
ElasticSearch搜尋時match和term大小寫問題
阿新 • • 發佈:2019-02-06
ES的建立索引過程:分詞->語法處理(還原時態等等)->排序->建立索引。
其他暫不討論,本文只討論大小寫問題。
如果建立index時mapping沒有指定某個filed的標準化配置normalizer,那麼如果寫入ES的是大寫,搜尋出來看到的結果也是大寫,但是建立的索引卻是小寫(可以用分詞驗證),以至於搜尋的時候使用term會失敗。
比如我的mapping為(內部使用,非完整mapping,重要是看欄位):
"mappings": { "rack_crm_community_type": { "dynamic": "false", "_all": { "enabled": false }, "properties": { "claimBdPin": { "type": "string" }, "createBdPin": { "type": "string" }, "city": { "type": "integer" }, "communityStatusCode": { "type": "integer" }, "communityName": { "analyzer": "ik_max_word", "type": "string" }, "location": { "type": "geo_point" }, "communityId": { "type": "long" }, "communityPersonNum": { "type": "integer" }, "claimTime": { "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis", "type": "date" } } } }
以"claimBdPin"欄位為例,只是指定了String型別。儲存結果為:
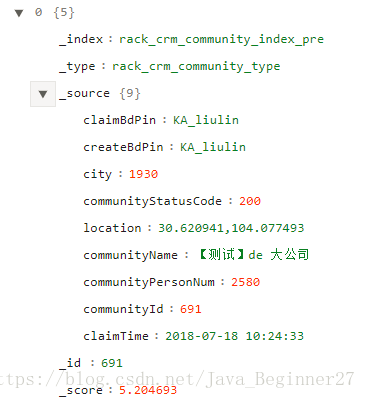
當搜尋條件為:
{
"query":{
"bool":{
"filter":[
{"term": {"claimBdPin":"KA_liulin"}}
]
}
}
}
結果為空。
當搜尋條件為:
{
"query":{
"bool":{
"must":[
{"match": {"claimBdPin":"KA_liulin"}}
]
}
}
}
結果為:

能查詢到,為什麼呢?測試分詞(ik_max_word)發現:KA_liulin分詞為ka_liulin、ka、liulin三個分詞。雖然儲存的是KA_liulin,但是因為建立索引的時候會自動進行處理為ka_liulin(因為mapping未做分詞),再建立索引。match查詢的時候,會自動對引數進行處理,所以match搜尋的時候使用KA_liulin(實際搜尋為ka_liulin)能查詢到,而term則查詢不到。
因為mapping時未設定分詞,所以一般使用term(過濾)來查詢,所以要麼在程式碼裡面使用String.toLowerCase,但是太麻煩,那麼要怎麼一次性解決問題呢?我們可以mapping的時候設定normalizer(normalizer用於解析前的標準化配置,比如把所有的字元轉化為小寫等)
PUT index
{
"settings": {
"analysis": {
"normalizer": {
"my_normalizer": {
"type": "custom",
"char_filter": [],
"filter": ["lowercase", "asciifolding"]
}
}
}
},
"mappings": {
"type": {
"properties": {
"foo": {
"type": "keyword",
"normalizer": "my_normalizer"
}
}
}
}
}