
Web Spider實戰1——簡單的爬蟲實戰(爬取"豆瓣讀書評分9分以上榜單")
1、Web Spider簡介
Web Spider,又稱為網路爬蟲,是一種自動抓取網際網路網頁資訊的機器人。它們被廣泛用於網際網路搜尋引擎或其他類似網站,以獲取或更新這些網站的內容和檢索方式。它們可以自動採集所有其能夠訪問到的頁面內容,以供搜尋引擎做進一步處理(分檢整理下載的頁面),而使得使用者能更快的檢索到他們需要的資訊。
2、一個簡單的網路爬蟲案例
作者在瀏覽網頁的時候看到豆瓣書單的網頁(首頁),如下所示:
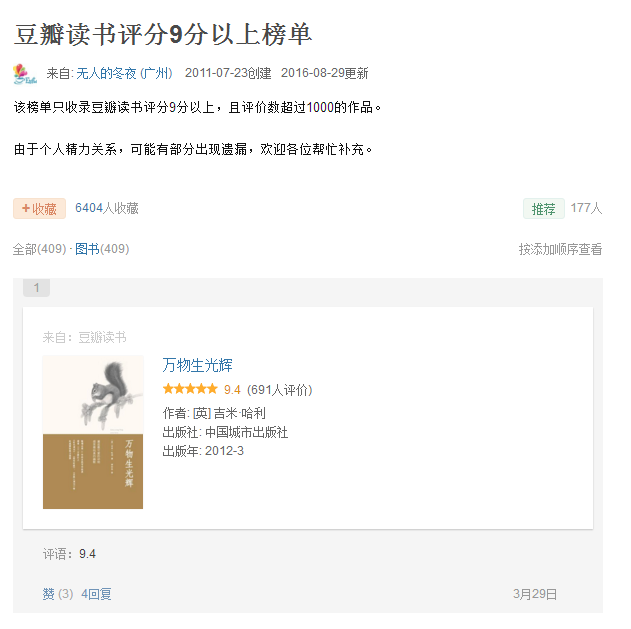
因為書單共有409本書,17個頁面,若是要一個個瀏覽完,需要較長的時間,想要儲存好書單,那是一件比較困難的事情,因此,想到是不是可以利用爬蟲(Web Spider)把書名都儲存下來,說幹就幹,下面詳細介紹一下如何利用Python爬取書單。
3、單頁面的抓取和分析
3.1、抓取
首先是單個頁面的抓取,這裡使用到了Python的urllib2庫,urllib2庫將網頁以HTML的形式抓取到本地,程式碼如下:
def spider(url, user_agent="wswp"): print "Downloading: ", url # 設定代理 headers = {"User-agent": user_agent} request = urllib2.Request(url, headers=headers) html = "" try: html = urllib2.urlopen(request).read() except urllib2.URLError as e: print "Download error: ", e.reason html = None return html
在抓取的過程中,使用到了Request方法,urlopen方法和read方法。通過以上簡單的抓取,將網頁以HTML的格式抓取到本地。
3.2、對抓取的頁面分析
在分析模組中主要是使用到了正則表示式,使用到了Python中的re庫,利用正則表示式提取出書的名字,如:

頁面的分析程式碼如下:
def parse_page(html): html = html.replace("\r", "") html = html.replace("\n", "") html = html.replace("\013", "") result = re.findall('<div class="title">(.*?)</div>', html) book_list = [] for x in result: # 得到書名 book_name = re.findall('<a.*?>(.+)</a>', x.strip()) book_list.append(book_name[0].strip()) return book_list
最終得到了頁面上的25本書的名字,如下:

3.3、主過程
在整個過程中使用到的模組為:
import urllib2
import re
主過程為:
if __name__ == "__main__":
seed = "https://www.douban.com/doulist/1264675/?start=0&sort=seq&sub_type="
html = spider(seed)
book_list = parse_page(html)
print len(book_list)
for x in book_list:
print x
4、抓取完整的書單
上面介紹了抓取其中一個頁面的過程,為了能夠抓取到完整的目錄,需要解析所有的網頁的網址,並對每一個網址都進行抓取,其中,網頁的網址在頁面下方的導航中:

在HTML程式碼中的格式為:

因此需要在分析模組中增加分析網址的功能,因此改進後的parse_page函式為:
def parse_page(html, url_map):
# 1、去除無效的字元
html = html.replace("\r", "")
html = html.replace("\n", "")
html = html.replace("\013", "")
# 2、解析出書名
result_name = re.findall('<div class="title">(.*?)</div>',html)
book_list = []
for x in result_name:
# 提取出書名
book_name = re.findall('<a.*?>(.+)</a>', x.strip())
book_list.append(book_name[0].strip())
# 3、解析出還有哪些網址
result_url = re.findall('<div class="paginator">(.*?)</div>', html)
url_list = re.findall("[a-zA-z]+://[^\s\"]*", result_url[0])
for x in url_list:
x = x.strip()
if x not in url_map:
url_map[x] = 0
return book_list, url_map
在解析出書名後,解析出網址。
4.2、控制
在利用函式parse_page函式抓取一個網頁後,分析出網頁中的書單,同時,將網頁中鏈向其他頁面的網址提取出來,這樣,我們需要一個控制模組,能夠對提取出的網址依次抓取,分析,提取。這樣的控制模組的程式碼如下:
def control(seed):
# 設定map用於記錄哪些網址需要爬取
url_map = {}
book_list = []
# 爬取種子網址
html = spider(seed)
url_map[seed] = 1 #種子網址已經爬取過
# 解析種子網址
book_tmp, url_map = parse_page(html, url_map)
for x in book_tmp:
book_list.append(x)
# 對url_map中的的網址依次爬取
while True:
for k, v in url_map.items():
if v == 0:
# 爬取
html = spider(k)
url_map[k] = 1
book_tmp, url_map = parse_page(html, url_map)
for x in book_tmp:
book_list.append(x)
break
else:
continue
if 0 not in url_map.values():
break
return book_list
通過一個map儲存所有頁面的網址,key為網址,value為是否抓取過,0表示未抓取,1表示的是已抓取過。通過迴圈分析該map,直到所有的key對應的頁面都被抓取過為止。
4.3、主函式
主函式為:
if __name__ == "__main__":
seed = "https://www.douban.com/doulist/1264675/?start=0&sort=seq&sub_type="
book_list = control(seed)
print len(book_list)
for x in book_list:
print x
最終抓取到的書單的個數為408個,但是首頁上顯示有409本:
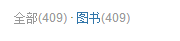
調研發現有一本書沒有:
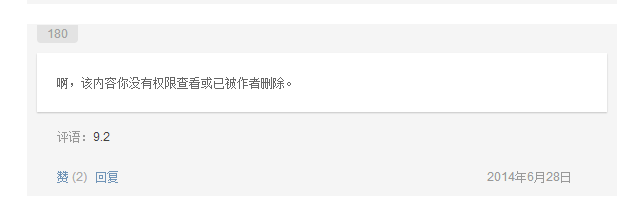
因此,整個抓取沒有問題。
最終的書單的部分如下:

在上面實現了一個簡單的爬蟲,當然,想要抓取更多更復雜的網站,這個爬蟲是不行的,接下來,我們會慢慢深入到爬蟲的更多的技術。