
NodeJS 各websocket框架效能分析
For a current project at WhoScored, I needed to learn JavaScript, Node.js and WebSocket channel, after seven years of writing web applications with Java and Spring framework. We wanted an application that can send data to thousands of concurrent users, and Node.js appeared to be the right way of doing it
Firstly, to learn JavaScript I started doing the tutorials in Code Academy and reading D. Crockford’s JavaScript: The Good Parts book. In parallel, I read J. R. Wilson’s Node.js the Right Way as well. It was a great read: by using some great modules like async, Q, ZMQ, Express, and methods like Promises and Generators, the book explains how to build scalable Node applications. It also covers sockets with Pub/Sub, Req/Res and Push/Pull patterns which shaped the WebSocket applications that I wrote.
System structure
After some trials, errors, and brainstorming sessions, the final structure looks like this:
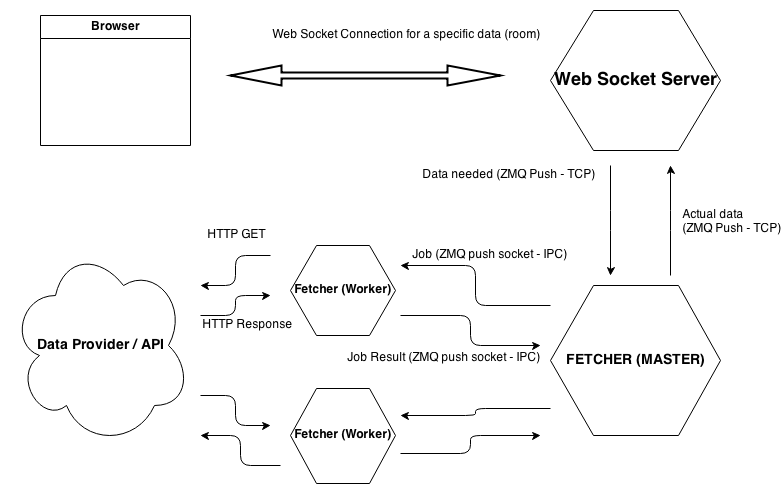
A client connects for a specific key/resource, let’s say “matchesfeed/8/matchcentre”. WebSocket server’s responsibility is to return some JSON data for this key. If it doesn’t have data for this key in its memory, it requests it from “Fetcher” via a Push socket implemented with
einaros / ws (v 0.4)
Based on Heroku’s WebSocket demo, I began with einaros/ws implementation. It didn’t have as much as documentation that other frameworks had, but the development went smooth and I had something working in a short time.
 Client beautifully connects via WebSockets
Client beautifully connects via WebSockets
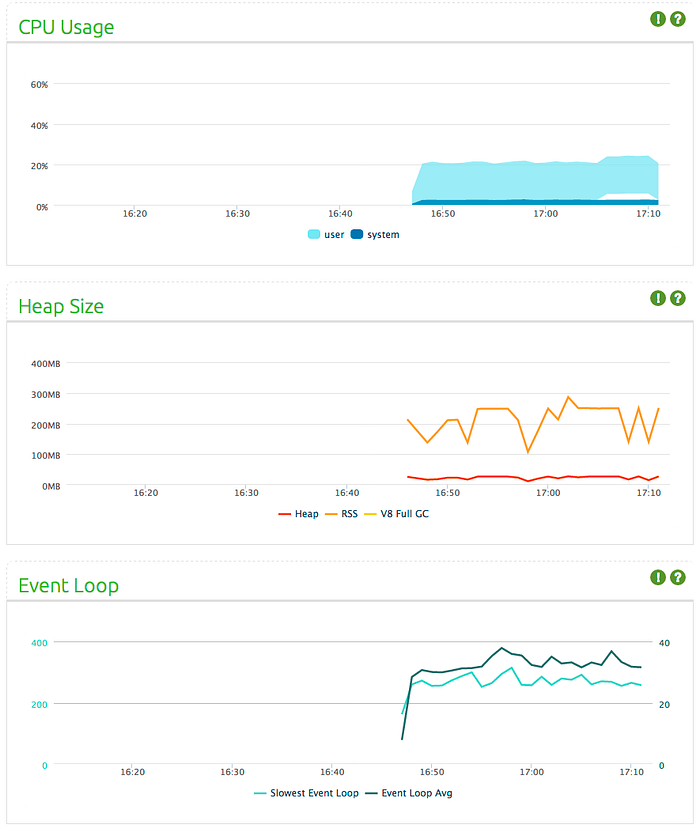
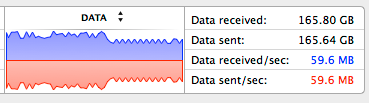
Then I wrote a load test to see the performance. The test basically connects clients every half a second, all requesting the same data. Data is 165KB, and is sent every second. With 120 concurrent clients, the application allocates around 210MB of RAM, and data sent appears to be around 35 MB/second. The test machine is a 3.4 Ghz Intel i7 (8 processors) with 16GB of RAM, running OSX v10.9.

