
Image Caption影象描述原理簡介及實現
在原來兩個博文基礎上整理而來
感謝一波這個部落格和lgd1234567
實現程式碼可以直接git這個地址,裡面預訓練網路已經存在了,不需要額外下載模型資料im2txt_demo
Image Caption即影象描述,github上面的很多的專案是img2txt,目的是從圖片中自動生成一段描述性文字,即看圖說話。難點是不僅要能檢測出影象中的物體,而且要理解物體之間的相互關係,最後還要用合理的語言表達出來。需要將影象中檢測到的目標得到相應的向量,再將這些向量對映到文字。
影象識別方面fastrcnn,ssd等模型效果較好,下面圖的專案連結
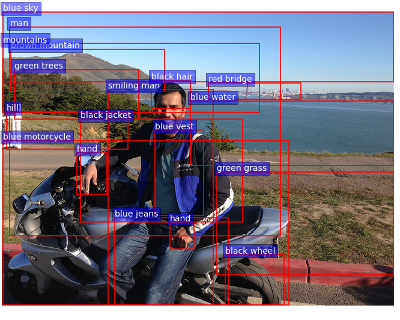
但是這一步僅僅完成了一半,下一步更多的是將這些片語成句子,這是NLP的問題。
接下來針對目前相關的論文進行相關理論的介紹,後面將會針對一個專案具體實現。
自己對NLP不瞭解,下面的一段是摘抄自
Encoder-Decoder結構
在介紹Image Caption相關的技術前,有必要先來複習一下RNN的Encoder-Decoder結構。我們知道,在最原始的RNN結構中,輸入序列和輸出序列必須是嚴格等長的。但在機器翻譯等任務中,源語言句子的長度和目標語言句子的長度往往不同,因此我們需要將原始序列對映為一個不同長度的序列。Encoder-Decoder模型就解決了這樣一個長度不一致的對映問題,它的結構如下圖所示:

是輸入的單詞序列,而為輸出的單詞序列,每個wi和yi都是已經經過獨熱編碼的單詞,因此它們都是1xD的向量,其中D為程式中使用的單詞表的長度。RNN的隱層狀態(hidden state)用 表示。在實際應用中,我們往往不是把獨熱編碼的 輸入RNN,而是將其轉換為對應的word embedding的形式,即圖中的 ,再輸入RNN網路。在Encoder部分,RNN將所有的輸入“編碼”成一個固定的向量表示,即最後一個隱層狀態
Encoder-Decoder結構最初是在論文《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》中提出並應用到機器翻譯系統中的。有興趣的同學可以參考原始論文了解其細節,這裡我們還是回到Image Caption任務中來,看看如何把Encoder-Decoder結構用到Image Caption上。
1. Show and Tell: A Neural Image Caption Generator
在Image Caption輸入的影象代替了之前機器翻譯中的輸入的單詞序列,影象是一系列的畫素值,我們需要從使用影象特徵提取常用的CNN從影象中提取出相應的視覺特徵,然後使用Decoder將該特徵解碼成輸出序列,下圖是論文的網路結構,特徵提取採用的是CNN,Decoder部分,將RNN換成了效能更好的LSTM,輸入還是word embedding,每步的輸出是單詞表中所有單詞的概率。

2.Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
將輸入序列編碼成語義特徵再解碼,但是因為的長度限制,會使得對於長句的翻譯精度降低,論文《Neural machine translation by jointly learning to align and translate》提出了一種Attention機制,不再使用統一的語義特徵,而讓Decoder在輸入序列中自由選取需要的特徵,大大提高了Encoder-Decoder的模型效能。《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》利用Attention機制對原來的Encoder-Decoder機制進行改進。具體的就是利用CNN的空間特性,給圖片的不同位置都提取一個特徵,有了含位置資訊的特徵,Decoder在解碼時擁有在這196個位置特徵中選擇的能力,這就是Attention機制。下圖展示了一些例子,每個句子都是模型自動生成的,在圖片中用白色高亮標註了生成下劃線單詞時模型關注的區域:

3.What Value Do Explicit High Level Concepts Have in Vision to Language Problems?
這篇文章提出了使用高層語義特,這個對於從事影象方向的人來說很好理解,CNN的最終的分類層具有全域性資訊,這對於生成的語句來說是很重要的,所以最後也需要將這些包含進去。該文的作者將高層語義理解為一個多標籤的分類問題。當一個影象中存在多個物體時就變成了一對多的問題。
Decoder的結構和最初的那篇論文中的結構完全一致。如在下圖中,藍色的線就是之前直接使用的卷積特徵 CNN(I) ,而紅色線就是這篇文章提出的 。實驗證明,使用 代替 CNN(I) 可以大幅提高模型效果。

4.Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation
之前的兩篇論文,《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》以及《What Value Do Explicit High Level Concepts Have in Vision to Language Problems?》一個是給RNN加上了Attention結構,一個是改進了CNN提取的特徵,都是比較好理解的。而這篇文章比較fancy,較多地改動了Decoder部分RNN的本身的結構,使得RNN網路不僅能將影象特徵翻譯為文字,還能反過來從文字得到影象特徵,此外還順帶提高了效能,我們一起來看下是怎麼做的。
下圖就是這篇文章中使用的Decoder RNN。 v 表示影象特徵,表示第t階段RNN的隱層狀態,而 是第t階段生成的單詞。 這三個量都是之前的模型中存在的,而作者又再這些量的基礎上加入了和 。其中表示的是“已經生成的文字”的隱變數,作用是記住已經生成單詞中包含的資訊。這個量在每次生成 時都會使用到,作為給模型的提示。此外,作者還要求在每個階段都可以使用 去還原視覺資訊 v ,通過 計算的視覺資訊就是 ,在訓練儘可能要求,換句話說,我們已經生成的文字都要儘可能地去表達視覺資訊,才能做到這樣的還原。

設