
京東手機評論的爬取
阿新 • • 發佈:2019-02-07
開篇
做論文的時候,最多接觸的就是標準的資料集,幾乎不需要太多的結構化處理,下載下來就是可以直接載入使用的資料,課題是有關評論分析的,但是論文針對的都是英文資料,而國內電商平臺其實積累了大量的評論資料,沒有辦法通過官方渠道獲取,那麼我們就寫個爬蟲自己爬吧,我沒有系統地學過爬蟲,所以挑了一個比較好爬的網站。
獲取評論儲存的地址
首先我們選擇一個想要爬取的商品,開啟它的網址,這邊我選擇的是iphone8的手機評論
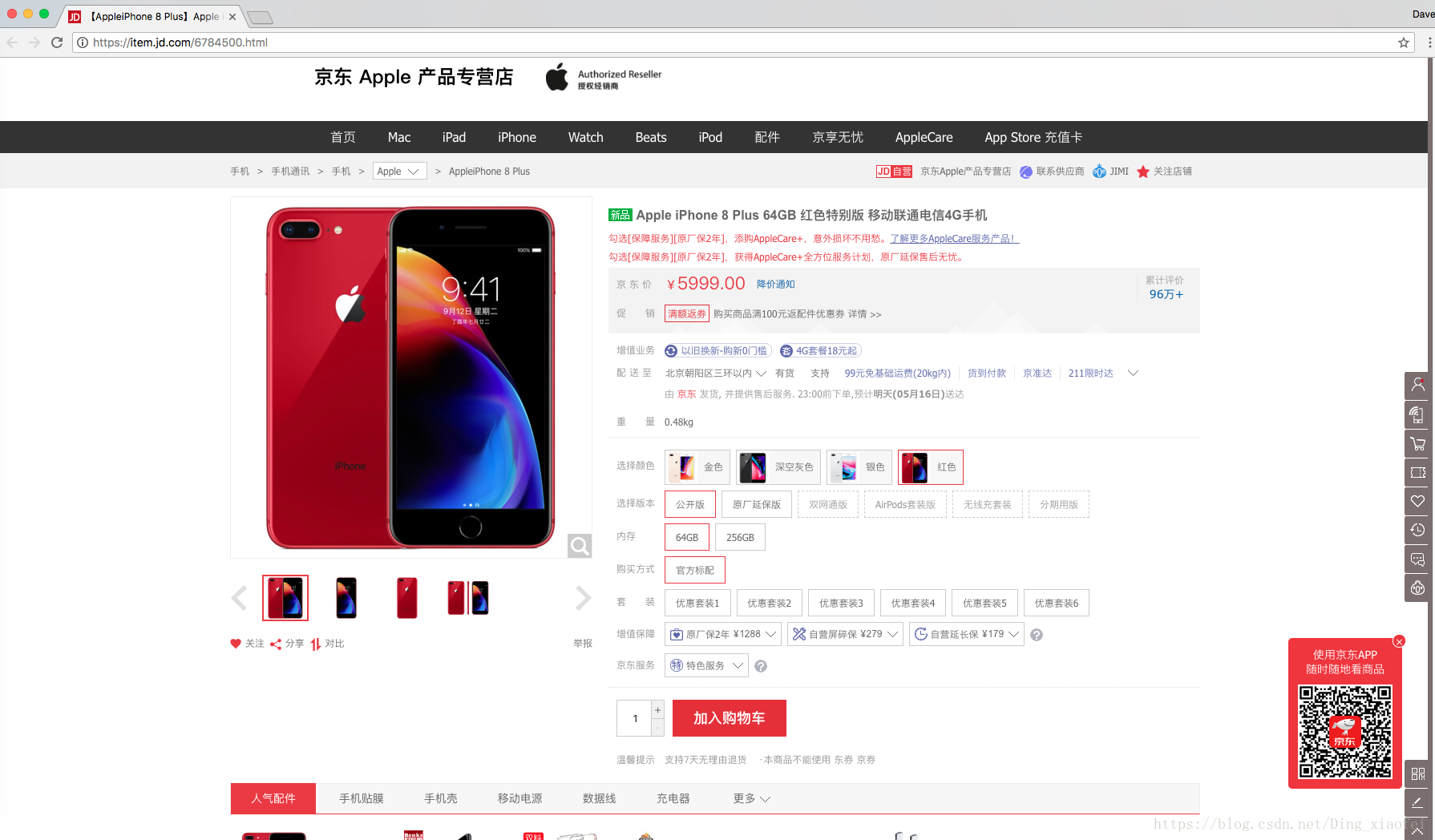
