
圖卷積神經網路介紹(GCNs)
之前承諾要寫一個關於graph network的介紹,因為隨著deep learning的發展達到一個很高的水平,reasoning(推理)能力的具備變得異常迫切。而knowledge graph則是實現reasoning的重要途徑之一,如何從複雜的graph中學習到潛在的知識是一項非常challenging的任務,圖作為knowledge的儲存媒介,deep learning作為資訊抽取的重要工具,二者的結合可謂是必然趨勢。下面我將結合之前看過的一篇國外的部落格,為大家入門graph neural network拋一塊磚。
在開始之前,多說幾句,關於graph和deep learning結合的工作,想必大家都能猜到名字該怎麼取,無非是這幾個關鍵詞的組合:Graph,Neural,Network,Convolution…所以,許多工作從paper名字來看並沒有多大的區分性。
前言
現實世界許多資料都是以graph的形式儲存的,比如social networks(社交網路), knowledge graphs(知識圖譜), protein-interaction networks(蛋白質相互作用網路), the World Wide Web(全球資訊網),最近有一些研究者把目光投向建立一種通用的神經網路模型來處理graph資料。在此之前,該領域的主流方法是一些基於kernel的方法或基於graph的正則化技術,不過從deep learning的角度來講,這些已經屬於“傳統方法”了,不是我們要討論的主題,不瞭解也沒有關係。
GCNs:定義
由於大家的思想普遍是如何將CNN等神經網路的思想遷移到graph上,所以往往設計出來的結構都有一定的共性,使用類似convolution權重共享的思想,我們可以把這類網路暫且都稱作Graph Convolutional Networks(GCNs)。這類網路從數學上來看,是想學習上的一個函式,該函式的輸入是:
- 每一個節點的的特徵表示,如果節點數為,特徵維度為維,則所有節點的特徵可組成一個的矩陣
- 圖結構的表達,往往使用圖的鄰接關係矩陣表示
該函式產生一個node-level的輸出(是一個的矩陣,代表節點數量,每一行代表一個節點,代表節點特徵向量的維度)。如果想要得到graph-level的特徵表達,只需要將每一個node的表達綜合起來再經過一個對映操作即可。
和卷積神經網路一樣,對於graph的特徵提取我們同樣可以使用多層神經網路結構,對於每一層,我們可以使用如下的對映函式來計算:
其中表示第層graph的node-level表達,是一個維的矩陣,代表node數量,代表第層節點表達的維度(節點表達的維度可以在每一層都不一樣,由決定,可以靈活設定,詳見下節例子);表示第0層的初始化節點表達矩陣;假設一共有層網路,則表示最後一層輸出的節點表達矩陣(上一段已經說了,表示最後一層節點的特徵向量維度)。
GCNs : 舉例
針對上一節提到的層間的對映函式,我們可以採用如下式的方式實現:
這裡, , ,是非線性啟用函式。這裡簡單解釋一下這麼做的物理意義,首先,鄰接矩陣與相乘的作用是使節點的鄰接節點值求和聚集到該節點上,為了不丟失該節點本來的資訊,我們往往會強制每一個節點到自己也有一個連線,即一個self-loop,相當於讓鄰接矩陣加上一個單位矩陣,則上式變成如下形式。
儘管該模型看著很簡單,但實際上已經非常powerful了,不過我們還是可以力所能及的對模型做一些改進,使模型發揮更大的效能。首先,鄰接矩陣並沒有歸一化,這樣會導致每經過一次相乘節點特徵的尺度就會變大,這樣我們可以進一步將公式變為如下形式:
這樣,本質上我們就實現了Kipf & Welling (ICLR 2017)中設計的傳播模型。
GCNs : 例項
本節我們利用上面介紹的模型實現一個分類問題。首先大家可以先看一下Zachary’s karate club network資料集以及它的背景,該資料集可以以下圖的形式呈現,簡單介紹的話就是說一個空手道俱樂部內部出現矛盾要被拆分為兩波人,我們需要依據隊員們平時的交往關係來判斷他們會站哪一支隊伍,圖中每個節點表示一個隊員,若兩個節點之間存在邊,則表示對應兩個隊員之間關係密切。下圖使用clustering做個一個簡單的劃分,僅做參考,顏色相同的表示最後分在一組(這裡作者貌似沒有分為2類,而是4類)。

這裡使用上述介紹的模型對每個node做embedding(這裡網路設定為3層,使用了半監督,具體可以看原文Kipf & Welling ,不過大可以當做有監督來看),embedding後的效果就是同一組特徵在空間上距離相近,下面的video展示了embedding的過程,效果還是相當明顯的:
顯示不了的話可移步https://youtu.be/EuK4L61JmcQ觀看
GCNs:啟發式的解釋
我們發現一個很有意思的現象,就是當我們還沒有開始訓練,僅僅是隨機初始化上述模型的引數之後,也產生了一定的embedding效果,如下圖所示:
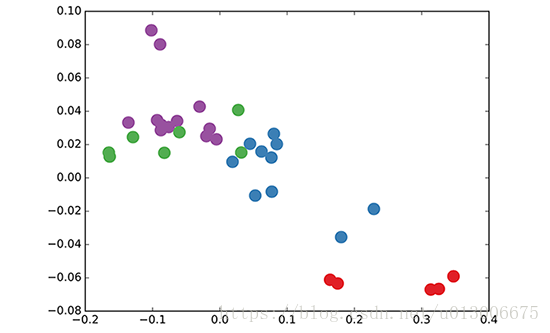
近期一個叫DeepWalk (Perozzi et al., KDD 2014)的工作表明他們可以使用無監督的方式產生一個相似的embedding效果,這聽起來挺不可思議的,我們試圖從Weisfeiler-Lehman演算法的角度來解釋,並把GCNs看做該演算法的通用、可微版。
其實下面的部分可看可不看,因為我並沒與覺得作者的解釋有多少說服力,感興趣的可以看一下原文。
之前做過一個PPT,也簡單的介紹了一下三種graph neural network,需要的可以點選這裡瀏覽一下。
由於水平所限,可能文中很多地方解釋的不好,歡迎大家批評指正,相互進步,謝謝~