
深度學習在CV領域的進展以及一些由深度學習演變的新技術
CV領域
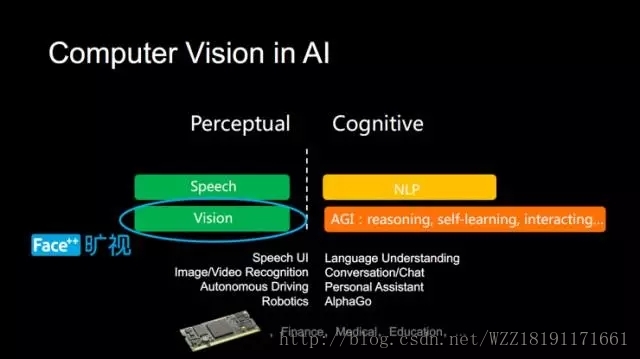
1.進展:如上圖所述,當前CV領域主要包括兩個大的方向,”低層次的感知” 和 “高層次的認知”。
2.主要的應用領域:視訊監控、人臉識別、醫學影象分析、自動駕駛、 機器人、AR、VR
3.主要的技術:分類、目標檢測(識別)、分割、目標追蹤、邊緣檢測、姿勢評估、理解CNN、超解析度重建、序列學習、特徵檢測與匹配、影象標定,視訊標定、問答系統、圖片生成(文字生成影象)、視覺關注性和顯著性(質量評價)、人臉識別、3D重建、推薦系統、細粒度影象分析、影象壓縮
分類主要需要解決的問題是“我是誰?”
目標檢測主要需要解決的問題是“我是誰? 我在哪裡?”
分割主要需要解決的問題是“我是誰? 我在哪裡?你是否能夠正確分割我?”
目標追蹤主要需要解決的問題是“你能不能跟上我的步伐,儘快找到我?”
邊緣檢測主要需要解決的問題是:“如何準確的檢測到目標的邊緣?”
人體姿勢評估主要需要解決的問題是:“你需要通過我的姿勢判斷我在幹什麼?”
理解CNN主要需要解決的問題是:“從理論上深層次的去理解CNN的原理?”
超解析度重建主要需要解決的問題是:“你如何從低質量圖片獲得高質量的圖片?”
序列學習主要解決的問題是“你知道我的下一幅影象或者下一幀視訊是什麼嗎?”
特徵檢測與匹配主要需要解決的問題是“檢測影象的特徵,判斷相似程度?”
影象標定主要需要解決的問題是“你能說出影象中有什麼東西?他們在幹什麼呢?”
視訊標定主要需要解決的問題是“你知道我這幾幀視訊說明了什麼嗎?”
問答系統主要需要解決的問題是:“你能根據影象正確回答我提問的問題嗎?”
圖片生成主要需要解決的問題是:“我能通過你給的資訊準確的生成對應的圖片?”
視覺關注性和顯著性主要需要解決的問題是:“如何提出模擬人類視覺注意機制的模型?”
人臉識別主要需要解決的問題是:“機器如何準確的識別出同一個人在不同情況下的臉?”
3D重建主要需要解決的問題是“你能通過我給你的圖片生成對應的高質量3D點雲嗎?”
推薦系統主要需要解決的問題是“你能根據我的輸入給出準確的輸出嗎?”
細粒度影象分析主要需要解決的問題是“你能辨別出我是哪一種狗嗎?等這些更精細的任務”
影象壓縮主要需要解決的問題是“如何以較少的位元有損或者無損的表示原來的影象?”
注:
1. 以下我主要從CV領域中的各個小的領域入手,總結該領域中一些網路模型,基本上覆蓋到了各個領域,力求完整的收集各種經典的模型,順序基本上是按照時間的先後,一般最後是該領域最新提出來的方案,我主要的目的是做一個整理,方便自己和他人的使用,你不再需要去網上收集大把的資料,需要的是仔細分析這些模型,並提出自己新的模型。這裡面收集的論文質量都比較高,主要來自於ECCV、ICCV、CVPR、PAM、arxiv、ICLR、ACM等頂尖國際會議。並且為每篇論文都添加了連結。可以大大地節約你的時間。同時,我挑選出論文比較重要的網路模型或者整體架構,可以方便你去進行對比。有一個更好的全域性觀。具體 細節需要你去仔細的閱讀論文。由於個人的精力有限,我只能做成這樣,希望大家能夠理解。謝謝。
2. 我會利用自己的業餘時間來更新新的模型,但是由於時間和精力有限,可能並不完整,我希望大家都能貢獻的一份力量,如果你發現新的模型,可以聯絡我,我會及時回覆大家,期待著的加入,讓我們一起服務大家!
