
Tensorflow MNIST淺層神經網路的解釋和答覆
阿新 • • 發佈:2019-01-07
看到之前的一篇博文:深入MNIST code測試,接連有讀者發問,關於其中的一些細節問題,這裡進行簡單的答覆。
Tensorflow中提供的示例中MNIST網路結構比較簡單,屬於淺層的神經網路,只有兩個卷積層和全連線層,我按照Caffe的網路結構繪製一個模型流程:
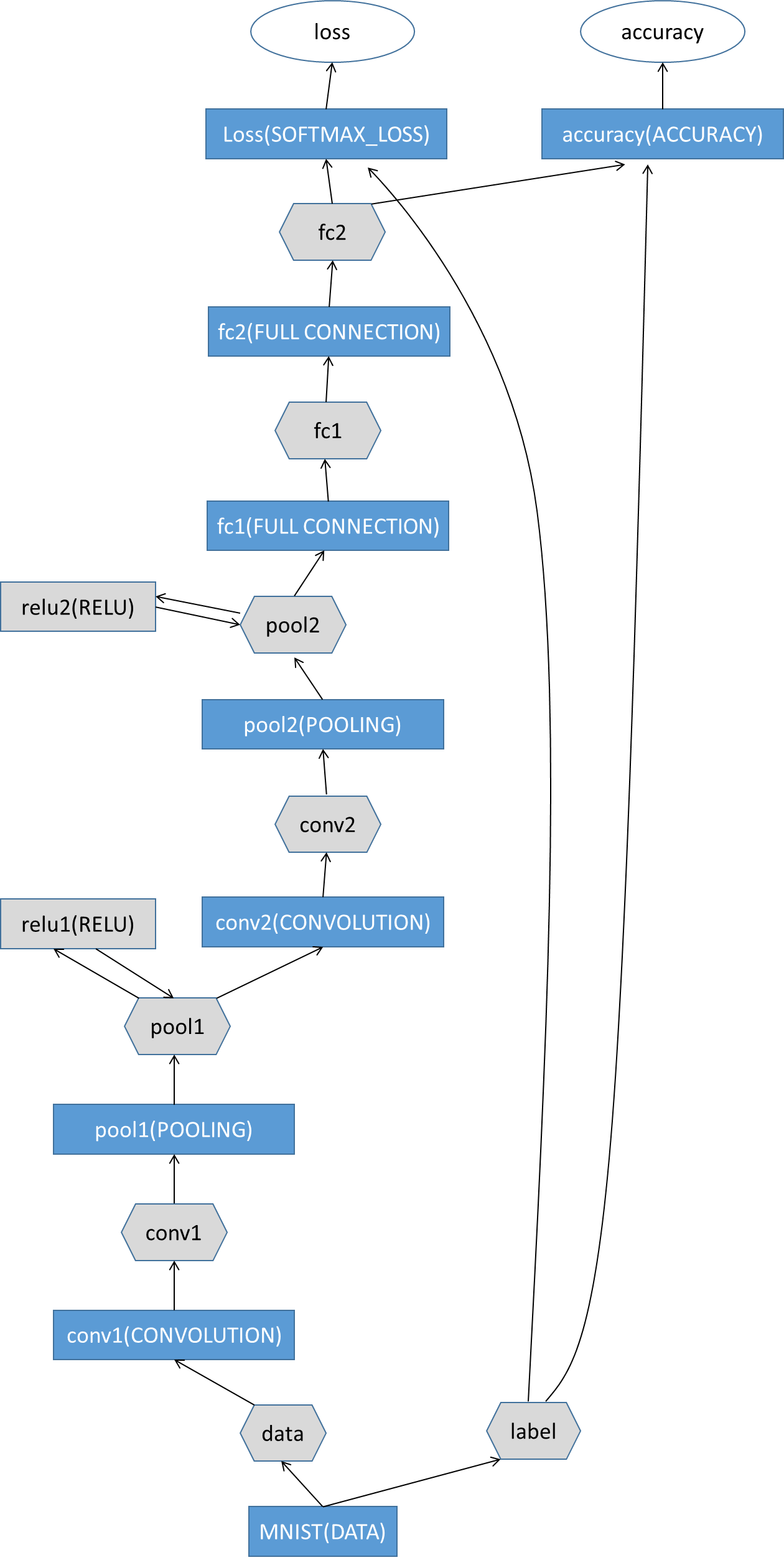
再附上每一層的具體引數網路(依舊仿照caffe的模式):

現在再來解釋一些讀著的疑問:
在卷積層
conv1和conv2中的32/64是什麼,怎麼來的?這裡它們指的其實就是卷積核的數量,這裡卷積核設定引數為[5,5,1,32], strides=[1,1,1,1], padding='SAME',分別解釋一下:[5,5,1,32]:卷積核為5x5的視窗,因為輸入影象是一通道灰度影象,所以第三引數為1,使用彩色影象時,一般設定為3,最後32就是指卷積核的數量,為什麼要使用這麼多卷積核呢?我理解的是,每種卷積只對某些特徵敏感,獲取的特徵很有限,因此將多種不同的卷積核分別對影象進行處理,就能獲得更多的特徵。每個卷積核按照規則掃描完影象後,就輸出一張特徵影象(feature map),因此32也指輸出的特徵圖。strides=[1,1,1,1]:指卷積視窗的滑動方式,這裡是指逐畫素滑動。