuffle操作導致的資料傾斜,效果是非常不錯的。通常都可以解決掉資料傾斜,或者至少是大幅度緩解資料傾斜,將Spark作業的效能提升數倍以上。
方案缺點:僅僅適用於聚合類的shuffle操作,適用範圍相對較窄。如果是join類的shuffle操作,還得用其他的解決方案。
方案適用場景:在對RDD使用join類操作,或者是在Spark SQL中使用join語句時,而且join操作中的一個RDD或表的資料量比較小(比如幾百M或者一兩G),比較適用此方案。
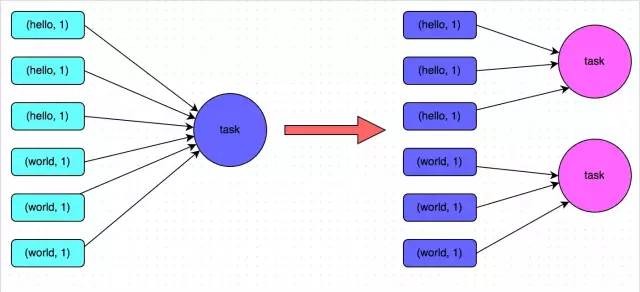
方案實現思路:不使用join運算元進行連線操作,而使用Broadcast變數與map類運算元實現join操作,進而完全規避掉shuffle類的操作,徹底避免資料傾斜的發生和出現。將較小RDD中的資料直接通過collect運算元拉取到Driver端的記憶體中來,然後對其建立一個Broadcast變數;接著對另外一個RDD執行map類運算元,在運算元函式內,從Broadcast變數中獲取較小RDD的全量資料,與當前RDD的每一條資料按照連線key進行比對,如果連線key相同的話,那麼就將兩個RDD的資料用你需要的方式連線起來。
方案實現原理:普通的join是會走shuffle過程的,而一旦shuffle,就相當於會將相同key的資料拉取到一個shuffle read task中再進行join,此時就是reduce join。但是如果一個RDD是比較小的,則可以採用廣播小RDD全量資料+map運算元來實現與join同樣的效果,也就是map join,此時就不會發生shuffle操作,也就不會發生資料傾斜。具體原理如下圖所示。
方案優點:對join操作導致的資料傾斜,效果非常好,因為根本就不會發生shuffle,也就根本不會發生資料傾斜。
方案缺點:適用場景較少,因為這個方案只適用於一個大表和一個小表的情況。畢竟我們需要將小表進行廣播,此時會比較消耗記憶體資源,driver和每個Executor記憶體中都會駐留一份小RDD的全量資料。如果我們廣播出去的RDD資料比較大,比如10G以上,那麼就可能發生記憶體溢位了。因此並不適合兩個都是大表的情況。
方案適用場景:兩個RDD/Hive表進行join的時候,如果資料量都比較大,無法採用“解決方案五”,那麼此時可以看一下兩個RDD/Hive表中的key分佈情況。如果出現數據傾斜,是因為其中某一個RDD/Hive表中的少數幾個key的資料量過大,而另一個RDD/Hive表中的所有key都分佈比較均勻,那麼採用這個解決方案是比較合適的。
方案實現思路:
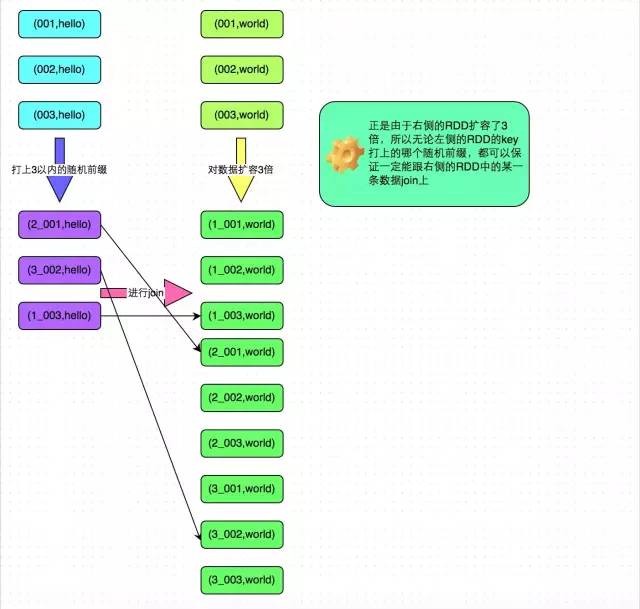
1、對包含少數幾個資料量過大的key的那個RDD,通過sample運算元取樣出一份樣本來,然後統計一下每個key的數量,計算出來資料量最大的是哪幾個key。
2、然後將這幾個key對應的資料從原來的RDD中拆分出來,形成一個單獨的RDD,並給每個key都打上n以內的隨機數作為字首,而不會導致傾斜的大部分key形成另外一個RDD。
3、接著將需要join的另一個RDD,也過濾出來那幾個傾斜key對應的資料並形成一個單獨的RDD,將每條資料膨脹成n條資料,這n條資料都按順序附加一個0~n的字首,不會導致傾斜的大部分key也形成另外一個RDD。
4、再將附加了隨機字首的獨立RDD與另一個膨脹n倍的獨立RDD進行join,此時就可以將原先相同的key打散成n份,分散到多個task中去進行join了。
5、而另外兩個普通的RDD就照常join即可。
6、最後將兩次join的結果使用union運算元合併起來即可,就是最終的join結果。
方案實現原理:對於join導致的資料傾斜,如果只是某幾個key導致了傾斜,可以將少數幾個key分拆成獨立RDD,並附加隨機字首打散成n份去進行join,此時這幾個key對應的資料就不會集中在少數幾個task上,而是分散到多個task進行join了。具體原理見下圖。
方案優點:對於join導致的資料傾斜,如果只是某幾個key導致了傾斜,採用該方式可以用最有效的方式打散key進行join。而且只需要針對少數傾斜key對應的資料進行擴容n倍,不需要對全量資料進行擴容。避免了佔用過多記憶體。
方案缺點:如果導致傾斜的key特別多的話,比如成千上萬個key都導致資料傾斜,那麼這種方式也不適合。
// 首先從包含了少數幾個導致資料傾斜key的rdd1中,取樣10%的樣本資料。
JavaPairRDD sampledRDD = rdd1.sample(false, 0.1);
// 對樣本資料RDD統計出每個key的出現次數,並按出現次數降序排序。
// 對降序排序後的資料,取出top 1或者top 100的資料,也就是key最多的前n個數據。
// 具體取出多少個數據量最多的key,由大家自己決定,我們這裡就取1個作為示範。
JavaPairRDD mappedSampledRDD = sampledRDD.mapToPair(
new PairFunction<tuple2, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2 call(Tuple2 tuple)
throws Exception {
return new Tuple2(tuple._1, 1L);
}
});
JavaPairRDD countedSampledRDD = mappedSampledRDD.reduceByKey(
new Function2() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
JavaPairRDD reversedSampledRDD = countedSampledRDD.mapToPair(
new PairFunction<tuple2, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2 call(Tuple2 tuple)
throws Exception {