如下圖所示:
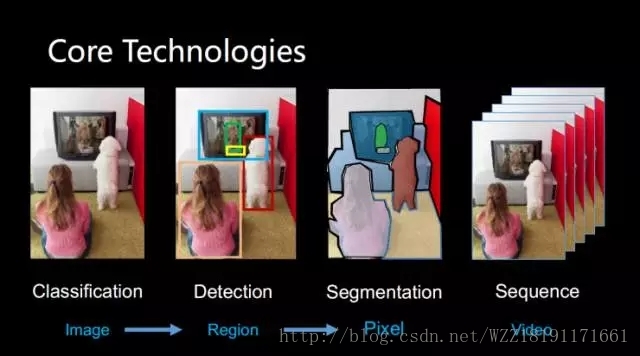
LeNet網路1:
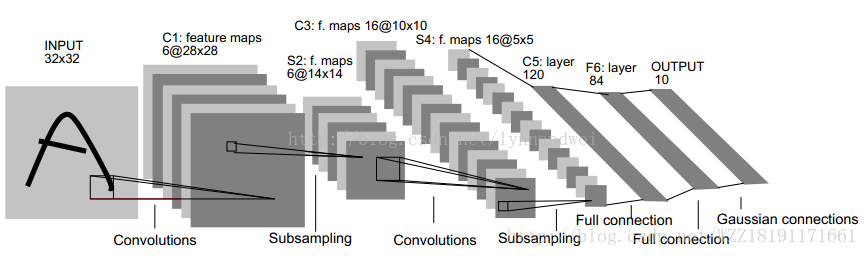
LeNet網路2:
AlexNet網路1:
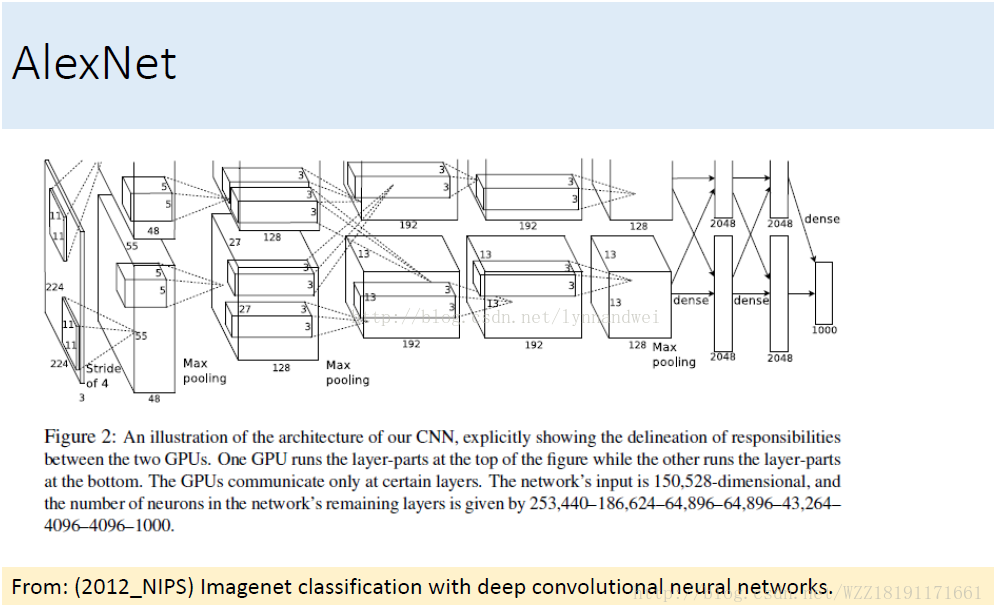
AlexNet網路2:
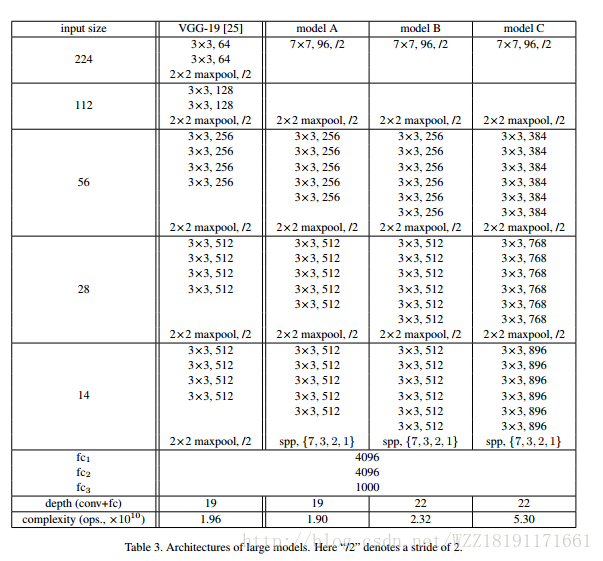
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification網路:
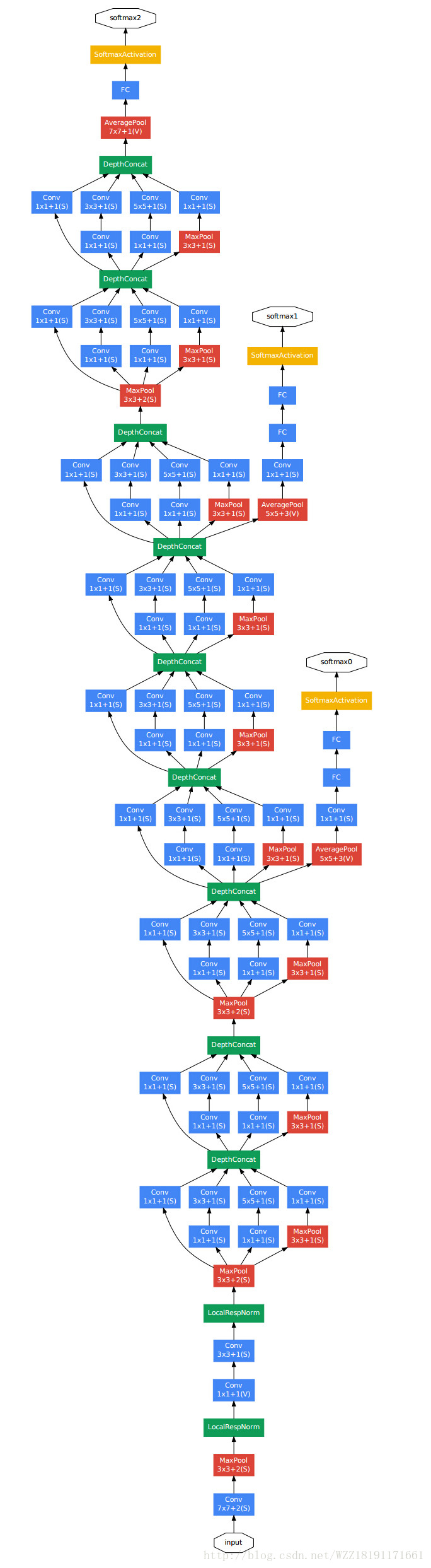