padding='SAME':所謂的padding是為了解決影象邊緣部分的畫素,很容易想象,當卷積視窗不是一個畫素大小時,影象邊緣的部分割槽域是不能覆蓋的(或者說卷積視窗覆蓋該畫素時,部分視窗已經位於影象區域以外了),很簡單的做法是先將影象的拓展一下,使得位於邊緣區域的畫素也能進行卷積。SAME就是一種padding方法,即影象向四周拓展kernel_width/2和kernel_height/2個畫素。那麼這裡輸出的特徵影象的大小就為:28x28x32。- 同理
[5,5,32,64]可以理解。
關於
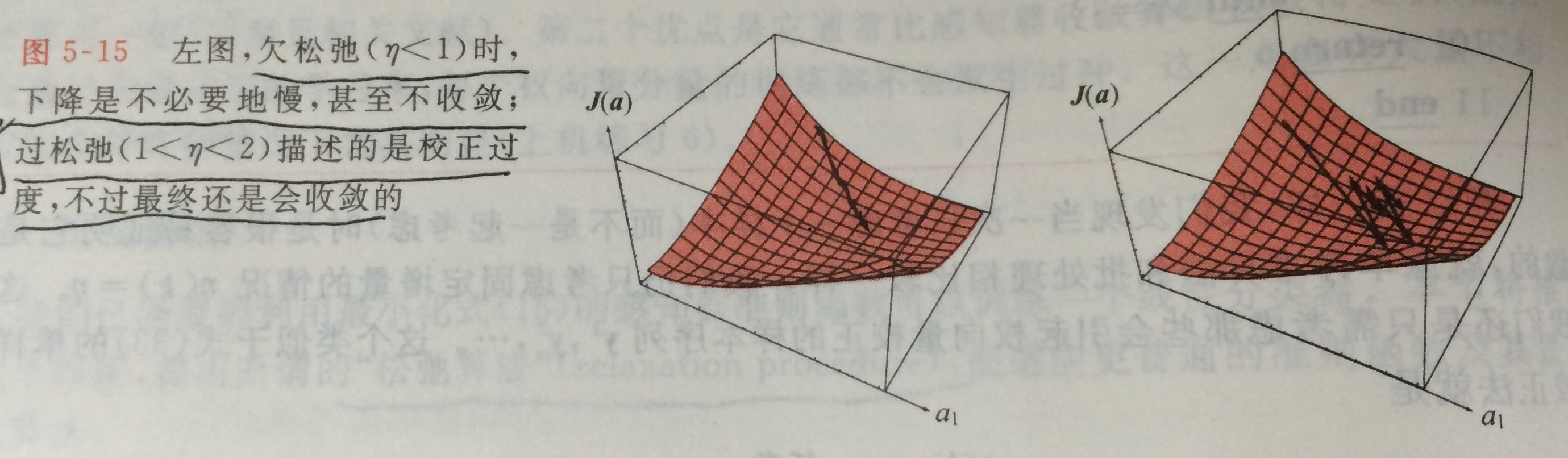
batch大小,我也沒有深入瞭解過,淺顯的理解為:訓練樣本有幾萬張,如果一起進行結算,其中的矩陣太過龐大,對於計算機來講非常有壓力,所以分批進行,這裡的50就是指每一批的訓練子資料的大小。至於訓練20000次,是否會導致同一個樣本的重複訓練?答案是絕對的,機器學習中,有bagging,random forests中有提到這方面的知識,想了解的話,可以自己閱讀相關論文。關於訓練中準確度反覆的現象,這是在正常不過的,要真正理解,首先需要自行補習關於梯度下降演算法的原理(這裡不詳細介紹),一般來講,我們希望優化演算法在最少步驟下收斂到理想的結果,但是難點在於如何在每一步優化的過程中提供最優的學習率,簡單的做法是給定固定的”學習率“,例如這裡設定的學習率是
1e-3,這樣做雖然不能保證每一步的優化是最優的,但是從大量的訓練測試來看,整體趨勢是朝著我們所想要的方向。最後附上一張圖:
解釋的比較簡單,有不準確的地方請指正,希望能幫到有疑惑的讀者,如有其它疑惑,大家一起探討。