I monitored the process with Strongloop’s agent, I find it pretty impressive.
At this point, the biggest drawback for me was it being a pure WebSocket implementation: if the client browser did not support WebSockets, it would not work. This made me try Socket.IO.
Socket.IO (v. 0.9)
Socket.IO seemed like the perfect solution, as it selects the most capable transport at runtime: it tries to connect to server via WebSockets first, if it doesn’t work, it downgrades by trying XHR-polling, if it doesn’t work, continues with flash sockets etc. Moreover, it would try to reconnect sockets if connection fails, and it supports rooms so that I could cluster connections based on what information they asked for, without any custom implementation. So I re-implemented the application by keeping everything the same but web socket framework.
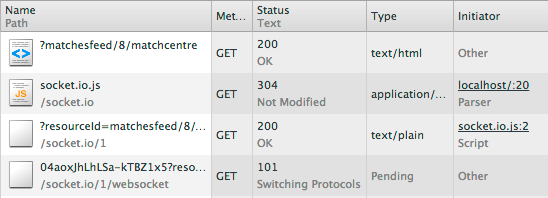 Client connects to Socket.IO server
Client connects to Socket.IO server
Indeed, when the server is down, Socket.IO tries to connect back with decreasing frequency.
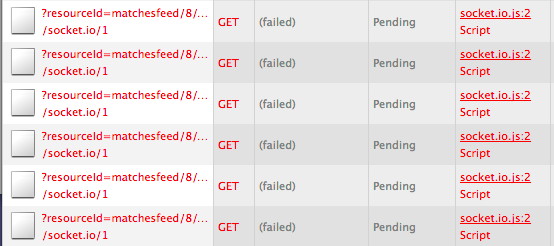
And when the server is up, WebSocket connection is re-established:

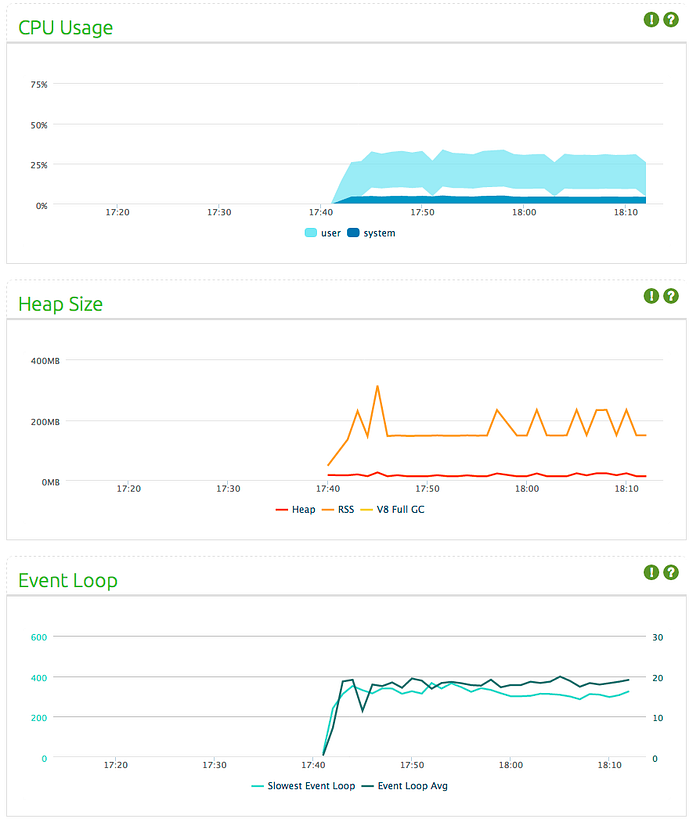
Load test results are below, it is the same test I executed for ws/einaros implementation with the same data:
The data output looks like:
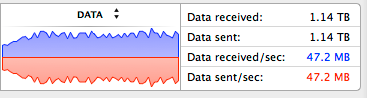 In WS, average load was 35 MBs
In WS, average load was 35 MBs
Performance limit
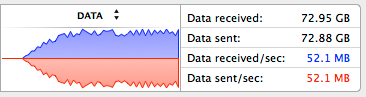
However, when I connect 140 clients, the memory usage starts to increment without the number of clients or the data size changing. Garbage Collector kicks in very frequently and gets more aggressive over time (sometimes a couple of times per second), eating up CPU time and desperately trying to free memory. Memory usage would reach ~1GB, then heartbeats would fail and clients would start to lose connection.