GoogLeNet網路1:

GoogLeNet網路2:
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification網路:
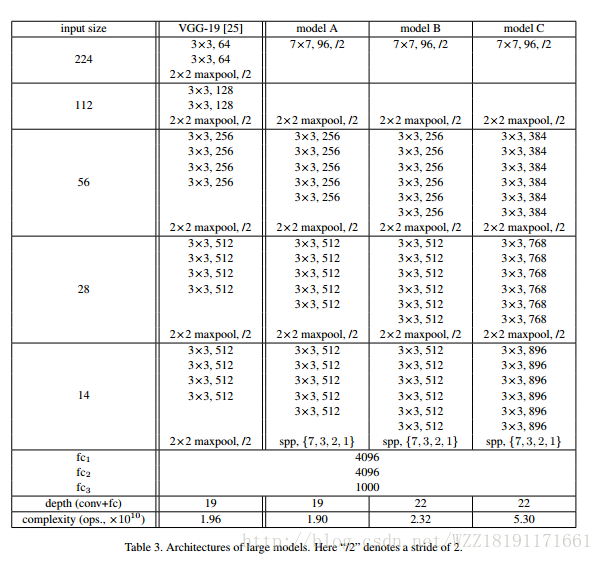
Batch Normalization:
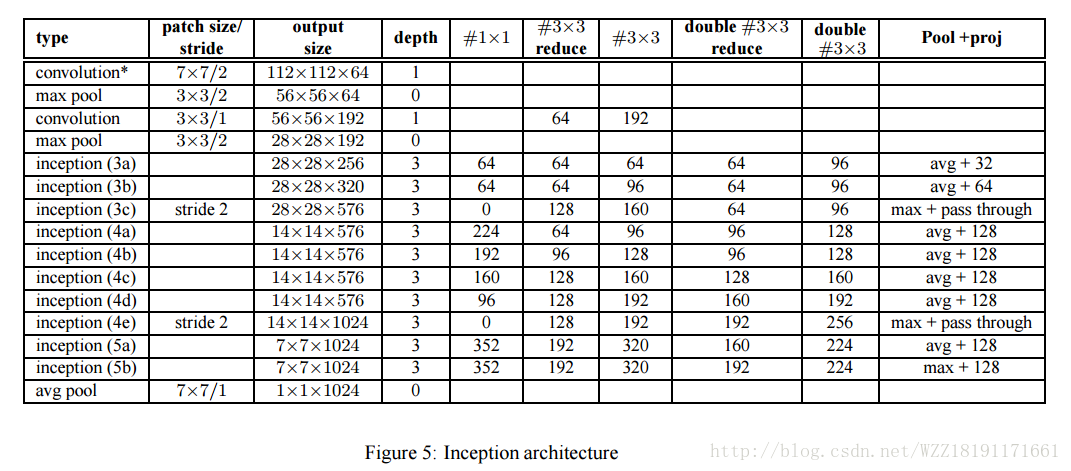
VGGNet網路1:
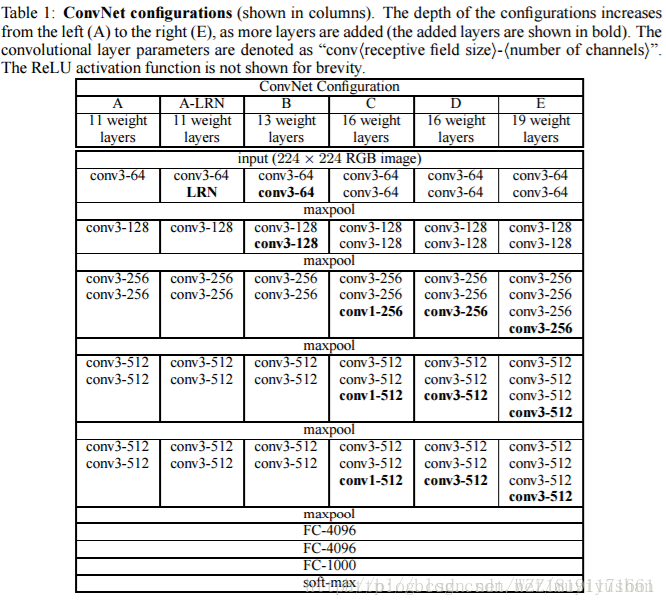
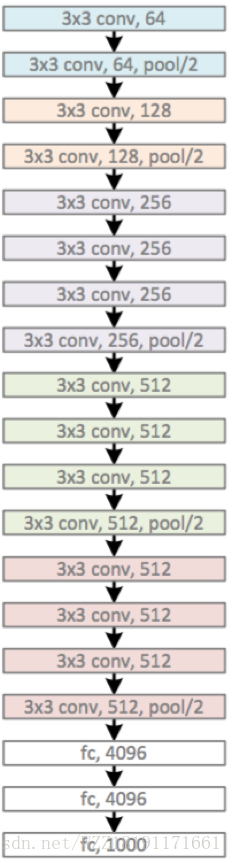
VGGNet網路2:
ResNet網路:
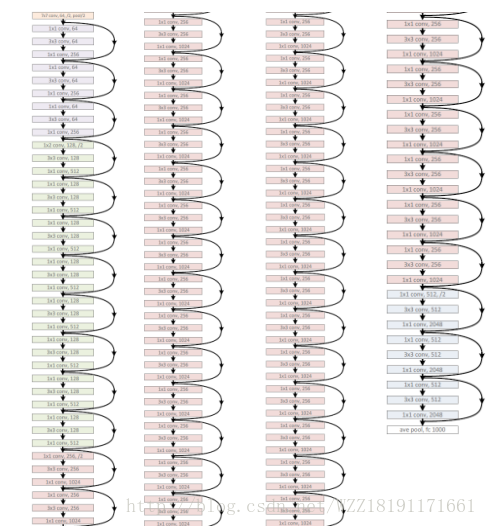
