
Java資料結構與演算法:堆
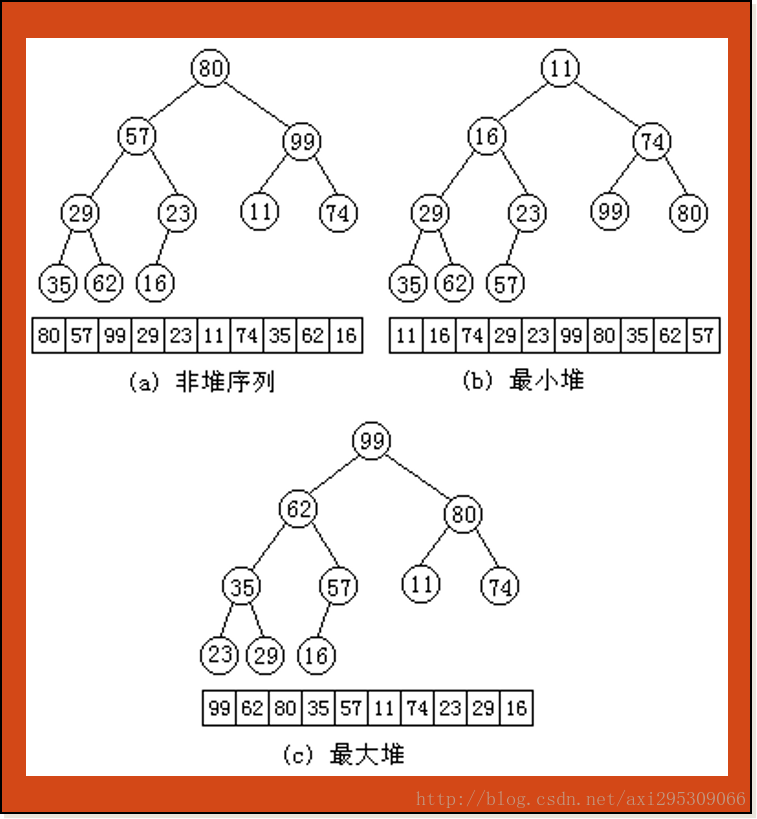
1. 堆的定義
設有n個數據元素的關鍵字為(k0、k1、…、kn-1),如果它們滿足以下的關係:ki<= k2i+1且ki<= k2i+2(或ki>= k2i+1且ki>= k2i+2)(i=0、1、…、(n-2)/2)則稱之為堆(Heap)。
如果將此資料元素序列用一維陣列儲存,並將此陣列對應一棵完全二叉樹,則堆的含義可以理解為:在完全二叉樹中任何非終端結點的關鍵字均不大於(或不小於)其左、右孩子結點的關鍵字。
下圖(b)、(c)分別給出了最小堆和最大堆的例子,前者任一非終端結點的關鍵字均小於或等於它的左、右孩子的關鍵字,此時位於堆頂(即完全二叉樹的根結點位置)的結點的關鍵字是整個序列中最小的,所以稱它為最小堆;後者任一非終端結點的關鍵字均大於或等於它的左、右孩子的關鍵字,此時位於堆頂的結點的關鍵字是整個序列中最大的,所以稱它為最大堆。
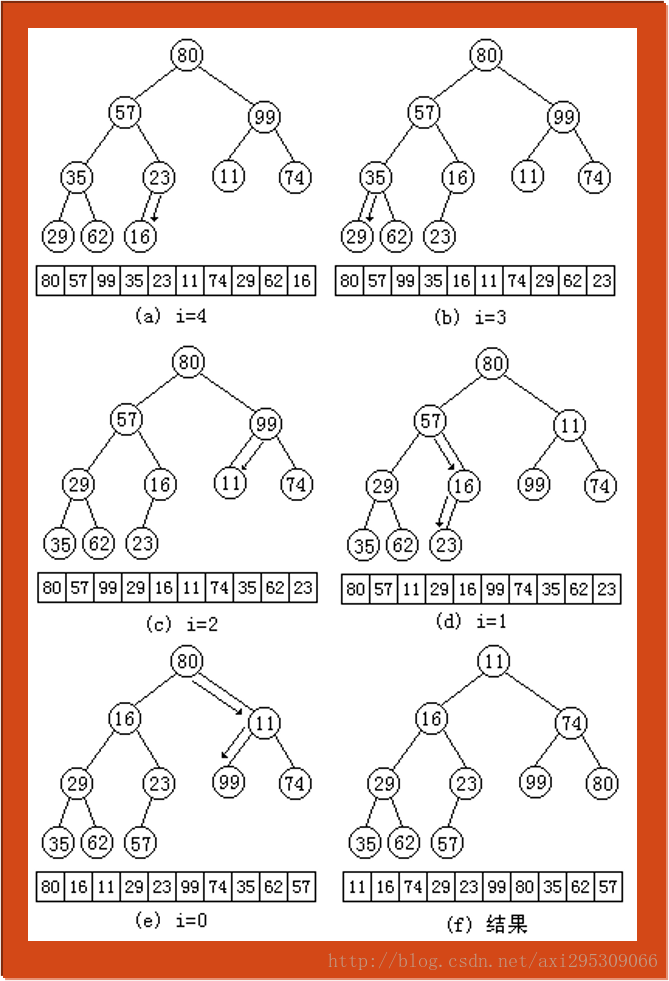
調整演算法FilterDown要求將以分支結點i為根的子樹調整為最小堆,其基本思想是:從結點i開始向下調整,先比較結點i左孩子結點和右孩子結點的關鍵字大小,如果結點i左孩子結點的關鍵字小於右孩子結點的關鍵字,則沿結點i的左分支進行調整;否則沿結點i的右分支進行調整,在演算法中用j指示關鍵字值較小的孩子結點。然後結點i和結點j進行關鍵字比較,若結點i的關鍵字大於結點j的關鍵字,則兩結點對調位置,相當於把關鍵字小的結點上浮。再令i=j,j=2*j十l,繼續向下一層進行比較;若結點i的關鍵字不大於結點j的關鍵字或結點i沒有孩子時調整結束。