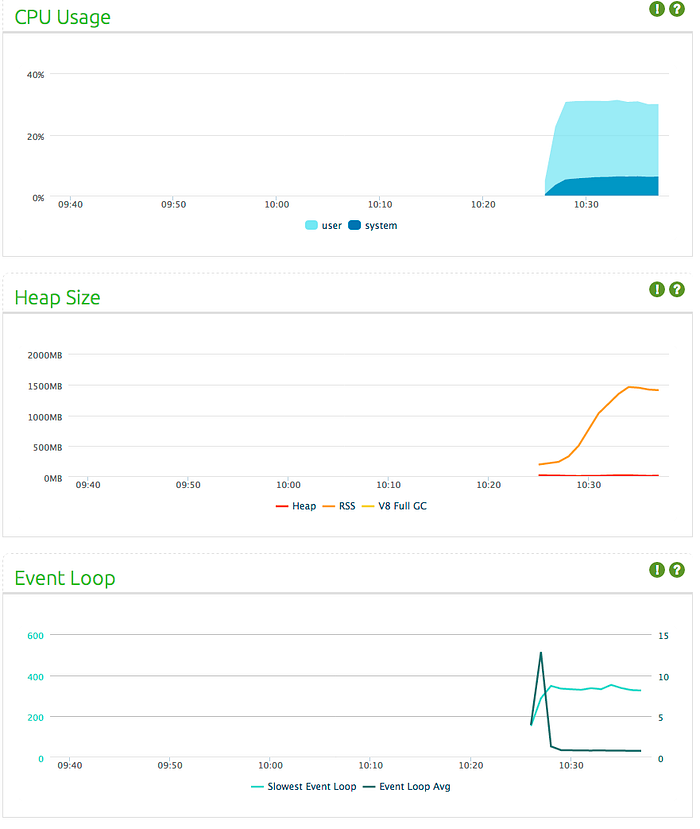 Heap size stops increasing when connections start dropping, and keeps stable as Socket.IO clients tries to connect back. Also notice the very low event loop latency.
Heap size stops increasing when connections start dropping, and keeps stable as Socket.IO clients tries to connect back. Also notice the very low event loop latency.
It’s time to debug!
I used Mozilla’s memwatch module to detect memory leaks and take heap dumps to inspect the data. I found out that somehow 10MB Buffer objects would stack up constantly, you can find more details in my Stackoverflow Question. I couldn’t figure out why this would happen, but I think due to some cumulative CPU intensive operations, event loop response slows down and operations (sending messages) stack up in the queue. Being stuck, I decided to try out Sock.js.
I must admit my Sock.js adventure didn’t last long after discovering that Sock.js does not support connection query strings. This would mean that I’d need to amend my code so that after clients connect, they’d need to send a seperate message to pass the parameter(s), and this was a bit turn off. Next, I decided to give Engine.IO a try.