這裡最好使用谷歌瀏覽器,接下來就是需要我們去獲取評論的儲存網頁啦,我們右擊網頁,點選檢查,這時候會出現京東網頁的程式碼。
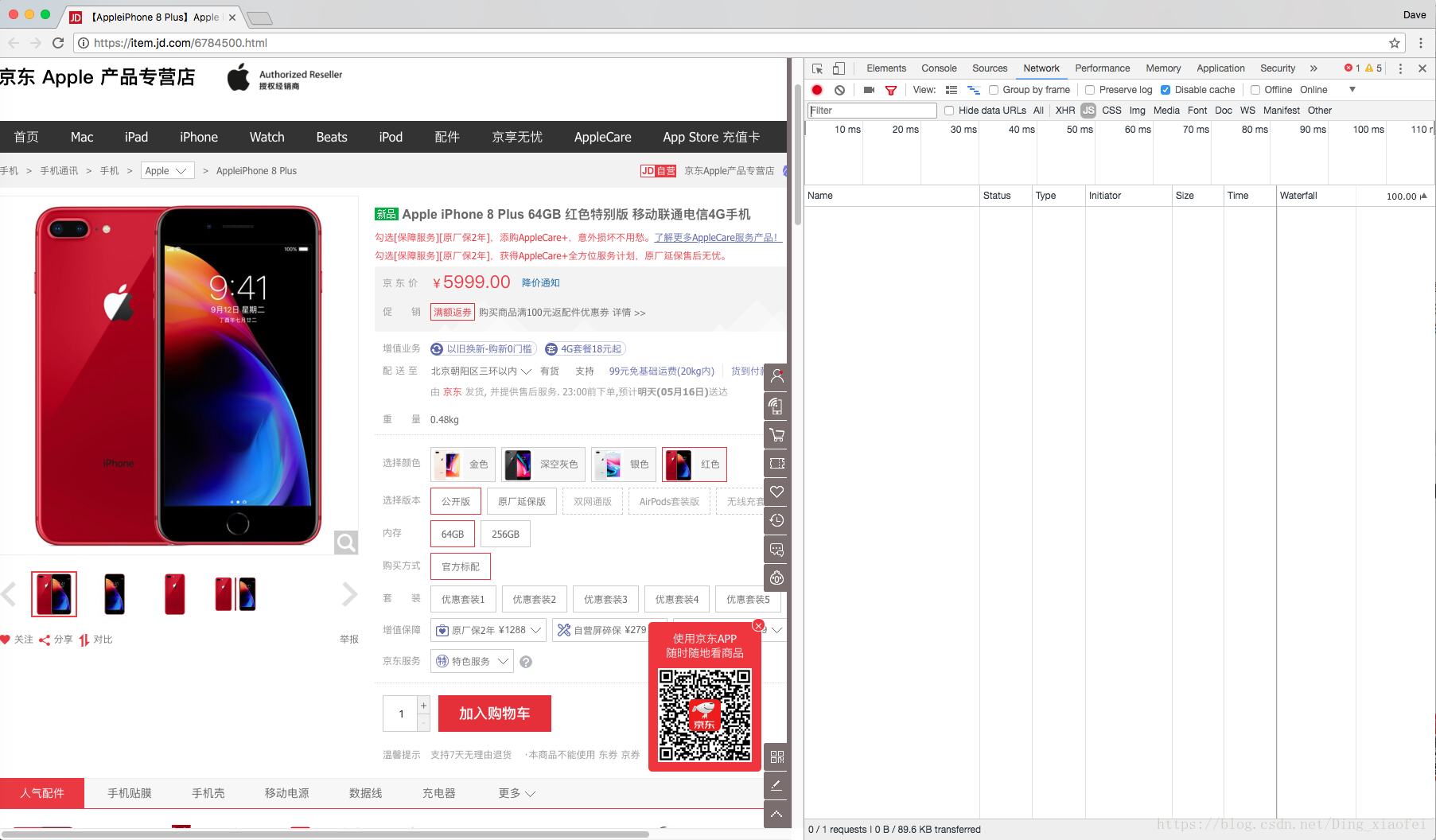
點選network,將disable cache選上,我們主要要查詢js網頁,所以點上js,這時候你查詢什麼網頁都沒有,所以重新整理一下網頁
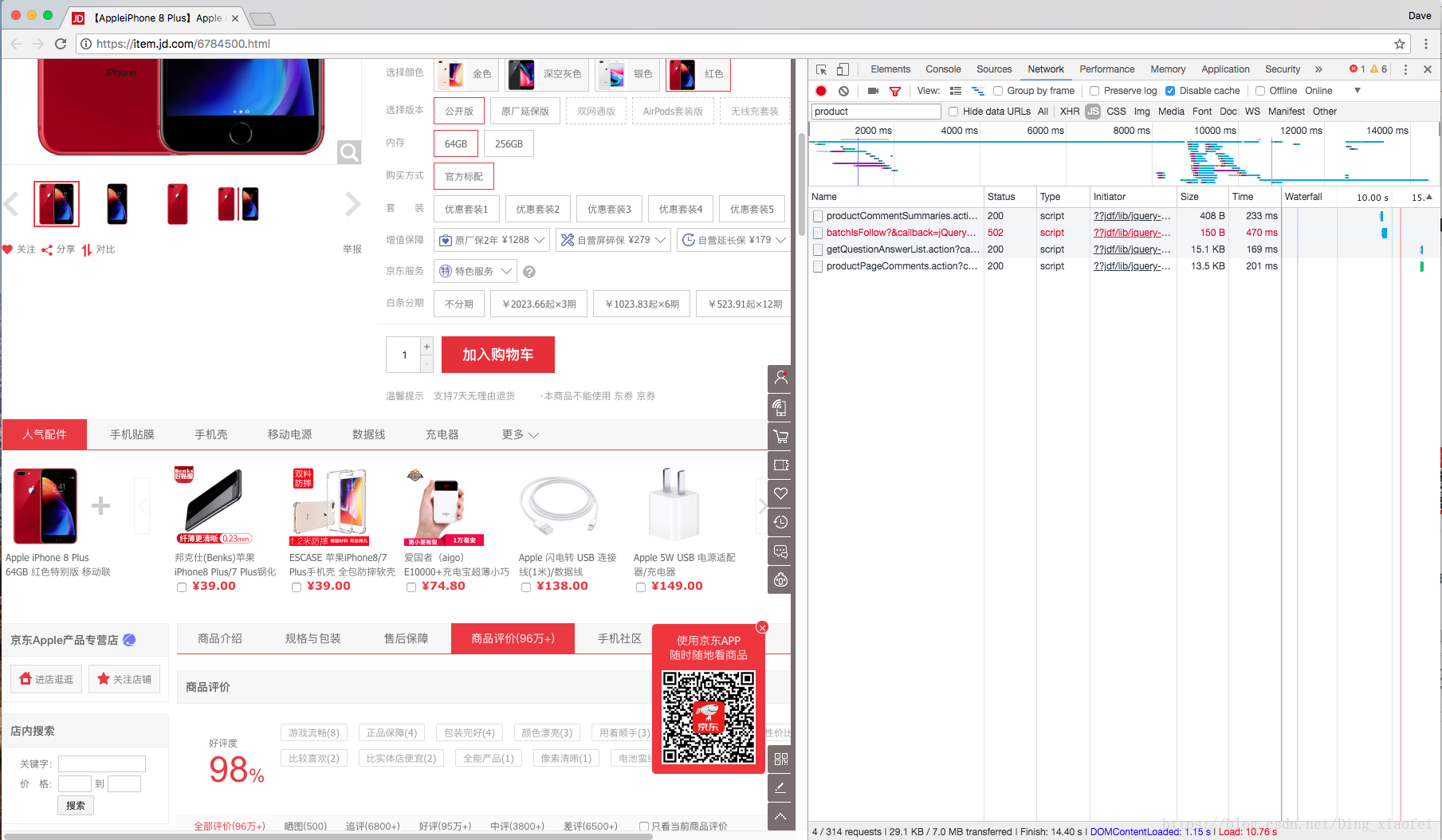
這時候巢狀的網頁就全出來了,這時候你輸入product
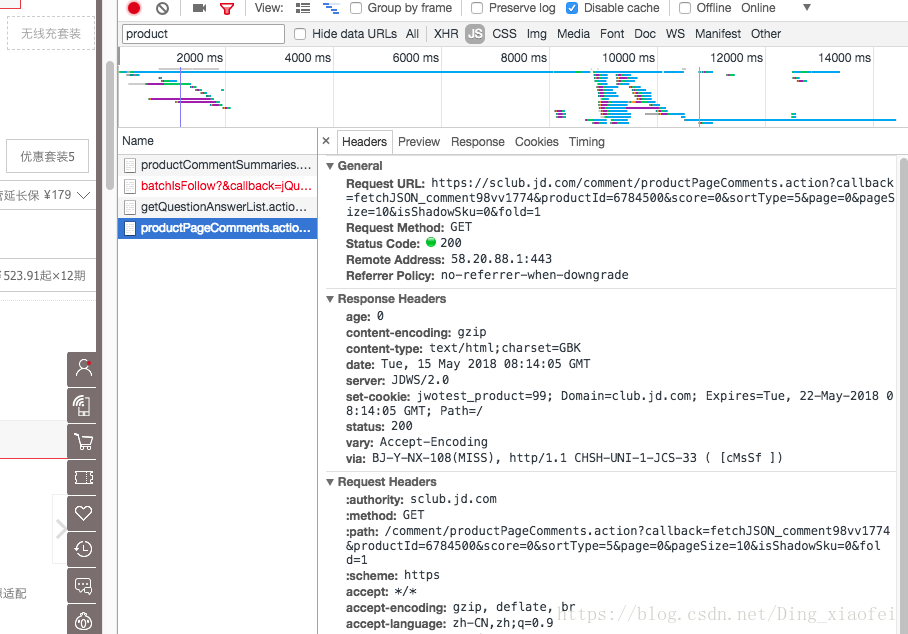
這下就找到我們要爬取的網頁了。複製它的request url的地址放到位址列裡面開啟。

網頁開啟後就是這樣的,這就是我們需要爬取的內容,裡面囊括了我們需要的評論資訊,是以json的格式儲存的。有了地址我們就可以用python把它們一個個抓下來。下面是程式碼
# -*- coding: utf-8 -*-
import urllib.request
import json
import time
import random
def crawlProductComment(url):
#讀取原始資料(注意選擇gbk編碼方式)