注意:這裡的“堆”是指一種的特殊的二叉樹,不要和java和C++等程式語言裡的
“堆”混淆,後者指的是程式設計師用new能得到的計算機記憶體的可用部分。
堆的介紹
- 堆是完全二叉樹
- 常常用陣列實現
- 每一個節點的關鍵字都大於(等於)這個節點的子節點的關鍵字
弱序,優先順序佇列
2. 在堆中插入元素
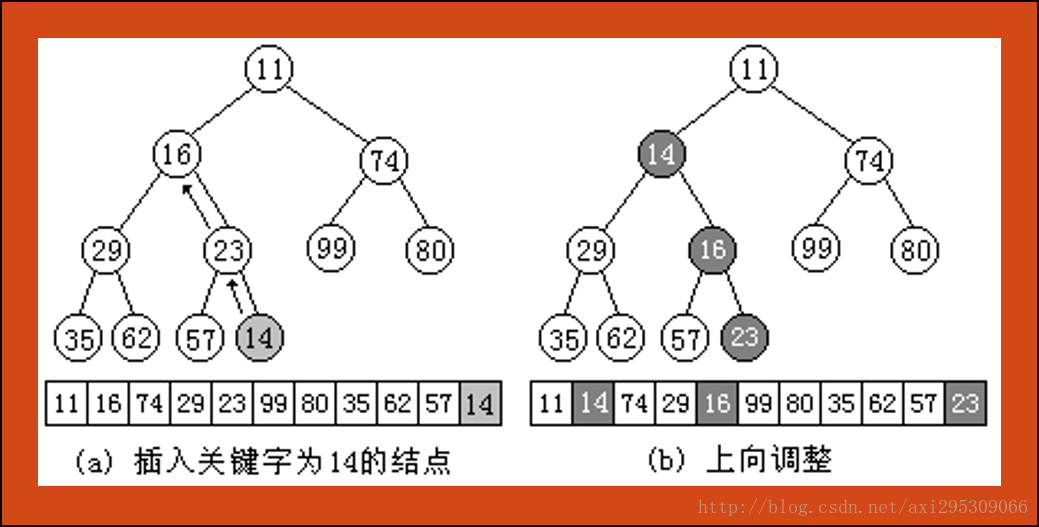
在堆的類定義中成員函式Insert( )用於在堆中插入一個數據元素,在此規定資料元素總是插在已經建成的最小堆後面,如下圖所示在堆中插入關鍵字為14的資料元素。顯然在堆中插入元素後可能破壞堆的性質,所以還需要呼叫FilterUp( )函式,進行自下而上調整使之所在的子樹成為堆。
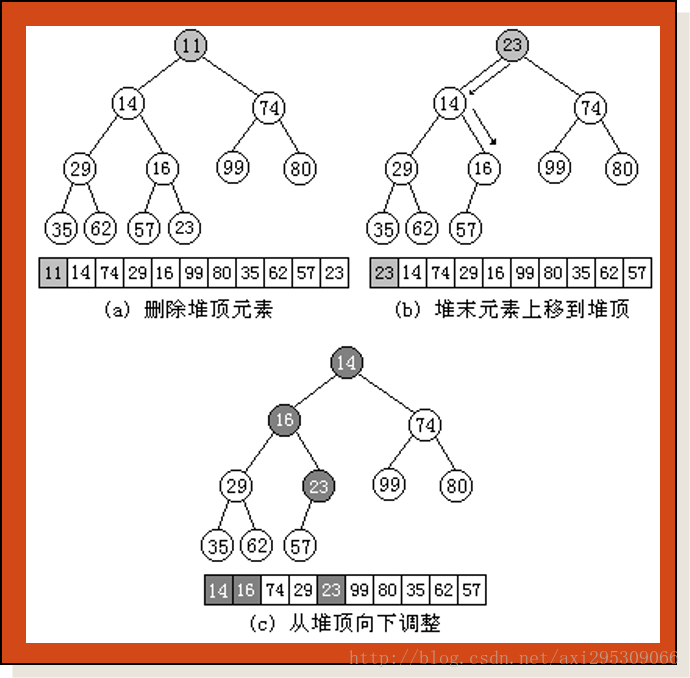
在堆的類定義中成員函式DeleteTop( )用於刪除堆頂資料元素。在從堆中刪除堆頂元素後,一般把堆的最後一個元素移到堆頂,並將堆的當前元素個數heapCurrentSize減1,最後需要呼叫FilterDown()函式從堆頂向下進行調整。如圖6-20所示給出了在堆中刪除堆頂元素的過程。
3. 二叉堆
二叉堆就是通常我們所說的資料結構中”堆”中的一種。和以往一樣,本文會先對二叉堆的理論知識進行簡單介紹,然後給出C語言的實現。後續再分別給出C++和Java版本的實現;實現的語言雖不同,但是原理如出一轍,選擇其中之一進行了解即可
4. 堆和二叉堆的介紹