Engine.IO (v 0.7.12)
As far as I’ve seen, both Engine.IO and Socket.IO are mainly developed by Guillermo Rauch, and Engine.IO is a lower level library. Socket.IO v0.9 appears to be somewhat outdated and Engine.IO is the interim successor until Socket.IO v1.0 is released — which will use Engine.IO. One major difference is that Engine.IO always establishes a long-polling connection first, then tries to upgrade to better transports. This makes it resilient to firewalls and proxies, gives more predictable results and less frequent reconnecting. All other differences are very well listed on project’s readme. As you see, Engine.IO first started to connect via long-polling, then connected via WebSockets:
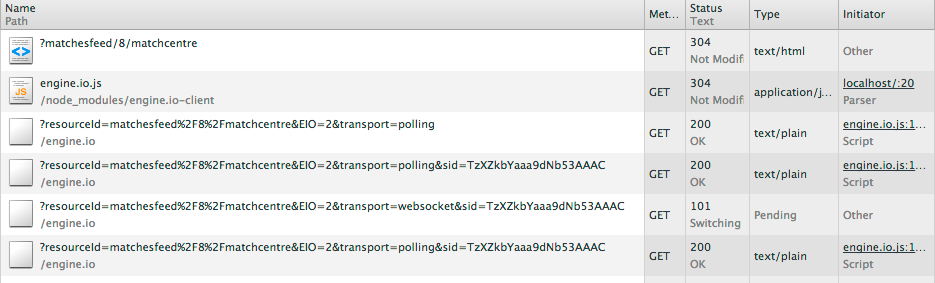 Notice the ‘transport’ parameter
Notice the ‘transport’ parameter
However its client library does not try to reconnect when connection terminates.
Same load test with same values (160KB sent every second to 120 clients) looks like:
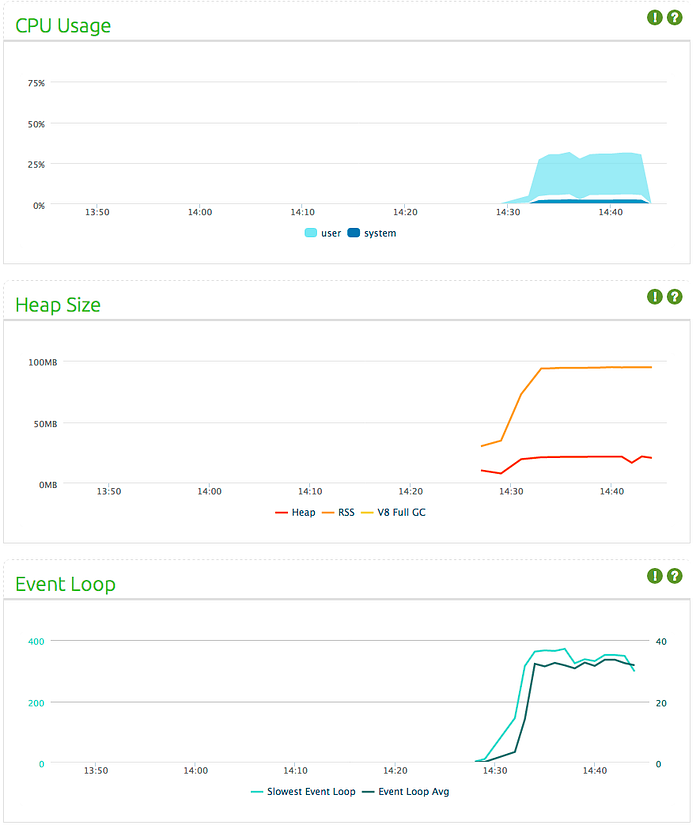
Performance limit
Let’s see what happens when we increase connection size. Engine.IO’s performance proved to be better for my application: I could load test with 230 concurrent connections, with (again) each one sent 165KB of data every second. Any number above 230 connections resulted in the application using massive amounts of data — up to 2GB (the same issue with Socket.IO implementation). Then connections would start dropping until 160 connections are remaining, and obviously this results in less resource usage. You can see this drop in the charts below. Remember in Engine.IO client implementation, clients don’t reconnect once they are disconnected.