return new Tuple2(tuple._2, tuple._1);
}
});
final Long skewedUserid = reversedSampledRDD.sortByKey(false).take(1).get(0)._2;
// 從rdd1中分拆出導致資料傾斜的key,形成獨立的RDD。
JavaPairRDD skewedRDD = rdd1.filter(
new Function<tuple2, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2 tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
});
// 從rdd1中分拆出不導致資料傾斜的普通key,形成獨立的RDD。
JavaPairRDD commonRDD = rdd1.filter(
new Function<tuple2, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2 tuple) throws Exception {
return !tuple._1.equals(skewedUserid);
}
});
// rdd2,就是那個所有key的分佈相對較為均勻的rdd。
// 這裡將rdd2中,前面獲取到的key對應的資料,過濾出來,分拆成單獨的rdd,並對rdd中的資料使用flatMap運算元都擴容100倍。
// 對擴容的每條資料,都打上0~100的字首。
JavaPairRDD skewedRdd2 = rdd2.filter(
new Function<tuple2, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2 tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
}).flatMapToPair(new PairFlatMapFunction<tuple2, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<tuple2> call(
Tuple2 tuple) throws Exception {
Random random = new Random();
List<tuple2> list = new ArrayList<tuple2>();
for(int i = 0; i < 100; i++) { list.add(new Tuple2(i + "_" + tuple._1, tuple._2));
}
return list;
}
});
// 將rdd1中分拆出來的導致傾斜的key的獨立rdd,每條資料都打上100以內的隨機字首。
// 然後將這個rdd1中分拆出來的獨立rdd,與上面rdd2中分拆出來的獨立rdd,進行join。
JavaPairRDD<long, tuple2> joinedRDD1 = skewedRDD.mapToPair(
new PairFunction<tuple2, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2 call(Tuple2 tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(100);
return new Tuple2(prefix + "_" + tuple._1, tuple._2);
}
})
.join(skewedUserid2infoRDD)
.mapToPair(new PairFunction<tuple2<string,tuple2>, Long, Tuple2>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<long, tuple2> call(
Tuple2<string, tuple2> tuple)
throws Exception {
long key = Long.valueOf(tuple._1.split("_")[1]);
return new Tuple2<long, tuple2>(key, tuple._2);
}
});
// 將rdd1中分拆出來的包含普通key的獨立rdd,直接與rdd2進行join。
JavaPairRDD<long, tuple2> joinedRDD2 = commonRDD.join(rdd2);
// 將傾斜key join後的結果與普通key join後的結果,uinon起來。
// 就是最終的join結果。
JavaPairRDD<long, tuple2> joinedRDD = joinedRDD1.union(joinedRDD2);
解決方案七:使用隨機字首和擴容RDD進行join
解決方案八:多種方案組合使用 <h2 text-align:start;text-indent:0px;background-color:#ffffff;"="" style="box-sizing: border-box; margin: 20px 0px 10px; padding: 0px; font-weight: 400; line-height: 1.1; color: rgb(62, 62, 62); font-size: 18px;"> 在實踐中發現,很多情況下,如果只是處理較為簡單的資料傾斜場景,那麼使用上述方案中的某一種基本就可以解決。但是如果要處理一個較為複雜的資料傾斜場景,那麼可能需要將多種方案組合起來使用。比如說,我們針對出現了多個數據傾斜環節的Spark作業,可以先運用解決方案一和二,預處理一部分資料,並過濾一部分資料來緩解;其次可以對某些shuffle操作提升並行度,優化其效能;最後還可以針對不同的聚合或join操作,選擇一種方案來優化其效能。大家需要對這些方案的思路和原理都透徹理解之後,在實踐中根據各種不同的情況,靈活運用多種方案,來解決自己的資料傾斜問題。
來源:數盟