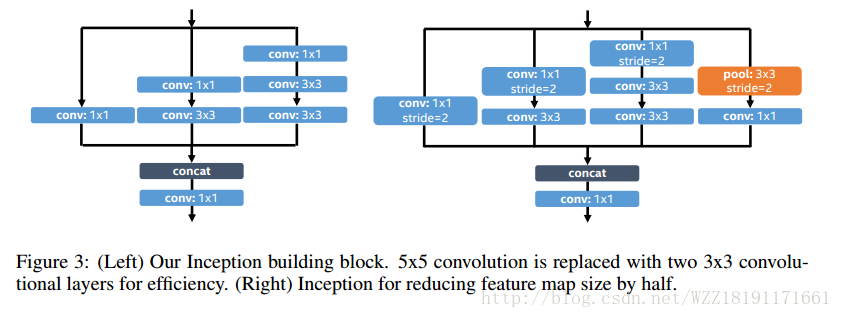
InceptionV4網路:
OVerfeat網路:

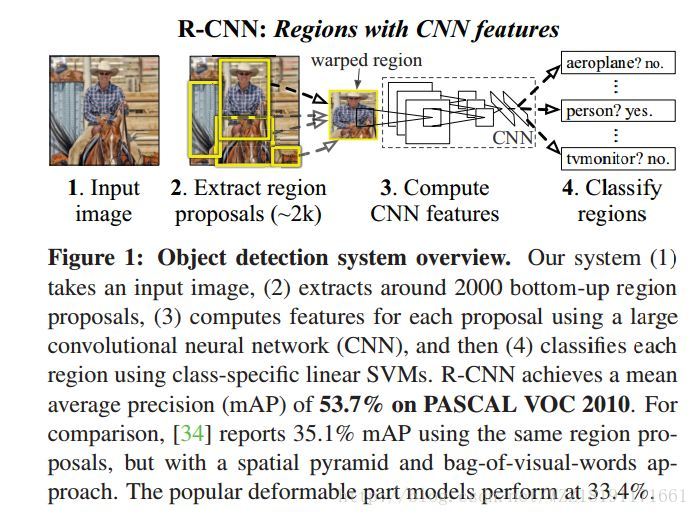
R-CNN網路:
SPP-Net網路:
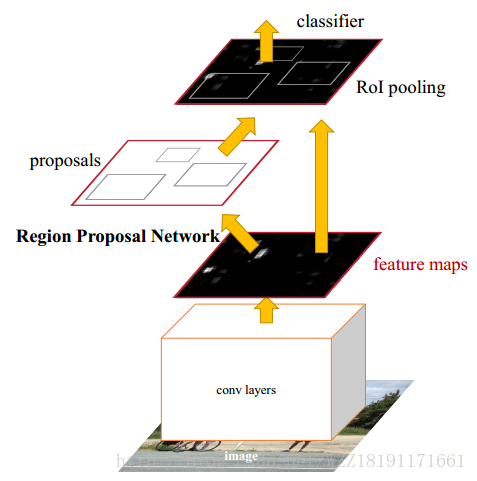
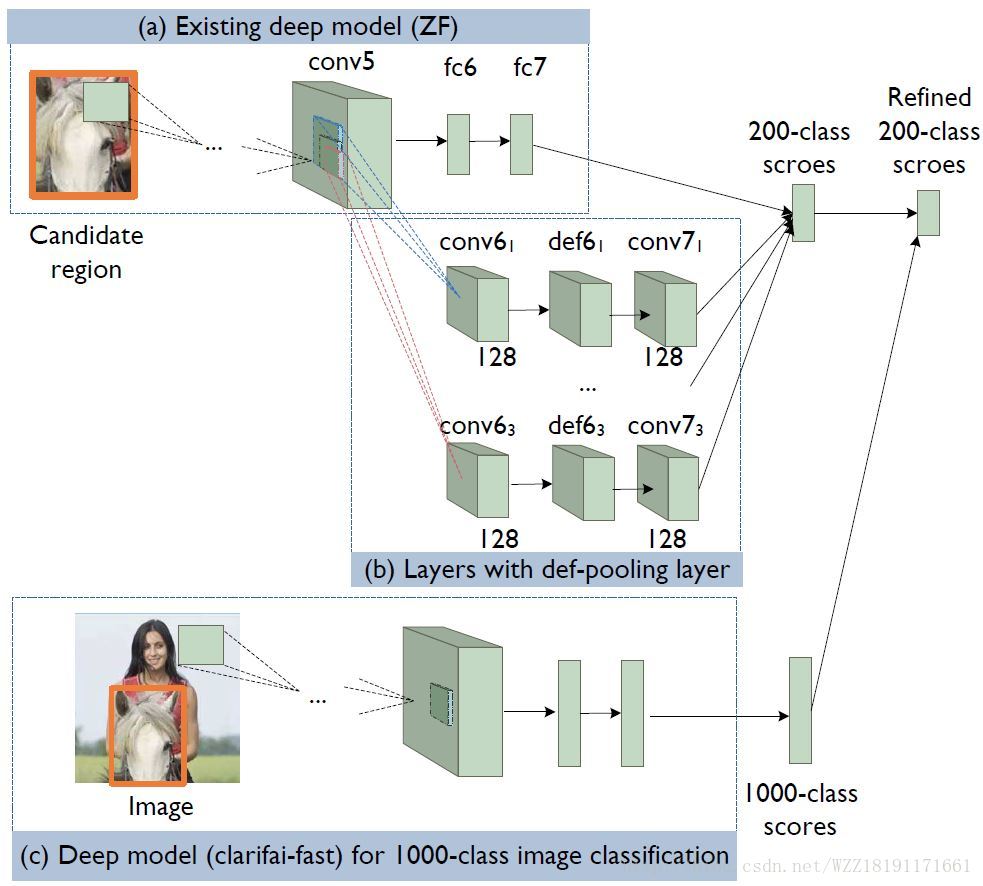
DeepID-Net網路:
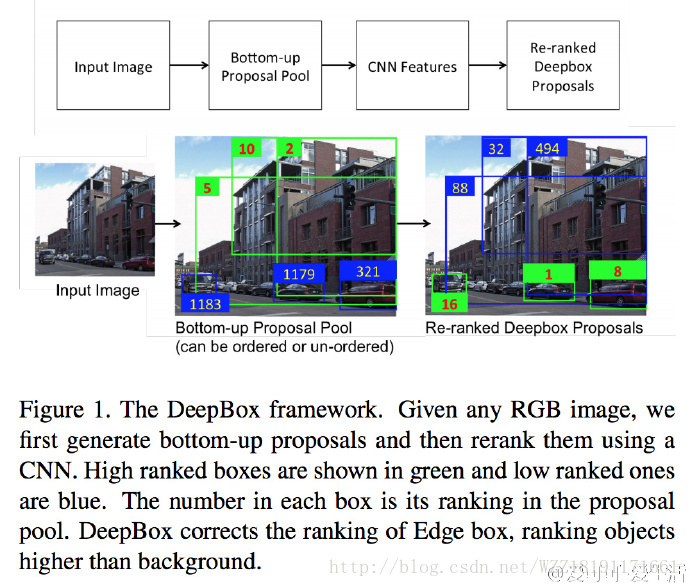
DeepBox網路:
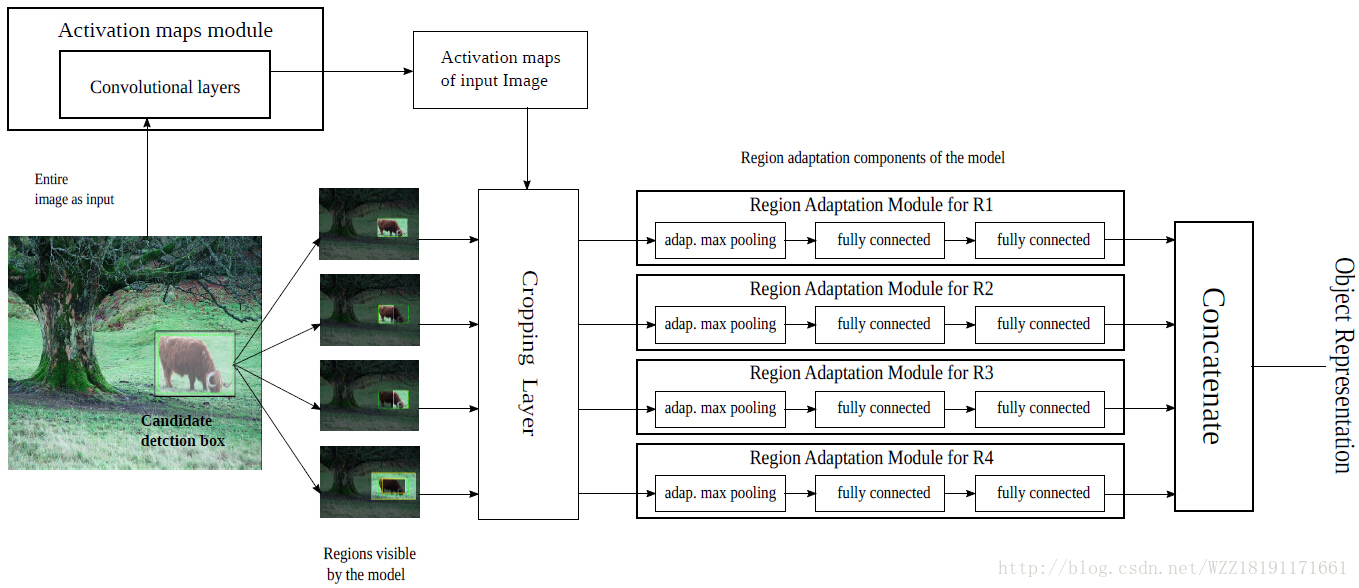