4.1 堆的定義
堆(heap),這裡所說的堆是資料結構中的堆,而不是記憶體模型中的堆。堆通常是一個可以被看做一棵樹,它滿足下列性質:
- [性質一] 堆中任意節點的值總是不大於(不小於)其子節點的值;
- [性質二] 堆總是一棵完全樹。
將任意節點不大於其子節點的堆叫做最小堆或小根堆,而將任意節點不小於其子節點的堆叫做最大堆或大根堆。常見的堆有二叉堆、左傾堆、斜堆、二項堆、斐波那契堆等等。
4.2 二叉堆的定義
二叉堆是完全二元樹或者是近似完全二元樹,它分為兩種:最大堆和最小堆。
最大堆:父結點的鍵值總是大於或等於任何一個子節點的鍵值;最小堆:父結點的鍵值總是小於或等於任何一個子節點的鍵值。示意圖如下:

二叉堆一般都通過”陣列”來實現。陣列實現的二叉堆,父節點和子節點的位置存在一定的關係。有時候,我們將”二叉堆的第一個元素”放在陣列索引0的位置,有時候放在1的位置。當然,它們的本質一樣(都是二叉堆),只是實現上稍微有一丁點區別。
假設”第一個元素”在陣列中的索引為 0 的話,則父節點和子節點的位置關係如下:
- 索引為i的左孩子的索引是 (2*i+1);
- 索引為i的左孩子的索引是 (2*i+2);
- 索引為i的父結點的索引是 floor((i-1)/2);
假設”第一個元素”在陣列中的索引為 1 的話,則父節點和子節點的位置關係如下:
- 索引為i的左孩子的索引是 (2*i)
- 索引為i的左孩子的索引是 (2*i+1)
- 索引為i的父結點的索引是 floor(i/2)

注意:本文二叉堆的實現統統都是採用”二叉堆第一個元素在陣列索引為0”的方式!
