
機器學習教程之13-決策樹(decision tree)的sklearn實現
阿新 • • 發佈:2019-02-07
0.概述
決策樹(decision tree)是一種基本的分類與迴歸方法。
主要優點:模型具有可讀性,分類速度快。
決策樹學習通常包括3個步驟:特徵選擇、決策樹的生成和決策樹的修剪。
1.決策樹模型與學習
節點:根節點、子節點;內部節點(internal node)和葉節點(leaf node)。
決策樹學習本質上是從訓練資料集中歸納出一組分類規則。
決策樹學習仍然需要將代價函式最小化。
為了防止有過擬合現象,需要對決策圖進行修剪。
決策圖的生成對應於模型的區域性選擇,決策樹的剪枝則考慮全域性最小選擇。
2.特徵選擇
特徵選擇在於選取對訓練資料具有分類能力的特徵。可以用一個例子說明:預測波斯頓的房價,把蓋房子所用磚頭的顏色作為特徵,顯示是沒有意義的!
特徵選擇的準則是資訊增益或資訊增益比。
特徵有多個,選擇哪個決策圖更科學呢?答案是:
如果一個特徵具有更好的分類能力,或者說,按照這一特徵將訓練資料集分割成子集,使得各個子集在當前條件下有最好的分類,那麼就更應該選擇這個特徵。資訊增益(information gain)就能夠很好地表示這一直觀的準則。
決策樹學習應用資訊增益準則選擇特徵。資訊增益大的特徵具有更強的分類能力。
特徵選擇的方法:對訓練資料集(或子集)D,計算其每個特徵的資訊增益,並比較它們的大小,選擇資訊增益最大的特徵。
資訊增益演算法:

例子:

3.決策圖的生成
決策樹學習的經典演算法:ID3、C4.5中的生成演算法。
通過例項理解ID3演算法:
4.決策樹的剪枝
決策樹的減枝是為了解決過擬合現象,決策樹的剪枝往往通過極小化決策樹整體的代價函式來實現。
5.程式碼
"""
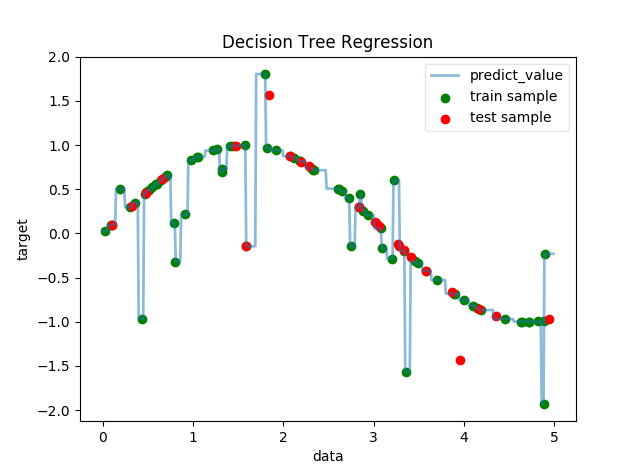
功能:迴歸決策樹
說明:人為設定函式模型為每隔5個點引入噪音的離散的sin(x),我們利用決策樹迴歸擬合這些資料
作者:唐天澤
部落格:http://blog.csdn.net/u010837794/article/details/76596063
日期:2017-08-03
"""
"""
匯入專案所需的包
"""
import numpy as np
from sklearn.tree import DecisionTreeRegressor
# 使用交叉驗證的方法,把資料集分為訓練集合測試集 
6.參考資料
[1] 李航 《統計學習方法》
[2] 華校專《Python大戰機器學習》