MR-CNN網路:
Fast-RCNN網路:
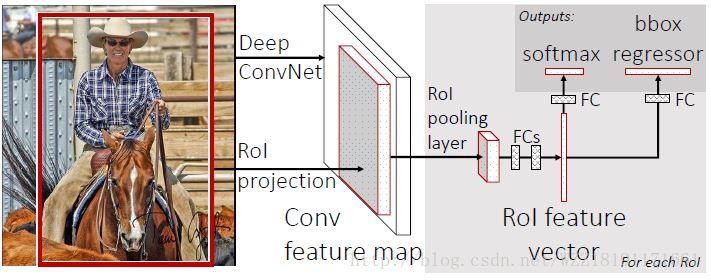
R-CNN minus R網路:

End-to-end people detection in crowded scenes網路:
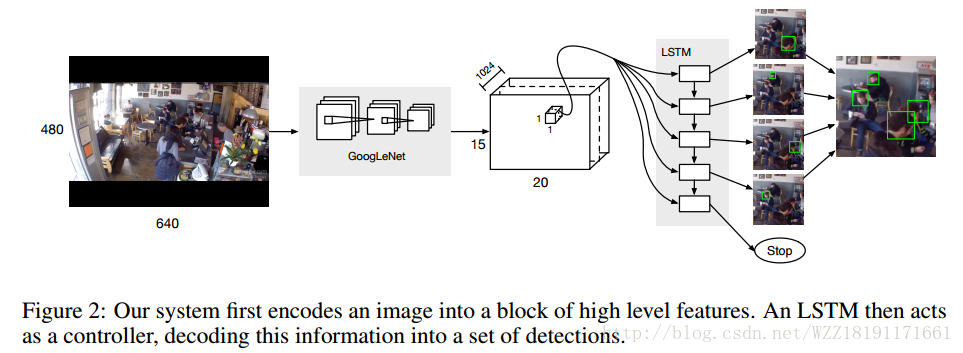
Faster-RCNN網路:
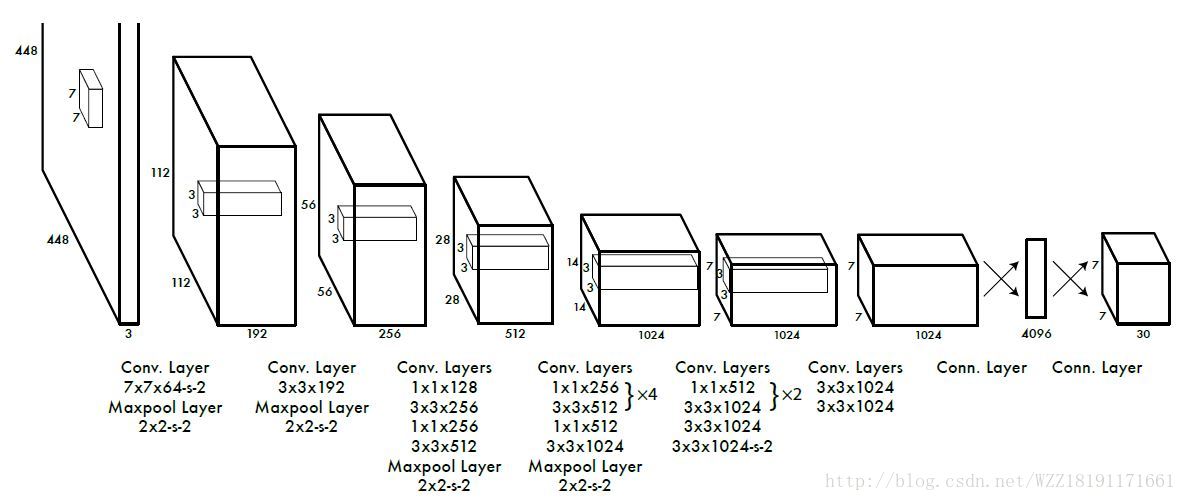
DenseBox網路:
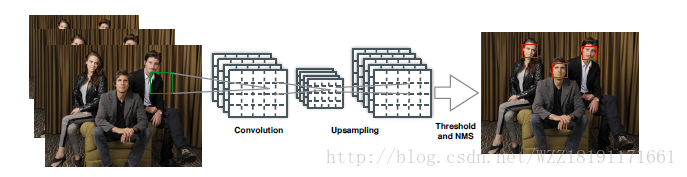