5. 二叉堆的圖文解析
在前面,我們已經瞭解到:”最大堆”和”最小堆”是對稱關係。這也意味著,瞭解其中之一即可。本節的圖文解析是以”最大堆”來進行介紹的。
二叉堆的核心是”新增節點”和”刪除節點”,理解這兩個演算法,二叉堆也就基本掌握了。下面對它們進行介紹。
5.1 新增
假設在最大堆[90,80,70,60,40,30,20,10,50]種新增85,需要執行的步驟如下:

如上圖所示,當向最大堆中新增資料時:先將資料加入到最大堆的最後,然後儘可能把這個元素往上挪,直到挪不動為止!
將85新增到[90,80,70,60,40,30,20,10,50]中後,最大堆變成了[90,85,70,60,80,30,20,10,50,40]。
/*
* 最大堆的向上調整演算法(從start開始向上直到0,調整堆)
*
* 注:陣列實現的堆中,第N個節點的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
*
* 引數說明:
* start -- 被上調節點的起始位置(一般為陣列中最後一個元素的索引)
*/
protected void filterup(int start) {
int c = start; // 當前節點(current)的位置
int p = (c-1)/2; // 父(parent)結點的位置
T tmp = mHeap.get(c); // 當前節點(current)的大小
while(c > 0) {
int cmp = mHeap.get(p).compareTo(tmp);
if(cmp >= 0)
break;
else {
mHeap.set(c, mHeap.get(p));
c = p;
p = (p-1)/2;
}
}
mHeap.set(c, tmp);
}
/*
* 將data插入到二叉堆中
*/
public void insert(T data) {
int size = mHeap.size();
mHeap.add(data); // 將"陣列"插在表尾
filterup(size); // 向上調整堆
}insert(data)的作用:將資料data新增到最大堆中。mHeap是動態陣列ArrayList物件。
當堆已滿的時候,新增失敗;否則data新增到最大堆的末尾。然後通過上調演算法重新調整陣列,使之重新成為最大堆。
5.2 刪除
假設從最大堆[90,85,70,60,80,30,20,10,50,40]中刪除90,需要執行的步驟如下:

如上圖所示,當從最大堆中刪除資料時:先刪除該資料,然後用最大堆中最後一個的元素插入這個空位;接著,把這個“空位”儘量往上挪,直到剩餘的資料變成一個最大堆。
從[90,85,70,60,80,30,20,10,50,40]刪除90之後,最大堆變成了[85,80,70,60,40,30,20,10,50]。
注意:考慮從最大堆[90,85,70,60,80,30,20,10,50,40]中刪除60,執行的步驟不能單純的用它的位元組點來替換;而必須考慮到”替換後的樹仍然要是最大堆”!

/*
* 最大堆的向下調整演算法
*
* 注:陣列實現的堆中,第N個節點的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
*
* 引數說明:
* start -- 被下調節點的起始位置(一般為0,表示從第1個開始)
* end -- 截至範圍(一般為陣列中最後一個元素的索引)
*/
protected void filterdown(int start, int end) {
int c = start; // 當前(current)節點的位置
int l = 2*c + 1; // 左(left)孩子的位置
T tmp = mHeap.get(c); // 當前(current)節點的大小
while(l <= end) {
int cmp = mHeap.get(l).compareTo(mHeap.get(l+1));
// "l"是左孩子,"l+1"是右孩子
if(l < end && cmp<0)
l++; // 左右兩孩子中選擇較大者,即mHeap[l+1]
cmp = tmp.compareTo(mHeap.get(l));
if(cmp >= 0)
break; //調整結束
else {
mHeap.set(c, mHeap.get(l));
c = l;
l = 2*l + 1;
}
}
mHeap.set(c, tmp);
}
/*
* 刪除最大堆中的data
*
* 返回值:
* 0,成功
* -1,失敗
*/
public int remove(T data) {
// 如果"堆"已空,則返回-1
if(mHeap.isEmpty() == true)
return -1;
// 獲取data在陣列中的索引
int index = mHeap.indexOf(data);
if (index==-1)
return -1;
int size = mHeap.size();
mHeap.set(index, mHeap.get(size-1));// 用最後元素填補
mHeap.remove(size - 1); // 刪除最後的元素
if (mHeap.size() > 1)
filterdown(index, mHeap.size()-1); // 從index號位置開始自上向下調整為最小堆
return 0;
}6. 二叉堆的Java實現
6.1 二叉堆(最大堆)
/**
* 二叉堆(最大堆)
*
* @author skywang
* @date 2014/03/07
*/
import java.util.ArrayList;
import java.util.List;
public class MaxHeap<T extends Comparable<T>> {
private List<T> mHeap; // 佇列(實際上是動態陣列ArrayList的例項)
public MaxHeap() {
this.mHeap = new ArrayList<T>();
}
/*
* 最大堆的向下調整演算法
*
* 注:陣列實現的堆中,第N個節點的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
*
* 引數說明:
* start -- 被下調節點的起始位置(一般為0,表示從第1個開始)
* end -- 截至範圍(一般為陣列中最後一個元素的索引)
*/
protected void filterdown(int start, int end) {
int c = start; // 當前(current)節點的位置
int l = 2*c + 1; // 左(left)孩子的位置
T tmp = mHeap.get(c); // 當前(current)節點的大小
while(l <= end) {
int cmp = mHeap.get(l).compareTo(mHeap.get(l+1));
// "l"是左孩子,"l+1"是右孩子
if(l < end && cmp<0)
l++; // 左右兩孩子中選擇較大者,即mHeap[l+1]
cmp = tmp.compareTo(mHeap.get(l));
if(cmp >= 0)
break; //調整結束
else {
mHeap.set(c, mHeap.get(l));
c = l;
l = 2*l + 1;
}
}
mHeap.set(c, tmp);
}
/*
* 刪除最大堆中的data
*
* 返回值:
* 0,成功
* -1,失敗
*/
public int remove(T data) {
// 如果"堆"已空,則返回-1
if(mHeap.isEmpty() == true)
return -1;
// 獲取data在陣列中的索引
int index = mHeap.indexOf(data);
if (index==-1)
return -1;
int size = mHeap.size();
mHeap.set(index, mHeap.get(size-1));// 用最後元素填補
mHeap.remove(size - 1); // 刪除最後的元素
if (mHeap.size() > 1)
filterdown(index, mHeap.size()-1); // 從index號位置開始自上向下調整為最小堆
return 0;
}
/*
* 最大堆的向上調整演算法(從start開始向上直到0,調整堆)
*
* 注:陣列實現的堆中,第N個節點的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
*
* 引數說明:
* start -- 被上調節點的起始位置(一般為陣列中最後一個元素的索引)
*/
protected void filterup(int start) {
int c = start; // 當前節點(current)的位置
int p = (c-1)/2; // 父(parent)結點的位置
T tmp = mHeap.get(c); // 當前節點(current)的大小
while(c > 0) {
int cmp = mHeap.get(p).compareTo(tmp);
if(cmp >= 0)
break;
else {
mHeap.set(c, mHeap.get(p));
c = p;
p = (p-1)/2;
}
}
mHeap.set(c, tmp);
}
/*
* 將data插入到二叉堆中
*/
public void insert(T data) {
int size = mHeap.size();
mHeap.add(data); // 將"陣列"插在表尾
filterup(size); // 向上調整堆
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for (int i=0; i<mHeap.size(); i++)
sb.append(mHeap.get(i) +" ");
return sb.toString();
}
public static void main(String[] args) {
int i;
int a[] = {10, 40, 30, 60, 90, 70, 20, 50, 80};
MaxHeap<Integer> tree=new MaxHeap<Integer>();
System.out.printf("== 依次新增: ");
for(i=0; i<a.length; i++) {
System.out.printf("%d ", a[i]);
tree.insert(a[i]);
}
System.out.printf("\n== 最 大 堆: %s", tree);
i=85;
tree.insert(i);
System.out.printf("\n== 新增元素: %d", i);
System.out.printf("\n== 最 大 堆: %s", tree);
i=90;
tree.remove(i);
System.out.printf("\n== 刪除元素: %d", i);
System.out.printf("\n== 最 大 堆: %s", tree);
System.out.printf("\n");
}
}6.2 二叉堆(最小堆)
/**
* 二叉堆(最小堆)
*
* @author skywang
* @date 2014/03/07
*/
import java.util.ArrayList;
import java.util.List;
public class MinHeap<T extends Comparable<T>> {
private List<T> mHeap; // 存放堆的陣列
public MinHeap() {
this.mHeap = new ArrayList<T>();
}
/*
* 最小堆的向下調整演算法
*
* 注:陣列實現的堆中,第N個節點的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
*
* 引數說明:
