
讀書筆記:機器學習實戰(2)——章3的決策樹程式碼和個人理解與註釋
首先是對於決策樹的個人理解:
通過尋找最大資訊增益(或最小資訊熵)的分類特徵,從部分已知類別的資料中提取分類規則的一種分類方法。
資訊熵:
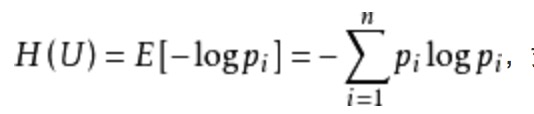
其中,log底數為2,額,好吧,圖片我從百度截的。。
這裡只解釋到它是一種資訊的期望值,深入的請看維基百科
資訊增益:劃分資料集前後的資訊發生的變化(原書定義)
實際應用想要找到具有最大資訊增益的分類樹結構,就是使原始資料的資訊熵減去分類後的資訊熵的差值最大,原始資料的資訊熵可以理解為常數,那麼想要最大資訊增益,也就是要尋找一種分類方法,是按照分類方法分類後的資料集的資訊熵最小。(另:也可以選擇“不純度”或“錯誤率”作為評估引數,不純度,維基百科下,錯誤率就是字面意思)
所以找到最優分類樹結構程式碼如下:
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #the last column is used for the labels
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures): #iterate over all the features
featList = [example[i] for 按照“尋找最大資訊增益的方式”,找到對於已知類別的一批資料(訓練集)的最優決策樹,然後用這個樹結構去分類未知資料(測試集),整體程式碼如下:
#!/usr/bin/env python
# coding=utf-8
'''
Created on Oct 12, 2010
Decision Tree Source Code for Machine Learning in Action Ch. 3
@author: Peter Harrington
'''
from math import log
import operator
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
#change to discrete values
return dataSet, labels
def calcShannonEnt(dataSet):
# 計算香儂熵
numEntries = len(dataSet)
labelCounts = {}
# 儲存特徵的字典
for featVec in dataSet: #the the number of unique elements and their occurance
currentLabel = featVec[-1]
# 取最後一個元素,即該組特徵的label
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
# 如果沒有,增加新key,value初始化為0
labelCounts[currentLabel] += 1
# 對應key的值累計
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2) #log base 2
# shannon公式:shanonEnt =(負的)求和(i.prob*log(i.prob,2))
return shannonEnt
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] #chop out axis used for splitting
reducedFeatVec.extend(featVec[axis+1:])
# 簡單的分片,除去分類特徵,餘下的新增到容器中
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #the last column is used for the labels
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures): #iterate over all the features
featList = [example[i] for example in dataSet]#create a list of all the examples of this feature
uniqueVals = set(featList) #get a set of unique values
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy #calculate the info gain; ie reduction in entropy
if (infoGain > bestInfoGain): #compare this to the best gain so far
bestInfoGain = infoGain #if better than current best, set to best
bestFeature = i
return bestFeature #returns an integer
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]#stop splitting when all of the classes are equal
if len(dataSet[0]) == 1: #stop splitting when there are no more features in dataSet
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:] #copy all of labels, so trees don't mess up existing labels
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree
def classify(inputTree,featLabels,testVec):
firstStr = inputTree.keys()[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
key = testVec[featIndex]
valueOfFeat = secondDict[key]
if isinstance(valueOfFeat, dict):
classLabel = classify(valueOfFeat, featLabels, testVec)
else: classLabel = valueOfFeat
return classLabel
def storeTree(inputTree,filename):
import pickle
fw = open(filename,'w')
pickle.dump(inputTree,fw)
fw.close()
def grabTree(filename):
import pickle
fr = open(filename)
return pickle.load(fr)
if __name__ == '__main__':
(dataSet, labels) = createDataSet();
print dataSet;print labels
shannonEnt = calcShannonEnt(dataSet)
print shannonEnt
myTree = createTree(dataSet,labels )
print 'mytree:'
print myTree
(dataSet, labels) = createDataSet();
print classify(myTree,labels, [1,1])
import treePlotter
# treePlotter.createPlot(myTree)
fr = open('lenses.txt')
lenses = [inst.strip().split('\t') for inst in fr.readlines()]
lensesLabels = ['age','prescript','astigmatic','tearRate']
lensesTree = createTree(lenses,lensesLabels)
print lensesTree
treePlotter.createPlot(lensesTree)
部分地方加入了中文註釋,原著的那幾行英文註釋很好就沒有再換成中文的。
之前沒有詳細看過決策樹,以為它就是把分類邏輯變為樹結構,多個if else,說說個人學習後,對於決策樹的理解:
1.還是覺得它就是多個if else,樹結構也可以這麼理解吧
2.構建的過程或者說收斂條件是:最大資訊增益(最小資訊熵)
3.優點:可讀性強,邏輯簡單易懂,計算步驟不超過樹的深度;缺點:極易過擬合,得到的樹結構泛性不強
4.正因為過度追求最優解,導致決策樹往往會過擬合,原著是通過構建以後的合併細小或相近分支,也就是“後置裁剪”,但是這樣時間上有浪費,代表的是K-Fold Cross Validation,不斷裁剪,評估當前的錯誤率,有點類似於整體求解後,再反過來找恰當的“early stop”;另一種就是著名的隨機森林,系統複雜了,效果確實會好,額,隨機森林具體的以後深度學習下補上。
下面是原著利用matplolib畫圖的程式碼:
'''
Created on Oct 14, 2010
@author: Peter Harrington
'''
import matplotlib.pyplot as plt
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
def getNumLeafs(myTree):
numLeafs = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args )
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) #this determines the x width of this tree
depth = getTreeDepth(myTree)
firstStr = myTree.keys()[0] #the text label for this node should be this
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
plotTree(secondDict[key],cntrPt,str(key)) #recursion
else: #it's a leaf node print the leaf node
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
#if you do get a dictonary you know it's a tree, and the first element will be another dict
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #no ticks
#createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;
plotTree(inTree, (0.5,1.0), '')
plt.show()
#def createPlot():
# fig = plt.figure(1, facecolor='white')
# fig.clf()
# createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
# plotNode('a decision node', (0.5, 0.1), (0.1, 0.5), decisionNode)
# plotNode('a leaf node', (0.8, 0.1), (0.3, 0.8), leafNode)
# plt.show()
def retrieveTree(i):
listOfTrees =[{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}},
{'no surfacing': {0: 'no', 1: {'flippers': {0: {'head': {0: 'no', 1: 'yes'}}, 1: 'no'}}}}
]
return listOfTrees[i]
#createPlot(thisTree)