Weakly Supervised Object Localization with Multi-fold Multiple Instance Learning網路:

R-FCN網路:
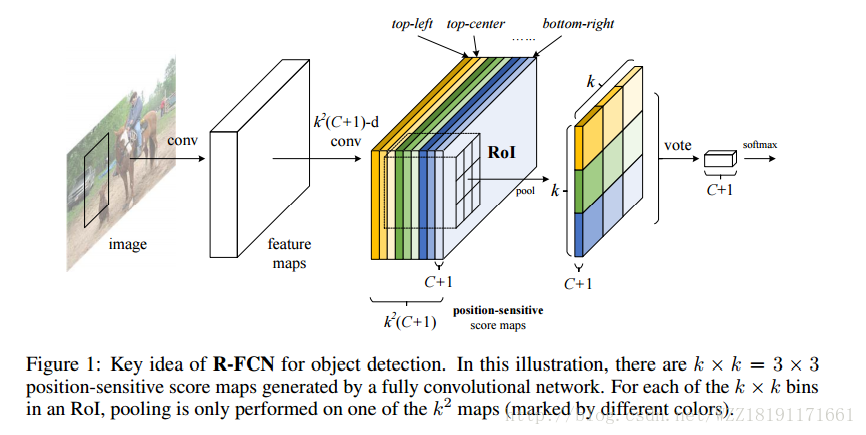
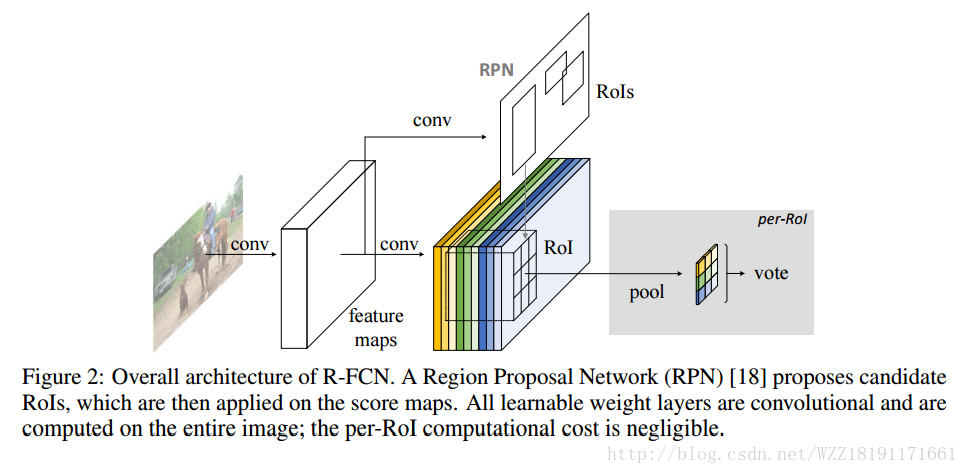
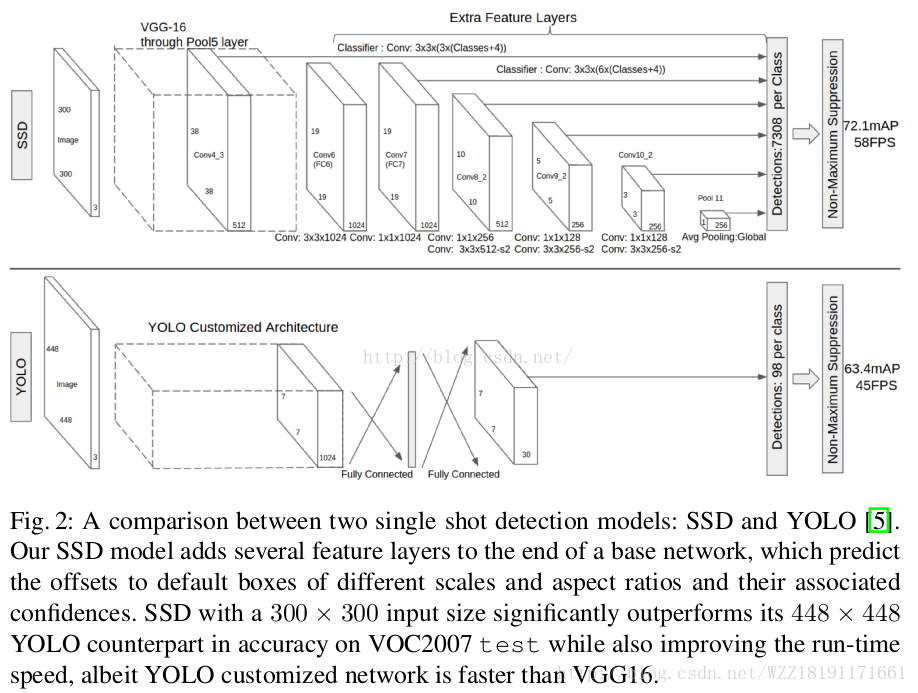
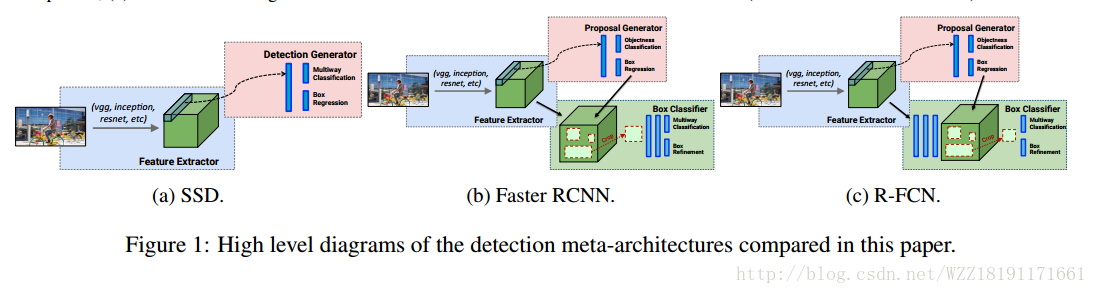
YOLO和SDD網路:
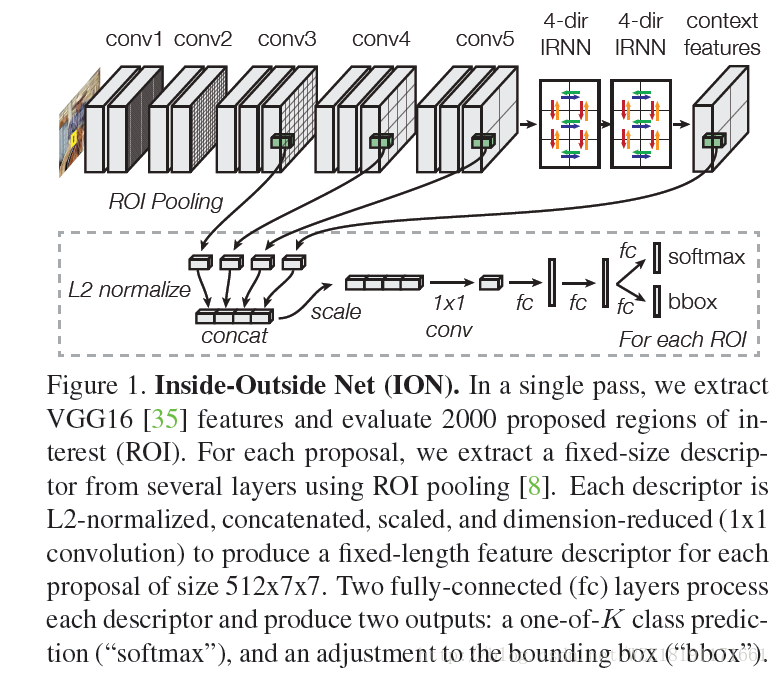
Inside-Outside Net網路:
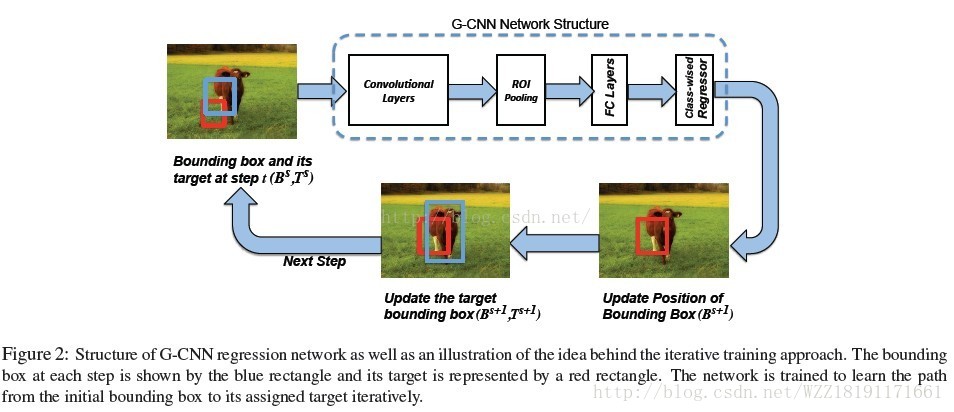
