
線性SVM與SoftMax分類器
1. 線性分類器
在深度學習與計算機視覺系列(2)我們提到了影象識別的問題,同時提出了一種簡單的解決方法——KNN。然後我們也看到了KNN在解決這個問題的時候,雖然實現起來非常簡單,但是有很大的弊端:
- 分類器必須記住全部的訓練資料(因為要遍歷找近鄰啊!!),而在任何實際的影象訓練集上,資料量很可能非常大,那麼一次性載入記憶體,不管是速度還是對硬體的要求,都是一個極大的挑戰。
- 分類的時候要遍歷所有的訓練圖片,這是一個相當相當相當耗時的過程。
這個部分我們介紹一類新的分類器方法,而對其的改進和啟發也能幫助我們自然而然地過渡到深度學習中的卷積神經網。有兩個重要的概念:
- 得分函式/score function:將原始資料對映到每個類的打分的函式
- 損失函式/loss function:用於量化模型預測結果和實際結果之間吻合度的函式
在我們得到損失函式之後,我們就將問題轉化成為一個最優化的問題,目標是得到讓我們的損失函式取值最小的一組引數。
2. 得分函式/score function
首先我們定義一個有原始的圖片畫素值對映到最後類目得分的函式,也就是這裡提到的得分函式。先籠統解釋一下,一會兒我們給個具體的例項來說明。假設我們的訓練資料為
比如CIFAR-10資料集中N=50000,而D=32x32x3=3072畫素,K=10,因為這時候我們有10個不同的類別(狗/貓/車…),我們實際上要定義一個將原始畫素對映到得分上函式
2.1 線性分類器
我們先丟出一個簡單的線性對映:
在這個公式裡,我們假定圖片的畫素都平展為[D x 1]的向量。然後我們有兩個引數:W是[K x D]的矩陣,而向量b為[K x 1]的。在CIFAR-10中,每張圖片平展開得到一個[3072 x 1]的向量,那W就應該是一個[10 x 3072]的矩陣,b為[10 x 1]的向量。
這樣,以我們的線性代數知識,我們知道這個函式,接受3072個數作為輸入,同時輸出10個數作為類目得分。我們把W叫做權重,b叫做偏移向量。
說明幾個點:
- 我們知道一次矩陣運算,我們就可以藉助W把原始資料對映為10個類別的得分。
- 其實我們的輸入
(xi,yi) 其實是固定的,我們現在要做的事情是,我們要調整W, b使得我們的得分結果和實際的類目結果最為吻合。 - 我們可以想象到,這樣一種分類解決方案的優勢是,一旦我們找到合適的引數,那麼我們最後的模型可以簡化到只有保留W, b即可,而所有原始的訓練資料我們都可以不管了。
- 識別階段,我們需要做的事情僅僅是一次矩陣乘法和一次加法,這個計算量相對之前…不要小太多好麼…
提前劇透一下,其實卷積神經網做的事情也是類似的,將原始輸入的畫素對映成類目得分,只不過它的中間對映更加複雜,引數更多而已…
2.2 理解線性分類器
我們想想,其實線性分類器在做的事情,是對每個畫素點的三個顏色通道,做計算。咱們擬人化一下,幫助我們理解,可以認為設定的引數/權重不同會影響分類器的『性格』,從而使得分類器對特定位置的顏色會有自己的喜好。
舉個例子,假如說我們的分類器要識別『船隻』,那麼它可能會喜歡圖片的四周都是藍色(通常船隻是在水裡海里吧…)。
我們用一個實際的例子來表示這個得分對映的過程,大概就是下圖這個樣子:

原始畫素點向量
2.2.1 劃分的第1種理解
圖片被平展開之後,向量維度很高,高維空間比較難想象。我們簡化一下,假如把圖片畫素輸入,看做可以壓縮到二維空間之中的點,那我們想想,分類器實際上在做的事情就如下圖所示:
![]()