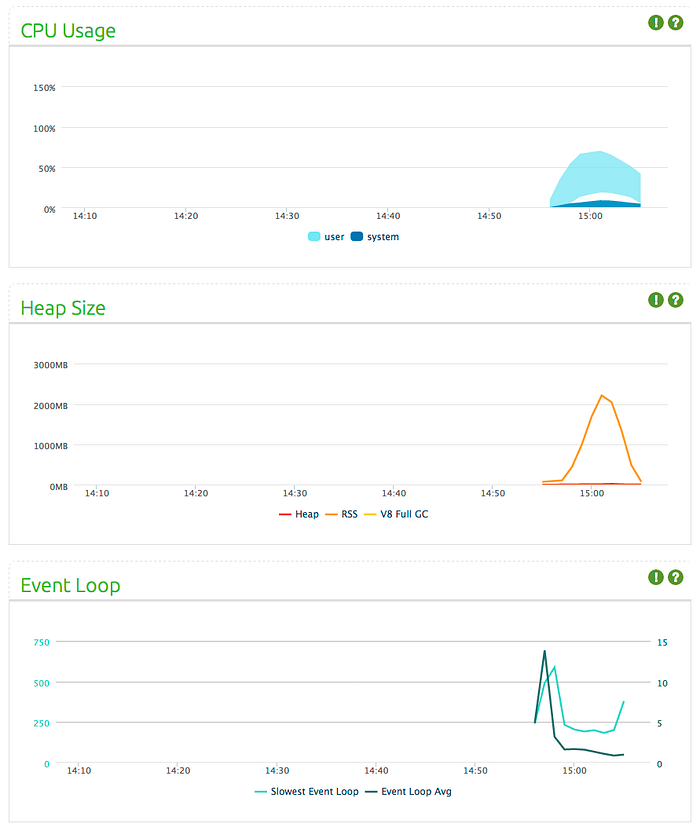
Primus (v 1.5.0)
When I was about to end my research and development, I came across Primus. It is developed by Arnout Kazemier who is an active collabrator in some of the projects mentioned above. Primus actually lets you do what I have done all this time (changing WebSocket technologies for the business logic) dead easy: only with a single line of code. It has a similar syntax with all of the other frameworks, reconnects clients when connection terminates, and has lots of cool methods and structures — like rooms.
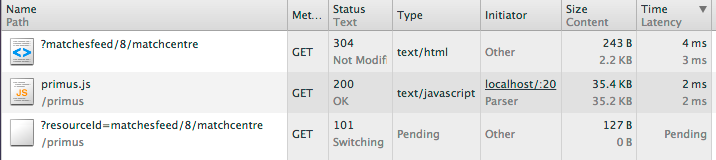 Primus connects
Primus connects
Here are the test results for einaros/ws library with Primus (160KB sent every second to 120 clients):
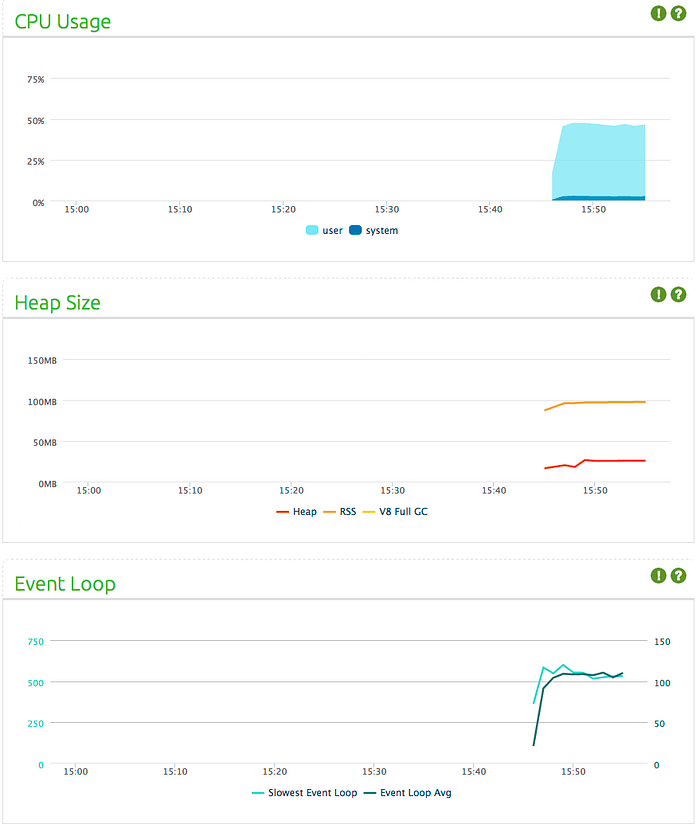
Compared to native implementation, it has a higher CPU usage and event loop latency, but a bit lower memory consumption. However, something unexpected happens after 10 minutes pass:
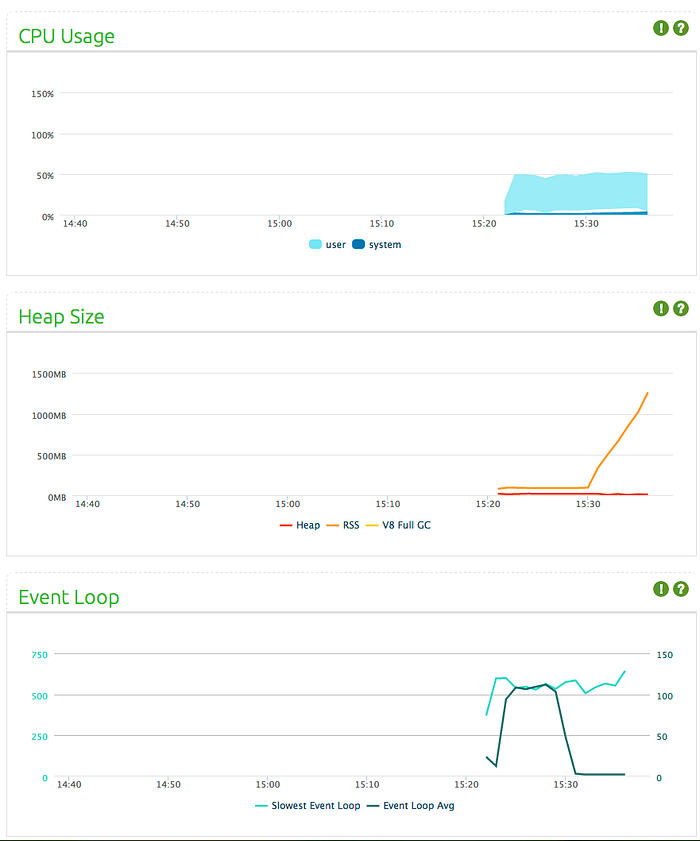
Event loop average drops to almost 0ms, but memory allocation starts to stack up, reaching GBs in minutes. This happened twice in two of my tries. I decided to leave this instead of digging deeper. (Please see Arnout’s comment about this issue on the right hand side)