G-CNN網路:
PVANET網路:
Speed/accuracy trade-offs for modern convolutional object detectors:
FCN網路1:
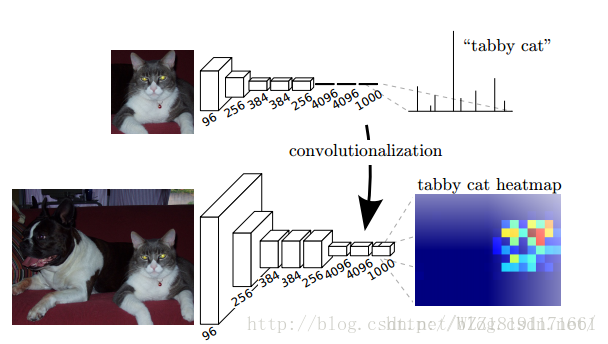
FCN網路2:
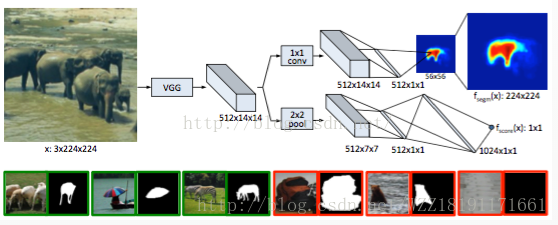
segNet網路:
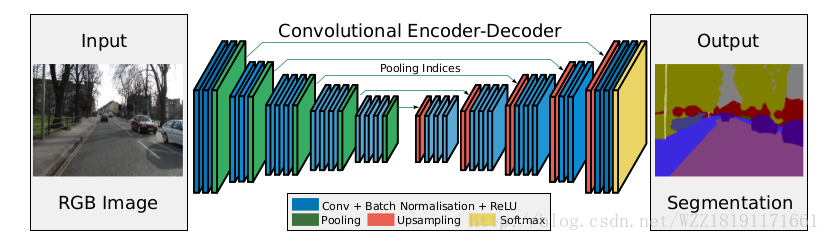
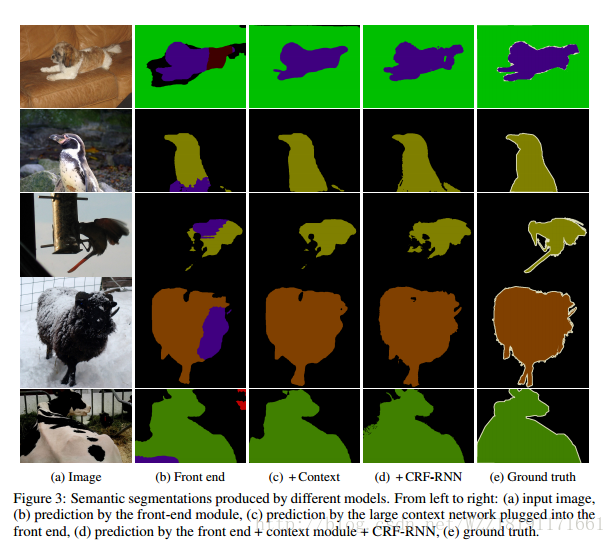
Deeplab網路:
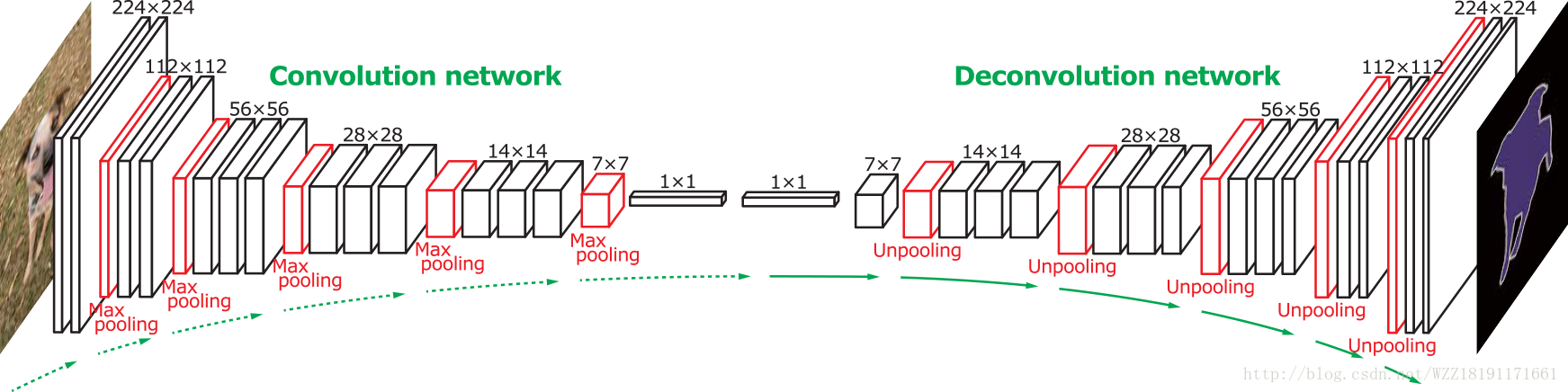