W中的每一列對應類別中的每一類,而當我們改變W中的值的時候,圖上的線的方向會跟著改變,那麼b呢?對,b是一個偏移量,它表示當我們的直線方向確定以後,我們可以適當平移直線到合適的位置。沒有b會怎麼樣呢,如果直線沒有偏移量,那意味著所有的直線都要通過原點,這種強限制條件下顯然不能保證很好的平面類別分割。
2.2.2 劃分的第2種理解
對W第二種理解方式是,W的每一行可以看做是其中一個類別的模板。而我們輸入圖片相對這個類別的得分,實際上是畫素點和模板匹配度(通過內積運算獲得),而類目識別實際上就是在匹配影象和所有類別的模板,找到匹配度最高的那個。
是不是感覺和KNN有點類似的意思?是有那麼點相近,但是這裡我們不再比對所有圖片,而是比對類別的模板,這樣比對次數只和類目數K有關係,所以自然計算量要小很多,同時比對的時候用的不再是l1或者l2距離,而是內積計算。
我們提前透露一下CIFAR-10上學習到的模板的樣子:

你看,和我們設想的很接近,ship類別的周邊有大量的藍色,而car的旁邊是土地的顏色。
2.2.3 關於偏移量的處理
我們先回到如下的公式:
公式中有W和b兩個引數,我們知道調節兩個引數總歸比調節一個引數要麻煩,所以我們用一點小技巧,來把他們組合在一起,放到一個引數中。
我們現在要做的運算是矩陣乘法再加偏移量,最常用的合併方法就是,想辦法把b合併成W的一部分。我們仔細看看下面這張圖片:
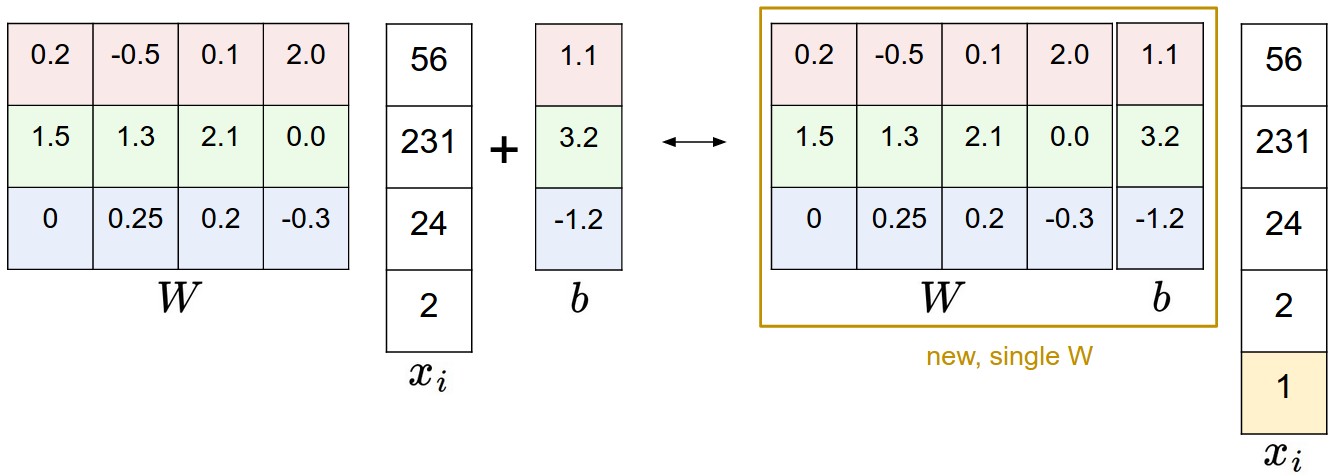
我們給輸入的畫素矩陣加上一個1,從而把b拼接到W裡變成一個變數。依舊拿CIFAR-10舉例,原本是[3072 x 1]的畫素向量,我們添上最後那個1變成[3073 x 1]的向量,而[W]變成[W b]。
2.2.4 關於資料的預處理
插播一段,實際應用中,我們很多時候並不是把原始的畫素矩陣作為輸入,而是會預先做一些處理,比如說,有一個很重要的處理叫做『去均值』,他做的事情是對於訓練集,我們求得所有圖片畫素矩陣的均值,作為中心,然後輸入的圖片先減掉這個均值,再做後續的操作。有時候我們甚至要對圖片的幅度歸一化/scaling。去均值是一個非常重要的步驟,原因我們在後續的梯度下降裡會提到。
2.3 損失函式
我們已經通過引數W,完成了由畫素對映到類目得分的過程。同時,我們知道我們的訓練資料
我們回到最上面的圖片中預測 [貓/狗/船] 得分的例子裡,這個圖片中給定的W顯然不是一個合理的值,預測的結果和實際情況有很大的偏差。於是我們現在要想辦法,去把這個偏差表示出來,擬人一點說,就是我們希望我們的模型在訓練的過程中,能夠對輸出的結果計算並知道自己做的好壞。
而能幫助我們完成這件事情的工具叫做『損失函式/loss function』,其實它還有很多其他的名字,比如說,你說不定在其他的地方聽人把它叫做『代價函式/cost function』或者『客觀度/objective』,直觀一點說,就是我們輸出的結果和實際情況偏差很大的時候,損失/代價就會很大。
2.3.1 多類別支援向量機損失/Multiclass Support Vector Machine loss
膩害的大神們定義出了好些損失函式,我們這裡首先要介紹一種極其常用的,叫做多類別支援向量機損失(Multiclass SVM loss)。如果要用一句精簡的話來描述它,就是它(SVM)希望正確的類別結果獲得的得分比不正確的類別,至少要高上一個固定的大小
我們先解釋一下這句話,一會兒再舉個例子說明一下。對於訓練集中的第i張圖片資料
1. 線性分類器
在深度學習與計算機視覺系列(2)我們提到了影象識別的問題,同時提出了一種簡單的解決方法——KNN。然後我們也看到了KNN在解決這個問題的時候,雖然實現起來非常簡單,但是有很大的弊端:
