
tensorflow例項(7)--建立多層神經網路
阿新 • • 發佈:2019-02-06
本文將建立多層神經網路的函式,這個函式是一個簡單的通用函式,
通過最後的測試,可以建立一些多次方程的模型,並通過matplotlib.pyplot演示模型建立過程中的資料變化情況


如果你對神經網路不太瞭解可以參考我前面的一些文章,這裡列出一些主要的參考
機器學習(1)--神經網路初探
tensorflow例項(2)--機器學習初試
tensorflow例項(6)--機器學習中學習率的實驗
通過最後的測試,可以建立一些多次方程的模型,並通過matplotlib.pyplot演示模型建立過程中的資料變化情況
以下三張圖片是生成的效果,每張圖的藍點都表示為樣本值,紅點表示最終預測效果,本例帶有點動畫效果,可以更直觀的覺數值的變化
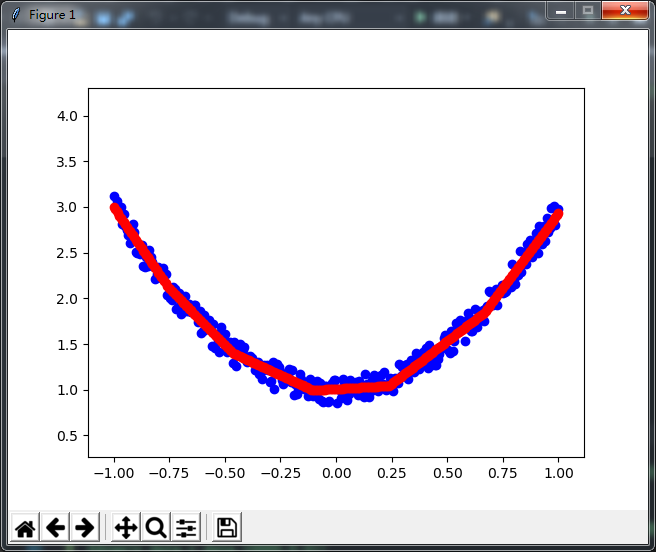
如果你對神經網路不太瞭解可以參考我前面的一些文章,這裡列出一些主要的參考
機器學習(1)--神經網路初探
tensorflow例項(2)--機器學習初試
tensorflow例項(6)--機器學習中學習率的實驗
#-*- coding:utf-8 -*- import matplotlib.pyplot as plt import numpy as np import tensorflow as tf def createData(ref): '''生成資料函式,ref 引數說明 本函式將生成一組的x,y資料,ref傳參為陣列,[a1,a2,a3,b] x將為一組300個的由-1至1的等分數列組成的陣列 y根據ref傳參,如上[a1,a2,a3,b],,y = a1*x3次方 + a2*x2次方 + a3*x + b +燥點 ''' x = x_data=np.linspace(-1,1,300).reshape(300,1) y = np.zeros(300).astype(np.float64).reshape(300,-1) yStr = "" for i in range(len(ref)): y = y + x ** (len(ref) - i - 1) * ref[i] yStr+= (" = " if yStr == "" else " + ") + str(ref[i]) + " * (" + str(x[3]) + ") ** " + str(len(ref) - i - 1) noise = max(y) * (np.random.uniform(-0.05,0.05,300)).reshape(300,-1) y = y + noise yStr = str(y[3]) + yStr + " + " + str(noise[3][0]) + "(noise)" print(yStr) return x,y def addLayer(inputData,input_size,output_size,activation_function=None): weight = tf.Variable(tf.random_uniform([input_size,output_size],-1,1))#初始化隨機,比全是零要好 b = tf.Variable(tf.random_uniform([output_size],-1,1))#這是來自tensorflow的建議,biases不為零比較較好 mat = tf.matmul(inputData,weight)+b #matul求矩陣乘法並加上biases if activation_function != None : mat = activation_function(mat) return mat def draw(x_data,y_data,trainTimes,learningRate): ''' trainTimes:訓練次數,當次x_data,y_data不同時,trainTimes與learningRate都必須適當調整 關於learningRate這裡不在詳細說明,可以參考我別的文章 ''' x = tf.placeholder(tf.float32,[None,1]) y = tf.placeholder(tf.float32,[None,1]) #在原始資料x_data與最後預測值之間加上一個20個神經元的神經網路層 #典型的三層網路,N個神級元,x_data,y_data 只有一個屬性,算是一個神經元,所以輸入是一個神經元,而隱藏層有N個神經元 layer1 = addLayer(x,1,20,activation_function=tf.nn.relu) prediction = addLayer(layer1,20,1) loss = tf.reduce_mean(tf.reduce_sum(tf.square(y - prediction),axis=1)) train=tf.train.GradientDescentOptimizer(learningRate).minimize(loss) sess=tf.Session() sess.run(tf.initialize_all_variables()) trainStepPrint=int(trainTimes/10) feed_dict={x:x_data,y:y_data} predictionStep=[] #用於儲存訓練過程中的預測結果 for i in range(trainTimes): sess.run(train,feed_dict=feed_dict) if i%trainStepPrint==0 or i<10:#分20次將計算的步驟值進行儲存,i<10 指最開始的10次,基本前面幾次的WEIGHT變化比較大,效果明顯 lossVal=sess.run(loss,feed_dict=feed_dict) print("步驟:%d, loss:%f"%(i,lossVal)) predictionStep.append(sess.run(prediction,{x:x_data}))#預測時並不需要傳參y_data lossVal=sess.run(loss,feed_dict=feed_dict) print("最後loss:%f"%(lossVal)) predictionStep.append(sess.run(prediction,{x:x_data}))#傳入最後結果 sess.close() plt.scatter(x_data,y_data,c='b') #藍點表示實際點 plt.ion() plt.show() predictionPlt=None for i in predictionStep: if predictionPlt!=None:predictionPlt.remove(); predictionPlt=plt.scatter(x_data,i,c='r') #紅點表示預測點 plt.pause(0.3) x_data,y_data = createData([2,0,1])# 2 * x平方 +1 完全的拋物線 draw(x_data,y_data,10000,0.1) #x_data,y_data = createData([2,2,2])# 2 * x平方 + 2*x + 2 拋物線的一部份,可自行取消註釋後執行 #draw(x_data,y_data,10000,0.1) #x_data,y_data = createData([1,0,2,0]) #3次方的試驗,x3次方+ 2*x 可自行取消註釋後執行 #draw(x_data,y_data,10000,0.01)