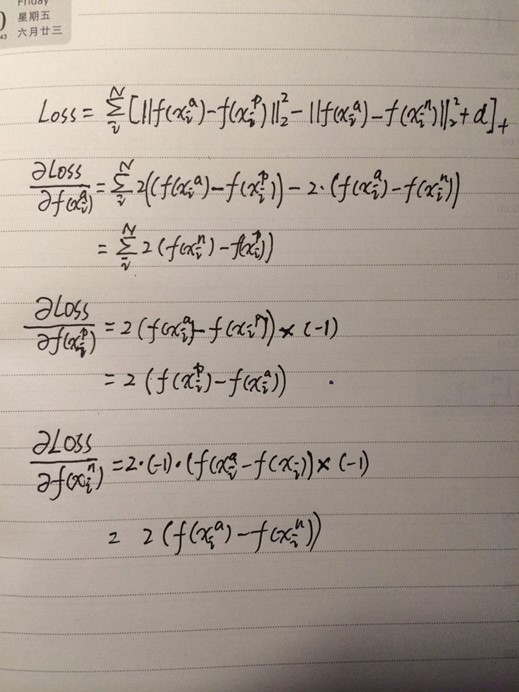Triplet Loss及其梯度
-
Triplet Loss簡介
我這裡將Triplet Loss翻譯為三元組損失,其中的三元也就是如下圖的Anchor、Negative、Positive,如下圖所示通過Triplet Loss的學習後使得Positive元和Anchor元之間的距離最小,而和Negative之間距離最大。其中Anchor為訓練資料集中隨機選取的一個樣本,Positive為和Anchor屬於同一類的樣本,而Negative則為和Anchor不同類的樣本。
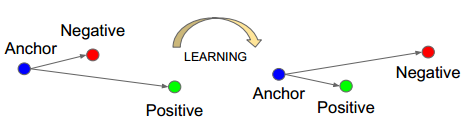
這也就是說通過學習後,使得同類樣本的positive樣本更靠近Anchor,而不同類的樣本Negative則遠離Anchor。
-
Triplet loss目標函式
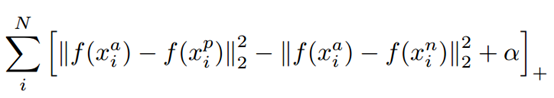
上式中的||*||為歐式距離,所以:
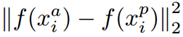
表示的是Positive元和Anchor之間的歐式距離度量。
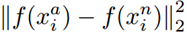
表示的是Negative和Anchor之間的歐式距離度量。
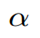
a是指x_a與x_n之間的距離和x_a與x_p之間的距離之間有一個最小的間隔。
另外這裡距離用歐式距離度量,+表示[]內的值大於零的時候,取該值為損失,小於零的時候,損失為零。
由目標函式可以看出:
當x_a與x_n之間的距離
< x_a與x_p之間的距離加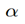
當x_a與x_n之間的距離
>= x_a與x_p之間的距離加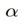
-
Triplet loss理解
我們的目的就是使 loss 在訓練迭代中下降的越小越好,也就是要使得 Anchor 與 Positive 越接近越好,Anchor 與 Negative 越遠越好。基於上面這些,分析一下 margin 值的取值。
當 margin 值越小時,loss 也就較容易的趨近於 0,於是 Anchor 與 Positive 都不需要拉的太近,Anchor 與 Negative 不需要拉的太遠,就能使得 loss 很快的趨近於 0。這樣訓練得到的結果,不能夠很好的區分相似的影象。
當 Anchor 越大時,就需要使得網路引數要拼命地拉近 Anchor、Positive 之間的距離,拉遠 Anchor、Negative 之間的距離。如果 margin 值設定的太大,很可能最後 loss 保持一個較大的值,難以趨近於 0 。
因此,設定一個合理的 margin 值很關鍵,這是衡量相似度的重要指標。簡而言之,margin 值設定的越小,loss 很容易趨近於 0 ,但很難區分相似的影象。margin 值設定的越大,loss 值較難趨近於 0,甚至導致網路不收斂,但可以較有把握的區分較為相似的影象。
-
Triplet loss梯度求解