分類器必須記住全部的訓練資料(因為要遍歷找近鄰啊!!),而在任何實際的影象訓練集上, 首先說明啊:logistic分類器是以Bernoulli(伯努利) 分佈為模型建模的,它可以用來分兩種類別;而softmax分類器以多項式分佈(Multinomial Distribution)為模型建模的,它可以分多種互斥的類別。
補充:
什麼是伯努利分佈?伯努利分佈[2] 是一種離散分佈,有兩種可能的結
準備知識
資料庫
我們基於幾個基本資料庫來驗證演算法:MNIST 手寫字型資料集,CIFAR10 與 CIFAR100 影象分類資料集。
使用 keras 的 datasets 模組來方便地匯入資料庫:
from keras.datasets im cnblogs 判斷 選擇 實現 數值計算 思想 max函數 公式 wiki
wiki百科:softmax函數的本質就是將一個K維的任意實數向量壓縮(映射)成另一個K維的實數向量,其中向量中的每個元素取值都介於(0,1)之間。
一、疑問
二、知識點
1. softmax
3.7Softmax迴歸
(1)Softmax迴歸的功能:
答案:分類
(2)舉例:
答案 :系統中輸入一張圖片P,通過Softmax層,系統會
Sigmoid
先來了解一個函式——sigmoid:
它所對應的影象為
sigmoid函式中,z作為我們的自變數,它的範圍可以在(-∞,+∞),但是當z對映到sigmoid當中的,它的範圍則為(0,1),這個範圍是不是容易讓你聯想到概率?當我們的概率大於0
前言:
在最優化計算方法中,我已經講到了機器學習常用的一些引數優化的方法,如梯度法,共軛梯度法,牛頓法,擬牛頓法,在《最優化計算方法》板塊,我都用迴歸分析比較了這些引數優化的方法,從現在開始,我將把這些引數優化的方法用來訓練分類器。
在本節中,我講介紹sof
softmax函式在機器學習中是常用的多分類器,特別是在卷積神經網路中,最後的一層經常都是使用softmax分類器進行多類別分類任務。雖然softmax看上去相對比較簡單,但是其實其中蘊含的數學推導還是比較複雜的,特別是對於數學不太好的同學。這篇文章主要就是結合自
在使用一些比較基礎的分類器時,需要人為調整的引數是比較少的,比如說K-Neighbor的K和SVM的C,通常而言直接使用sklearn裡的預設值就能取得比較好的效果了。
但是,當使用一些大規模整合的演算法時,引數的問題就出來了,比如說 XGBoost的引數大概
這一節我將跳過KNN分類器,因為KNN分類器分類時間效率太低,這一節講Sparse autoencoder + softmax分類器。首先普及一下Sparse autoencoder網路,Sparse autoencoder可以看成一個3層神經網路,但是輸入的數目和 1. 深度學習有哪些應用
影象:影象識別、物體識別、圖片美化、圖片修復、目標檢測。
自然語言處理:機器創作、個性化推薦、文字分類、翻譯、自動糾錯、情感分析。
數值預測、量化交易
2. 什麼是神經網路
我們以房價預測的案例來說明一下,把房屋的面積作為神經網路的輸入(我們稱之為
線性分類器
假設樣本xi∈RD,i=1…N,對應類標籤yi∈1…K。現定義一個線性對映f(xi,W,b)=Wxi+b,W是K∗D的矩陣,b是K維的向量。W和b分別稱作權重(或引數)和偏。
W的每一行都是一個分類器,每個分類器對應於一個得分。
通過學
1、對於複雜的含有多Wi引數的函式L求導問題,首先是分別對單個引數求偏導數,然後放置到此引數對應的矩陣的位置。在求偏導數的矩陣表示時,一般要經歷如下兩個步驟:數字計算:分解步驟,同時計算L和導數:一般情況下,L的計算分很多步,而且每一步也十分複雜,可能涉及到數值判定等。但是隻