As Primus is a wrapper for socket libraries, I decided to use a native library just to have things on a lower level.
Looking back: Performance limit of einaros/ws
At this point, I wanted to look back and see at what rate einaros/ws implementation (which I ditched as it doesn’t support other connection types) would crash.
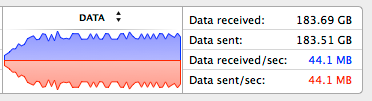
By handling 410 concurrent connections, sending 165KB data to each every second, einaros/ws’s performance was far more superior than any other framework I tried. Compare it with Socket.IO’s max 140 connections and Engine.IO’s max 230 connections. einaros/ws would fail at 415 connections in the same way with other implementations: memory usage would stack up seemingly almost indefinitely (I waited until 8GB consumption before killing the process).
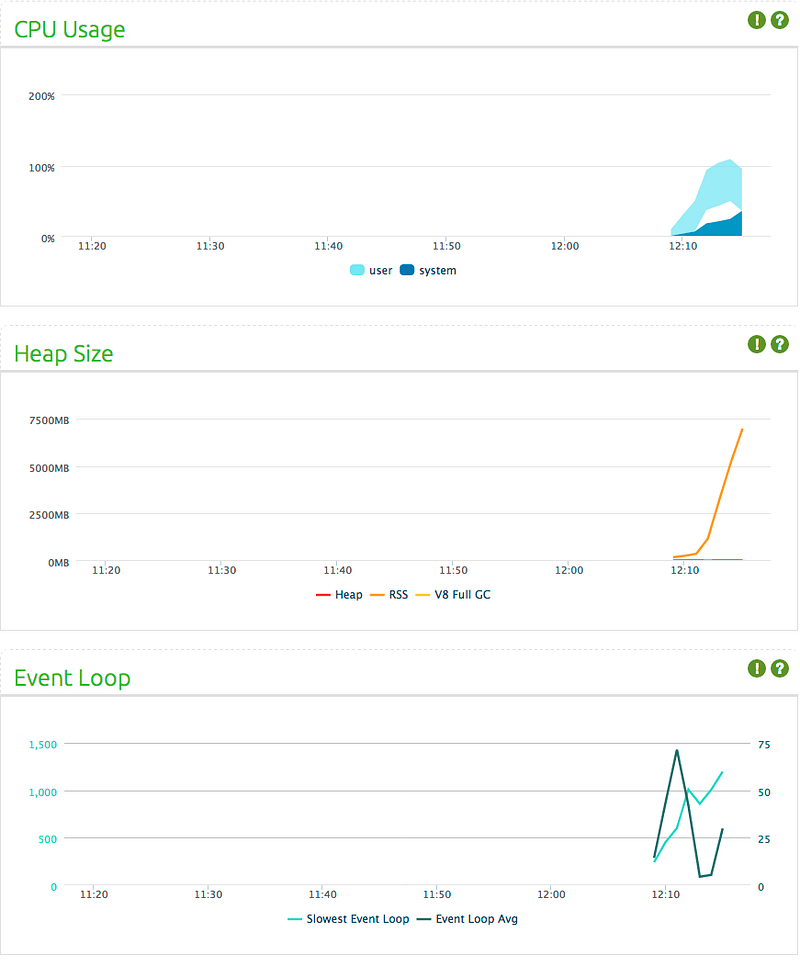
Final decision on the framework
In summary, these test results showed that Engine.IO looks like the better choice for my application. It supports different connection types apart from WebSockets, and has a significantly better memory usage compared to others.

