
反捲積(Deconvnet)視覺化CNN卷積層
繼上一篇總體上deconvolution networks大致可以分為以下3個方面:之後我想開始學一下CNN視覺化:通過deconv將CNN中conv得到的feature map還原到畫素空間,以觀察特定的feature map對哪些pattern的圖片敏感,這裡的deconv其實不是conv的可逆運算,只是conv的transpose,所以tensorflow裡一般取名叫transpose_conv。
一、相關理論
本篇博文主要講解2014年ECCV上的一篇經典文獻:《Visualizing and Understanding Convolutional Networks》,可以說是CNN領域視覺化理解的開山之作,這篇文獻告訴我們CNN的每一層到底學習到了什麼特徵,然後作者通過視覺化進行調整網路,提高了精度。
這篇文獻的目的,就是要通過特徵視覺化,告訴我們如何通過視覺化的角度,檢視你的精度確實提高了,你設計CNN學習到的特徵確實比較牛逼。這篇文獻是經典必讀文獻,才發表了一年多,引用次數就已經達到了好幾百,學習這篇文獻,對於我們今後深入理解CNN,具有非常重要的意義。總之這篇文章,牛逼哄哄。其實玩過caffe的digits的朋友應該知道,在digits上也可以視覺化每一層卷積,池化操作之後的特徵圖片。這點caffe比較好,適合懶人操作。
二、利用反捲積實現特徵視覺化
為了解釋卷積神經網路為什麼work,我們就需要解釋CNN的每一層學習到了什麼東西。為了理解網路中間的每一層,提取到特徵,paper通過反捲積的方法,進行視覺化。反捲積網路可以看成是卷積網路的逆過程。反捲積網路在文獻《Adaptive deconvolutional networks for mid and high level feature learning》中被提出,是用於無監督學習的。然而本文的反捲積過程並不具備學習的能力,僅僅是用於視覺化一個已經訓練好的卷積網路模型,沒有學習訓練的過程。
反捲積視覺化以各層得到的特徵圖作為輸入,進行反捲積,得到反捲積結果,用以驗證顯示各層提取到的特徵圖。
1、反池化過程
我們知道,池化是不可逆的過程,然而我們可以通過記錄池化過程中,最大啟用值得座標位置。然後在反池化的時候,只把池化過程中最大啟用值所在的位置座標的值啟用,其它的值置為0,當然這個過程只是一種近似,因為我們在池化的過程中,除了最大值所在的位置,其它的值也是不為0的。剛好最近幾天看到文獻:《Stacked What-Where Auto-encoders》,裡面有個反捲積示意圖畫的比較好,所有就截下圖,用這篇文獻的示意圖進行講解:
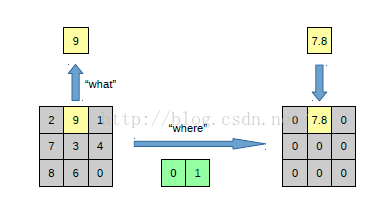
以上面的圖片為例,上面的圖片中左邊表示pooling過程,右邊表示unpooling過程。假設我們pooling塊的大小是3*3,採用max pooling後,我們可以得到一個輸出神經元其啟用值為9,pooling是一個下采樣的過程,本來是3*3大小,經過pooling後,就變成了1*1大小的圖片了。而upooling剛好與pooling過程相反,它是一個上取樣的過程,是pooling的一個反向運算,當我們由一個神經元要擴充套件到3*3個神經元的時候,我們需要藉助於pooling過程中,記錄下最大值所在的位置座標(0,1),然後在unpooling過程的時候,就把(0,1)這個畫素點的位置填上去,其它的神經元啟用值全部為0。再來一個例子:
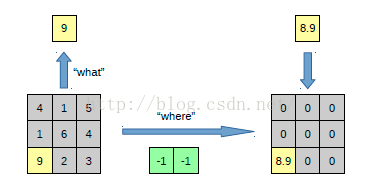
在max pooling的時候,我們不僅要得到最大值,同時還要記錄下最大值得座標(-1,-1),然後再unpooling的時候,就直接把(-1-1)這個點的值填上去,其它的啟用值全部為0。
2、反啟用