本文主要內容為 CS231n 課程的學習筆記,主要參考 學習視訊 和對應的 課程筆記翻譯 ,感謝各位前輩對於深度學習的辛苦付出。在這裡我主要記錄下自己覺得重要的內容以及一些相關的想法,希望能與大家多多交流~
1. 線性分類器簡介
這部分所
CS231n簡介
課程筆記
這篇是線性分類器的第二部分,回憶線性分類器的線性體現在score的獲得,即score = Wx+b,然後predict_label = argmax(score)。具體細節以及關於線性分類器的解釋請參考CS231n課程筆記 content cli 樣本 image ges 五個 是你 角度 spa SVM入門(六)線性分類器的求解——問題的轉化,直觀角度
讓我再一次比較完整的重復一下我們要解決的問題:我們有屬於兩個類別的樣本點(並不限定這些點在二維空間中)若幹,如圖,
圓形的樣本點定為正樣
對於高維空間的兩類問題,最直接的方法是找到一個最佳的分類超平面,使得並且,對於所有的正負訓練樣本和. 因此,以上問題可以表達為:
問題P0可以轉化為
兩邊除以\epsilon,並且做變數替換,最終得到下面的線性規化(linear programming
本課件主要內容包括:
上次課程回顧:基於迴歸的分類方法
Hinge損失
Logistic損失
Logistic迴歸與SVMs
“黑盒”分類器比較
最大餘量分類器
支援向量機
魯棒性與凸近似
非凸0-
本課件主要內容包括:
上次課程回顧:L1正則化
組合特徵選擇
線性模型與最小二乘
梯度下降與誤差函式
正則化
辨識重要郵件
基於迴歸的二元分類?
一維判決邊界
二維判決邊界
感知器演算法
1.SVM建立線性分類器SVM用來構建分類器和迴歸器的監督學習模型,SVM通過對數學方程組的求解,可以找出兩組資料之間的最佳分割邊界。2.準備工作我們首先對資料進行視覺化,使用的檔案來自學習書籍配套管網。首先增加以下程式碼:import numpy as np
import 相關推薦
線性SVM與SoftMax分類器
Logistic 分類器與 softmax分類器
CNN 簡史與 Keras 增量實現(一)—— Softmax 分類器
3、Softmax分類器
3.8 Softmax迴歸 3.9 訓練一個softmax分類器
分類問題——Logistic分類器/softmax分類器
deep learning Softmax分類器(L-BFGS,CG,SD)
softmax分類器推導
機器學習教程 之 引數搜尋:GridSearchCV 與 RandomizedSearchCV || 以阿里IJCAI廣告推薦資料集與XGBoostClassifier分類器為例
deep learning 自學習網路的Softmax分類器
啟用函式、正向傳播、反向傳播及softmax分類器,一篇就夠了!
cs231學習筆記二 線性分類器、SVM、Softmax
關於cs231n中作業1的SVM和Softmax線性分類器實現的感悟
影象的線性分類器(感知機、SVM、Softmax)
CS231n課程筆記3.1:線性分類器(SVM,softmax)的誤差函式、正則化
【轉】SVM入門(六)線性分類器的求解——問題的轉化,直觀角度
分類器設計之線性分類器和線性SVM(含Matlab程式碼)
【Mark Schmidt課件】機器學習與資料探勘——進一步討論線性分類器
【Mark Schmidt課件】機器學習與資料探勘——線性分類器
Python構建SVM分類器(線性)