
RNN,LSTM手寫陣列的識別,saver儲存以及載入。
阿新 • • 發佈:2019-02-06
(一)環境搭建:
Python3.5,TensorFlow1.0或者1.2,
(二)實驗描述:
利用TensorFlow中的rnn和lstm庫對手寫數字影象分類。
手寫數字資料,如果本地沒有,程式碼會自動連網下載(40m左右)
利用saver進行儲存,首先需要在程式碼的同級目錄下建立net資料夾
(三)結果展示:
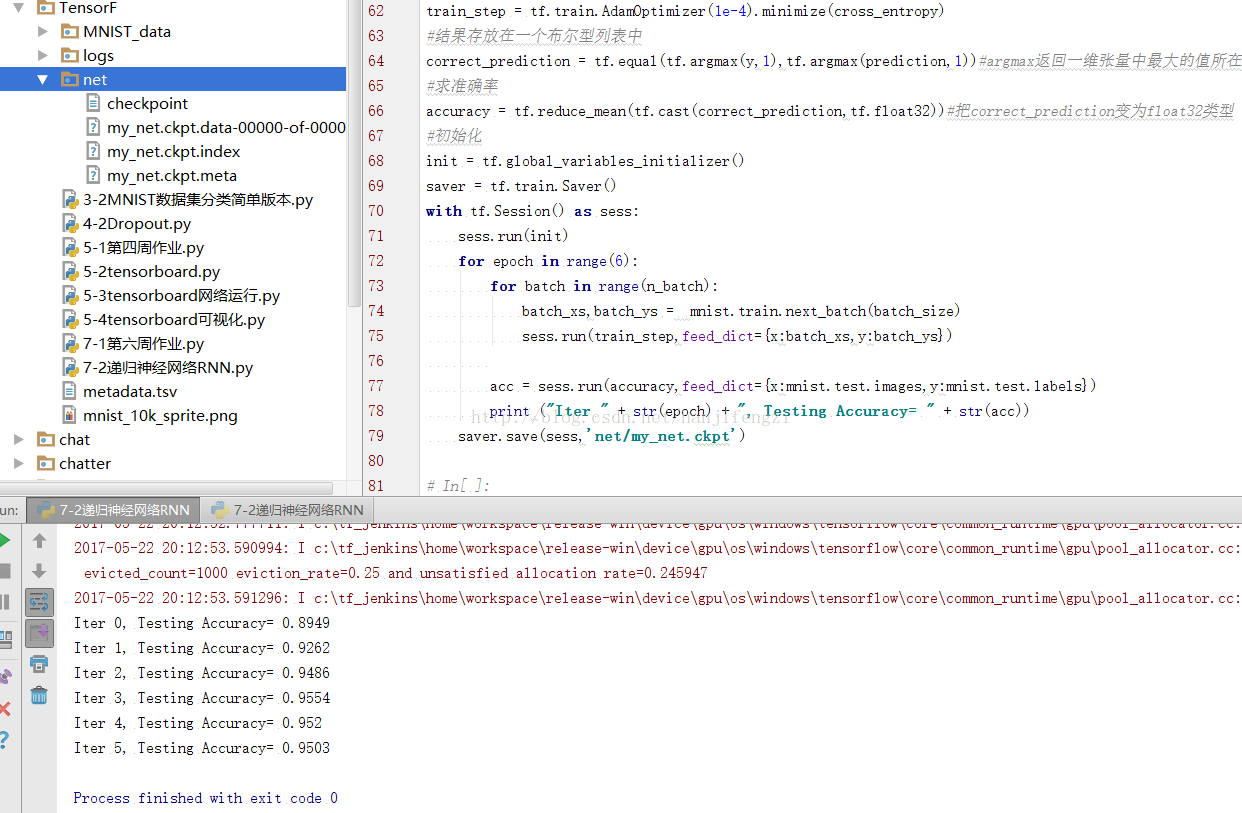
(四) 程式碼:
# coding: utf-8 # In[1]: import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # In[2]: #載入資料集 mnist = input_data.read_data_sets("MNIST_data/",one_hot=True) # 輸入圖片是28*28 n_inputs = 28 #輸入一行,一行有28個數據 max_time = 28 #一共28行 lstm_size = 500 #隱層單元 n_classes = 10 # 10個分類 batch_size = 50 #每批次50個樣本 n_batch = mnist.train.num_examples // batch_size #計算一共有多少個批次 print(n_batch) #這裡的none表示第一個維度可以是任意的長度 x = tf.placeholder(tf.float32,[None,784]) #正確的標籤 y = tf.placeholder(tf.float32,[None,10]) #初始化權值 weights = tf.Variable(tf.truncated_normal([lstm_size, n_classes], stddev=0.1)) #初始化偏置值 biases = tf.Variable(tf.constant(0.1, shape=[n_classes])) #定義RNN網路 def RNN(X,weights,biases): # inputs=[batch_size, max_time, n_inputs] inputs = tf.reshape(X,[-1,max_time,n_inputs]) #定義LSTM基本CELL lstm_cell = tf.contrib.rnn.core_rnn_cell.BasicLSTMCell(lstm_size) # final_state[0]是cell state # final_state[1]是hidden_state 最後500個隱藏單元的輸出結果, # output 與time.major 如果是false 返回是 batch_size=50次, maxtime=28的長度,cell.output_size:500個隱藏單元 # 但是time是 0到27,則cell.output_size 則表示對應時間的500個輸出結果。 # finale_state返回: # state【】 包括 cell_state 中間的celll, # hidden_state 最後的結果輸出。 # batch_size 50次 # state_size: 隱藏單元個數 500 # 隱藏層的單元個數, (batch次數,個數,資料數),格式 outputs,final_state = tf.nn.dynamic_rnn(lstm_cell,inputs,dtype=tf.float32) print(outputs[2]) results = tf.nn.softmax(tf.matmul(final_state[1],weights) + biases) return results #計算RNN的返回結果 prediction= RNN(x, weights, biases) #損失函式 cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction,labels=y)) #使用AdamOptimizer進行優化 train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) #結果存放在一個布林型列表中 correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))#argmax返回一維張量中最大的值所在的位置 #求準確率 accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))#把correct_prediction變為float32型別 #初始化 init = tf.global_variables_initializer() saver = tf.train.Saver() with tf.Session() as sess: sess.run(init) for epoch in range(6): for batch in range(n_batch): batch_xs,batch_ys = mnist.train.next_batch(batch_size) sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys}) acc = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels}) print ("Iter " + str(epoch) + ", Testing Accuracy= " + str(acc)) saver.save(sess,'net/my_net.ckpt') # In[ ]:
(五)檔案儲存,建立一個新的檔案,直接讀取原來的資料。
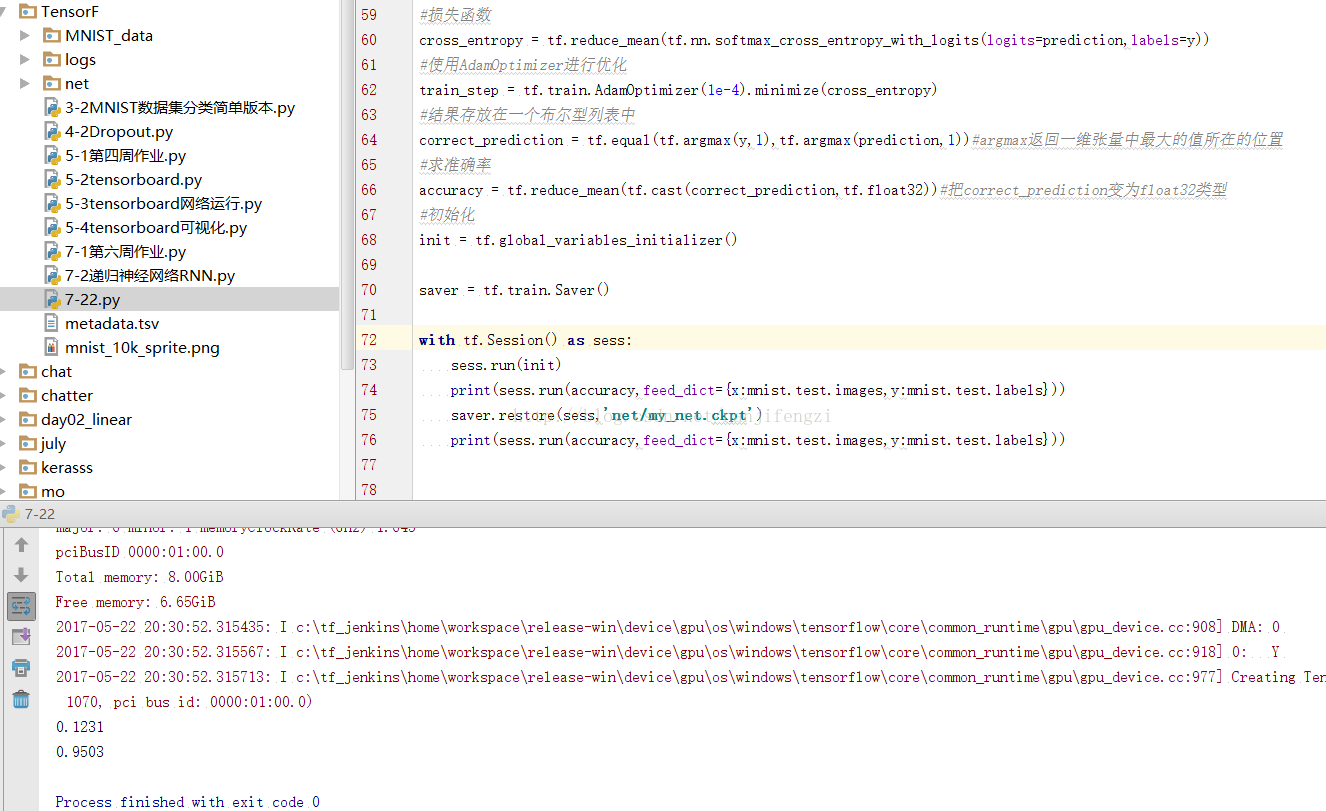
# coding: utf-8 # In[1]: import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # In[2]: #載入資料集 mnist = input_data.read_data_sets("MNIST_data",one_hot=True) #每個批次100張照片 batch_size = 100 #計算一共有多少個批次 n_batch = mnist.train.num_examples // batch_size #定義兩個placeholder x = tf.placeholder(tf.float32,[None,784]) y = tf.placeholder(tf.float32,[None,10]) #建立一個簡單的神經網路,輸入層784個神經元,輸出層10個神經元 W = tf.Variable(tf.zeros([784,10])) b = tf.Variable(tf.zeros([10])) prediction = tf.nn.softmax(tf.matmul(x,W)+b) #二次代價函式 # loss = tf.reduce_mean(tf.square(y-prediction)) loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction)) #使用梯度下降法 train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss) #初始化變數 init = tf.global_variables_initializer() #結果存放在一個布林型列表中 correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))#argmax返回一維張量中最大的值所在的位置 #求準確率 accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) saver = tf.train.Saver() with tf.Session() as sess: sess.run(init) print(sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})) saver.restore(sess,'net/my_net.ckpt') print(sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})) # In[ ]: