
神經網路的Trick之Dropout的理解與實現
網上都說dropout是讓某些神經元以一定的概率不工作,但是具體程式碼怎麼實現?原理又是什麼,還是有點迷糊,所以就大體掃描了文獻:《Improving neural networks by preventing co-adaptation of feature detectors》、《Improving Neural Networks with Dropout》、《Dropout:
A Simple Way to Prevent Neural Networks from Overtting》,不過感覺看完以後,還是收穫不是很大。下面是我的學習筆記,因為看的不是很細,也沒有深入理解,有些地方可能有錯,如有錯誤還請指出。
二、演算法概述
我們知道如果要訓練一個大型的網路,訓練資料很少的話,那麼很容易引起過擬合(也就是在測試集上的精度很低),可能我們會想到用L2正則化、或者減小網路規模。然而深度學習領域大神Hinton,在2012年文獻:《Improving neural networks by preventing co-adaptation of feature detectors》提出了,在每次訓練的時候,讓一半的特徵檢測器停過工作,這樣可以提高網路的泛化能力,Hinton又把它稱之為dropout。
Hinton認為過擬合,可以通過阻止某些特徵的協同作用來緩解。在每次訓練的時候,每個神經元有百分之50的機率被移除,這樣可以讓一個神經元的出現不應該依賴於另外一個神經元。
另外,我們可以把dropout理解為 模型平均。假設我們要實現一個圖片分類任務,我們設計出了100000個網路,這100000個網路,我們可以設計得各不相同,然後我們對這100000個網路進行訓練,訓練完後我們採用平均的方法,進行預測,這樣肯定可以提高網路的泛化能力,或者說可以防止過擬合,因為這100000個網路,它們各不相同,可以提高網路的穩定性。而所謂的dropout我們可以這麼理解,這n個網路,它們權值共享,並且具有相同的網路層數(這樣可以大大減小計算量)。我們每次dropout後,網路模型都可以看成是整個網路的子網路。(需要注意的是如果採用dropout,訓練時間大大延長,但是對測試階段沒影響)。
囉嗦了這麼多,那麼到底是怎麼實現的?Dropout說的簡單一點就是我們讓在前向傳導的時候,讓某個神經元的啟用值以一定的概率p,讓其停止工作,示意圖如下:
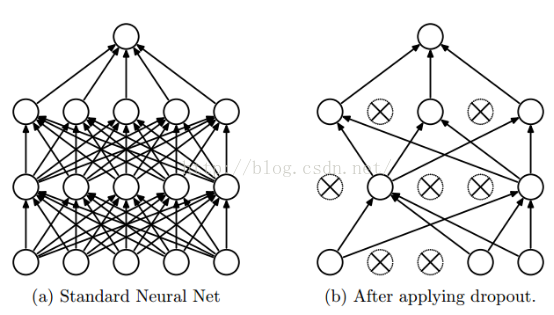
左邊是原來的神經網路,右邊是採用Dropout後的網路。這個說是這麼說,但是具體程式碼層面是怎麼實現的?怎麼讓某個神經元以一定的概率停止工作?這個我想很多人還不是很瞭解,程式碼層面的實現方法,下面就講解一下其程式碼層面的實現。以前我們網路的計算公式是:
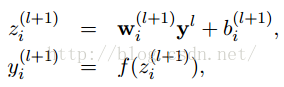
採用dropout後計算公式就變成了:
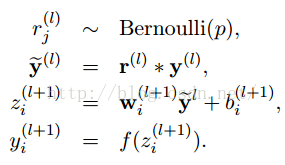
上面公式中Bernoulli函式,是為了以概率p,隨機生成一個0、1的向量。
演算法實現概述:
1、其實Dropout很容易實現,原始碼只需要幾句話就可以搞定了,讓某個神經元以概率p,停止工作,其實就是讓它的啟用值以概率p變為0。比如我們某一層網路神經元的個數為1000個,其啟用值為x1,x2……x1000,我們dropout比率選擇0.4,那麼這一層神經元經過drop後,x1……x1000神經元其中會有大約400個的值被置為0。
2、經過上面遮蔽掉某些神經元,使其啟用值為0以後,我們還需要對向量x1……x1000進行rescale,也就是乘以1/(1-p)。如果你在訓練的時候,經過置0後,沒有對x1……x1000進行rescale,那麼你在測試的時候,就需要對權重進行rescale:
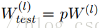
問題來了,上面為什麼經過dropout需要進行rescale?查找了相關的文獻,都沒找到比較合理的解釋,後面再結合原始碼說一下我對這個的見解。
所以在測試階段:如果你既不想在訓練的時候,對x進行放大,也不願意在測試的時候,對權重進行縮小(乘以概率p)。那麼你可以測試n次,這n次都採用了dropout,然後對預測結果取平均值,這樣當n趨近於無窮大的時候,就是我們需要的結果了(也就是說你可以採用train階段一模一樣的程式碼,包含了dropout在裡面,然後前向傳導很多次,比如1000000次,然後對著1000000個結果取平均值)。
三、原始碼實現
下面我引用keras的dropout實現原始碼進行講解,keras開源專案github地址為:
- #dropout函式的實現
- def dropout(x, level):
- if level < 0.or level >= 1:#level是概率值,必須在0~1之間
- raise Exception('Dropout level must be in interval [0, 1[.')