我們在Alexnet中,relu函式是用於保證每層輸出的啟用值都是正數,因此對於反向過程,我們同樣需要保證每層的特徵圖為正值,也就是說這個反啟用過程和啟用過程沒有什麼差別,都是直接採用relu函式。
3、反捲積
對於反捲積過程,採用卷積過程轉置後的濾波器(引數一樣,只不過把引數矩陣水平和垂直方向翻轉了一下),反捲積實際上應該叫卷積轉置。
最後視覺化網路結構如下:
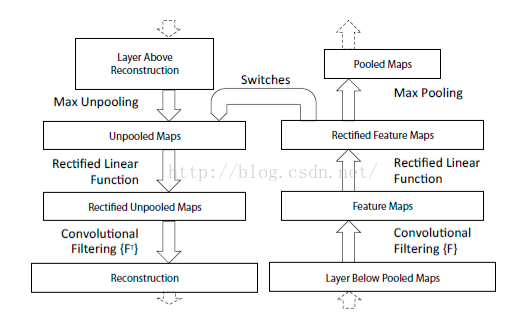
網路的整個過程,從右邊開始:輸入圖片-》卷積-》Relu-》最大池化-》得到結果特徵圖-》反池化-》Relu-》反捲積。到了這邊,可以說我們的演算法已經學習完畢了,其它部分是文獻要解釋理解CNN部分,可學可不學。
總的來說演算法主要有兩個關鍵點:1、反池化 2、反捲積,這兩個原始碼的實現方法,需要好好理解。
三、理解視覺化
特徵視覺化:一旦我們的網路訓練完畢了,我們就可以進行視覺化,檢視學習到了什麼東西。但是要怎麼看?怎麼理解,又是一回事了。我們利用上面的反捲積網路,對每一層的特徵圖進行檢視。
1、特徵視覺化結果:


總的來說,通過CNN學習後,我們學習到的特徵,是具有辨別性的特徵,比如要我們區分人臉和狗頭,那麼通過CNN學習後,背景部位的啟用度基本很少,我們通過視覺化就可以看到我們提取到的特徵忽視了背景,而是把關鍵的資訊給提取出來了。從layer 1、layer 2學習到的特徵基本上是顏色、邊緣等低層特徵;layer 3則開始稍微變得複雜,學習到的是紋理特徵,比如上面的一些網格紋理;layer 4學習到的則是比較有區別性的特徵,比如狗頭;layer 5學習到的則是完整的,具有辨別性關鍵特徵。
2、特徵學習的過程。作者給我們顯示了,在網路訓練過程中,每一層學習到的特徵是怎麼變化的,上面每一整張圖片是網路的某一層特徵圖,然後每一行有8個小圖片,分別表示網路epochs次數為:1、2、5、10、20、30、40、64的特徵圖:

結果:(1)仔細看每一層,在迭代的過程中的變化,出現了sudden jumps;(2)從層與層之間做比較,我們可以看到,低層在訓練的過程中基本沒啥變化,比較容易收斂,高層的特徵學習則變化很大。這解釋了低層網路的從訓練開始,基本上沒有太大的變化,因為梯度彌散嘛。(3)從高層網路conv5的變化過程,我們可以看到,剛開始幾次的迭代,基本變化不是很大,但是到了40~50的迭代的時候,變化很大,因此我們以後在訓練網路的時候,不要著急看結果,看結果需要保證網路收斂。
3、影象變換。從文獻中的圖片5視覺化結果,我們可以看到對於一張經過縮放、平移等操作的圖片來說:對網路的第一層影響比較大,到了後面幾層,基本上這些變換提取到的特徵沒什麼比較大的變化。
個人總結:我個人感覺學習這篇文獻的演算法,不在於視覺化,而在於學習反捲積網路,如果懂得了反捲積網路,那麼在以後的文獻中,你會經常遇到這個演算法。大部分CNN結構中,如果網路的輸出是一整張圖片的話,那麼就需要使用到反捲積網路,比如圖片語義分割、圖片去模糊、視覺化、圖片無監督學習、圖片深度估計,像這種網路的輸出是一整張圖片的任務,很多都有相關的文獻,而且都是利用了反捲積網路,取得了牛逼哄哄的結果。所以我覺得我學習這篇文獻,更大的意義在於學習反捲積網路。
參考文獻:
1、《Visualizing and Understanding Convolutional Networks》
推薦這篇文章比較詳細的進行了中文翻譯:http://www.360doc.com/content/15/0611/23/20625683_477507431.shtml
2、《Adaptive deconvolutional networks for mid and high level feature learning》
3、《Stacked What-Where Auto-encoders》
參考連結 https://blog.csdn.net/lemianli/article/details/53171951