The difference in memory seems like a good trade of for losing the functionality of clients not reconnecting in a connection failure. At least, until Socket.IO 1.0 is released.
Changing the flow based on limitations
The aim when starting this project was to have a system that can support thousands, even 10 thousand concurrent users. It seems, with 165KB of data sent every second, this won’t be possible. This made me decide to decrease the data size, and introduce a delta model, in which the application would send only the new JSON content instead of the whole object each time.
Test 1: The impact of data size
I ran the a load test that uses 5KB of data, sent to 4000 users every second. 5KB of JSON makes around 200 lines of data with reasonable string length. I’ve also modified the test so that 10 new clients connect every second. The data throughput is equivalent to 20MB sent per second.
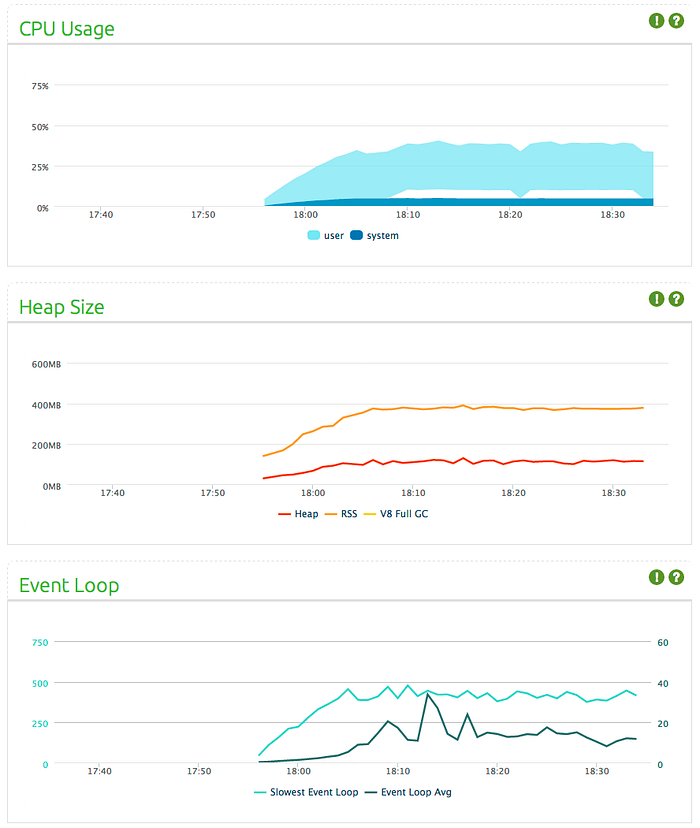
We will take these values as a base and see what happens when we keep throughput same and change some variables.
Test 2: The impact of concurrent connection size
In this test, 2000 users connected to the server, and received 10KBs of data every second. Again in this case, 20MB is sent every second.