- retain_prob = 1. - level
- #我們通過binomial函式,生成與x一樣的維數向量。binomial函式就像拋硬幣一樣,我們可以把每個神經元當做拋硬幣一樣
- #硬幣 正面的概率為p,n表示每個神經元試驗的次數
- #因為我們每個神經元只需要拋一次就可以了所以n=1,size引數是我們有多少個硬幣。
- sample=np.random.binomial(n=1,p=retain_prob,size=x.shape)#即將生成一個0、1分佈的向量,0表示這個神經元被遮蔽,不工作了,也就是dropout了
- print sample
- x *=sample#0、1與x相乘,我們就可以遮蔽某些神經元,讓它們的值變為0
- print x
- x /= retain_prob
- return x
- #對dropout的測試,大家可以跑一下上面的函式,瞭解一個輸入x向量,經過dropout的結果
- x=np.asarray([1,2,3,4,5,6,7,8,9,10],dtype=np.float32)
- dropout(x,0.4)</span>
函式中,x是本層網路的啟用值。Level就是dropout就是每個神經元要被丟棄的概率。不過對於dropout後,為什麼需要進行rescale:
- x /= retain_prob
有的人解釋有點像歸一化一樣,就是保證網路的每一層在訓練階段和測試階段資料分佈相同。我查找了很多文獻,都沒找到比較合理的解釋,除了在文獻《Regularization of Neural Networks using DropConnect》稍微解釋了一下,其它好像都沒看到相關的理論解釋。
我們前面說過,其實Dropout是類似於平均網路模型。我們可以這麼理解,我們在訓練階段訓練了1000個網路,每個網路生成的概率為Pi,然後我們在測試階段的時候,我們肯定要把這1000個網路的輸出結果都計算一遍,然後用這1000個輸出,乘以各自網路的概率Pi,求得的期望值就是我們最後的平均結果。我們假設,網路模型的輸出如下:
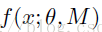
M是Dropout中所有的mask集合。所以當我們在測試階段的時候,我們就是對M中所有的元素網路,最後所得到的輸出,做一個期望:
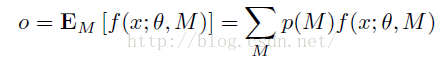
P(M)表示網路各個子網路出現的概率。因為dropout過程中,所有的子網路出現的概率都是相同的,所以。
個人總結:個人感覺除非是大型網路,才採用dropout,不然我感覺自己在一些小型網路上,訓練好像很是不爽。之前搞一個比較小的網路,搞人臉特徵點定位的時候,因為訓練資料不夠,怕過擬合,於是就採用dropout,最後感覺好像訓練速度好慢,從此就對dropout有了偏見,感覺訓練過程一直在波動,很是不爽。
參考文獻:
1、《Improving neural networks by preventing co-adaptation of feature detectors》
2、《Improving Neural Networks with Dropout》
3、《Dropout: A Simple Way to Prevent Neural Networks from Overtting》
4、《ImageNet Classification with Deep Convolutional》