* start -- 被下調節點的起始位置(一般為0,表示從第1個開始)
* end -- 截至範圍(一般為陣列中最後一個元素的索引)
*/
protected void filterdown(int start, int end) {
int c = start; // 當前(current)節點的位置
int l = 2*c + 1; // 左(left)孩子的位置
T tmp = mHeap.get(c); // 當前(current)節點的大小
while(l <= end) {
int cmp = mHeap.get(l).compareTo(mHeap.get(l+1));
// "l"是左孩子,"l+1"是右孩子
if(l < end && cmp>0)
l++; // 左右兩孩子中選擇較小者,即mHeap[l+1]
cmp = tmp.compareTo(mHeap.get(l));
if(cmp <= 0)
break; //調整結束
else {
mHeap.set(c, mHeap.get(l));
c = l;
l = 2*l + 1;
}
}
mHeap.set(c, tmp);
}
/*
* 最小堆的刪除
*
* 返回值:
* 成功,返回被刪除的值
* 失敗,返回null
*/
public int remove(T data) {
// 如果"堆"已空,則返回-1
if(mHeap.isEmpty() == true)
return -1;
// 獲取data在陣列中的索引
int index = mHeap.indexOf(data);
if (index==-1)
return -1;
int size = mHeap.size();
mHeap.set(index, mHeap.get(size-1));// 用最後元素填補
mHeap.remove(size - 1); // 刪除最後的元素
if (mHeap.size() > 1)
filterdown(index, mHeap.size()-1); // 從index號位置開始自上向下調整為最小堆
return 0;
}
/*
* 最小堆的向上調整演算法(從start開始向上直到0,調整堆)
*
* 注:陣列實現的堆中,第N個節點的左孩子的索引值是(2N+1),右孩子的索引是(2N+2)。
*
* 引數說明:
* start -- 被上調節點的起始位置(一般為陣列中最後一個元素的索引)
*/
protected void filterup(int start) {
int c = start; // 當前節點(current)的位置
int p = (c-1)/2; // 父(parent)結點的位置
T tmp = mHeap.get(c); // 當前節點(current)的大小
while(c > 0) {
int cmp = mHeap.get(p).compareTo(tmp);
if(cmp <= 0)
break;
else {
mHeap.set(c, mHeap.get(p));
c = p;
p = (p-1)/2;
}
}
mHeap.set(c, tmp);
}
/*
* 將data插入到二叉堆中
*/
public void insert(T data) {
int size = mHeap.size();
mHeap.add(data); // 將"陣列"插在表尾
filterup(size); // 向上調整堆
}
public String toString() {
StringBuilder sb = new StringBuilder();
for (int i=0; i<mHeap.size(); i++)
sb.append(mHeap.get(i) +" ");
return sb.toString();
}
public static void main(String[] args) {
int i;
int a[] = {80, 40, 30, 60, 90, 70, 10, 50, 20};
MinHeap<Integer> tree=new MinHeap<Integer>();
System.out.printf("== 依次新增: ");
for(i=0; i<a.length; i++) {
System.out.printf("%d ", a[i]);
tree.insert(a[i]);
}
System.out.printf("\n== 最 小 堆: %s", tree);
i=15;
tree.insert(i);
System.out.printf("\n== 新增元素: %d", i);
System.out.printf("\n== 最 小 堆: %s", tree);
i=10;
tree.remove(i);
System.out.printf("\n== 刪除元素: %d", i);
System.out.printf("\n== 最 小 堆: %s", tree);
System.out.printf("\n");
}
}6.3 二叉堆的Java測試程式
測試程式已經包含在相應的實現檔案中了,這裡只說明執行結果。
最大堆(MaxHeap.java)的執行結果:
== 依次新增: 10 40 30 60 90 70 20 50 80
== 最 大 堆: 90 80 70 60 40 30 20 10 50
== 新增元素: 85
== 最 大 堆: 90 85 70 60 80 30 20 10 50 40
== 刪除元素: 90
== 最 大 堆: 85 80 70 60 40 30 20 10 50 最小堆(MinHeap.java)的執行結果:
== 最 小 堆: 10 20 30 50 90 70 40 80 60
== 新增元素: 15
== 最 小 堆: 10 15 30 50 20 70 40 80 60 90
== 刪除元素: 10
== 最 小 堆: 15 20 30 50 90 70 40 80 60 PS. 二叉堆是”堆排序”的理論基石。以後講解演算法時會講解到”堆排序”,理解了”二叉堆”之後,”堆排序”就很簡單了