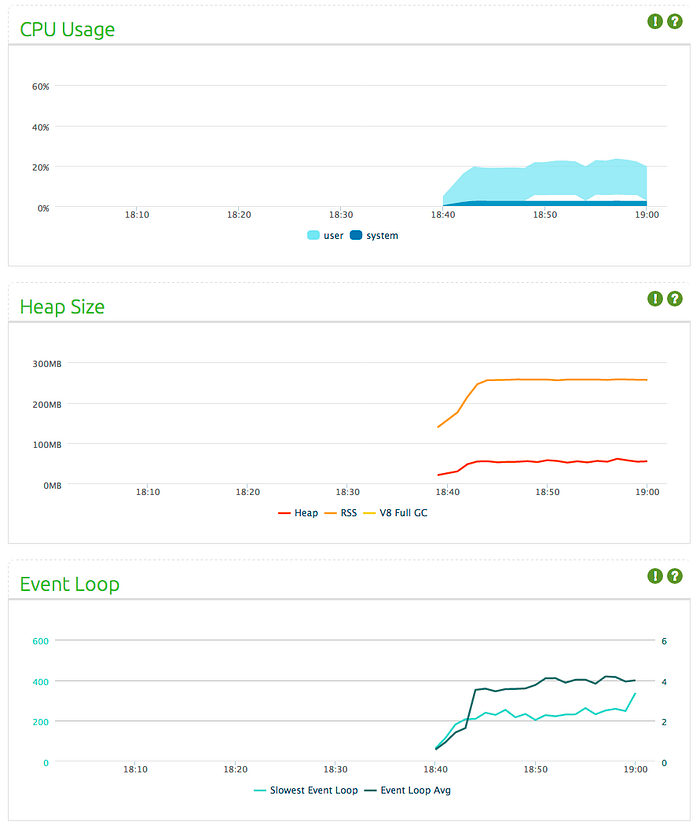
Compare these results with test one. As you see, doubling the data size and decreasing the connection size by half ended up in 20% lower memory consumption, 35% lower CPU usage and 75% less event loop latency.
Test 3: The impact of data broadcasting frequency
In this test, 4000 users connected to the server, and received 10KB of data every 2 seconds. Again, this equals to 20MB sent every second.
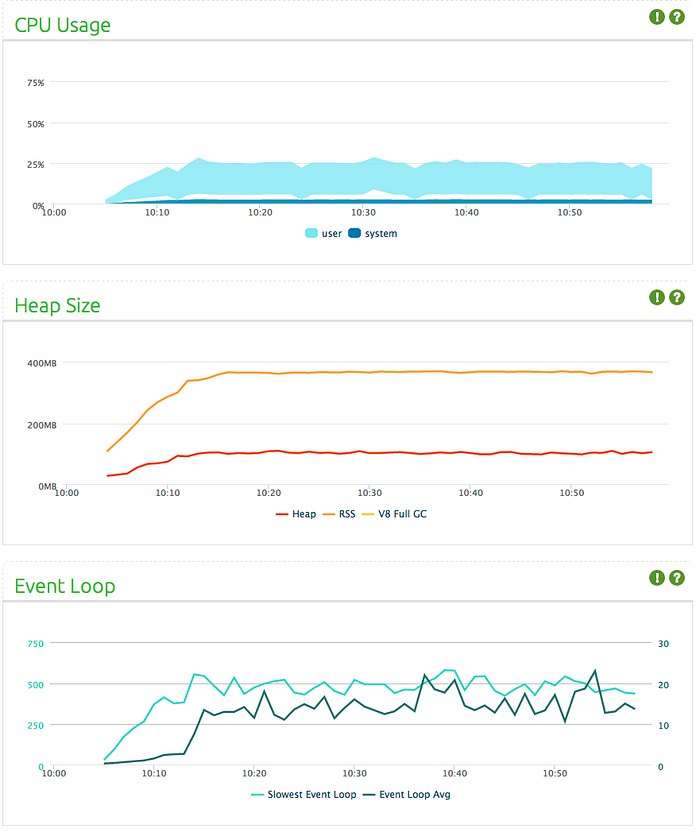
Compare these results with the first test. It seems doubling data size and decreasing frequency of data sent by half results in 25% lower CPU usage, but more or less the same memory consumption and event loop latency.
Conclusion
We do not really have a direct control over how many connections the application will have if we have one server, thus it seems we can only play around with the size of data sent, and how frequent we send this data. These tests show that for a constant throughput, (at least) for Engine.IO, the number of connections have the biggest impact on performance, then comes reducing size of data, and lastly reducing frequency of data sent. Sending larger data in less frequency appears to yield better performance. It’s a double-sided sword though: increasing size of data packets was what made my applications crash as well.
So I think the best way of balancing it is to estimate the max number of concurrent users in the long run (at least a couple of years forward), finding the maximum data size that can be used with that number, and then decrease the frequency of sending data if possible — but as said this is not that critical. After this point, as connection number has the biggest impact on the performance, by using a load balancer, adding more application instances should increase the performance more than any other method.