deconvNet網路:
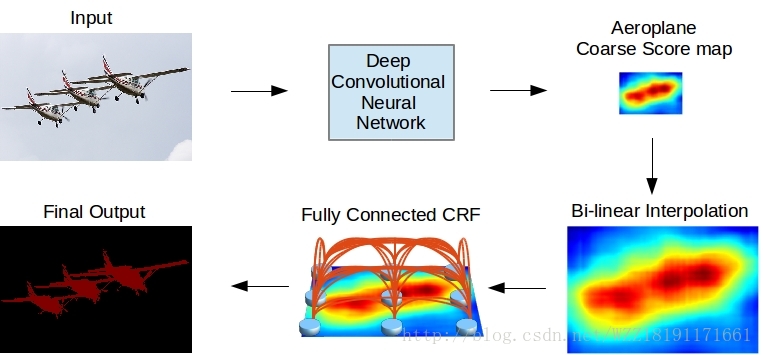
Conditional Random Fields as Recurrent Neural Networks網路:

Semantic Segmentation using Adversarial Networks網路:

SEC: Seed, Expand and Constrain網路:
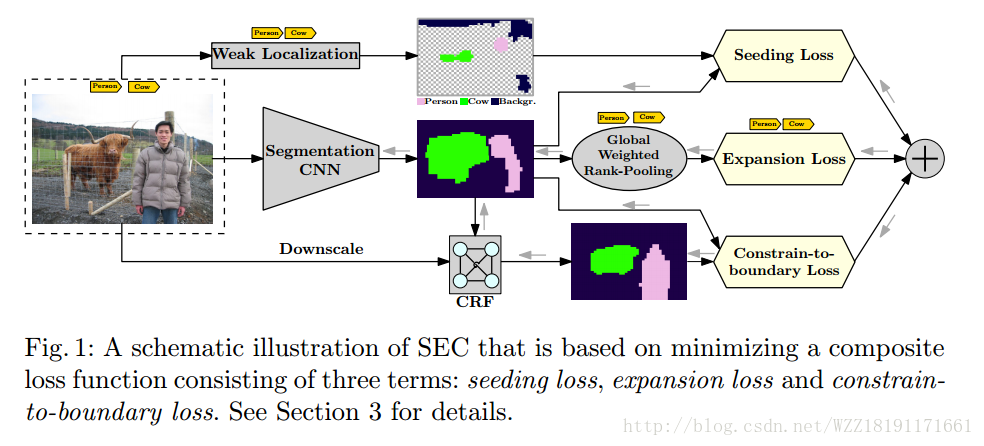
Efficient piecewise training of deep structured models for semantic segmentation網路:
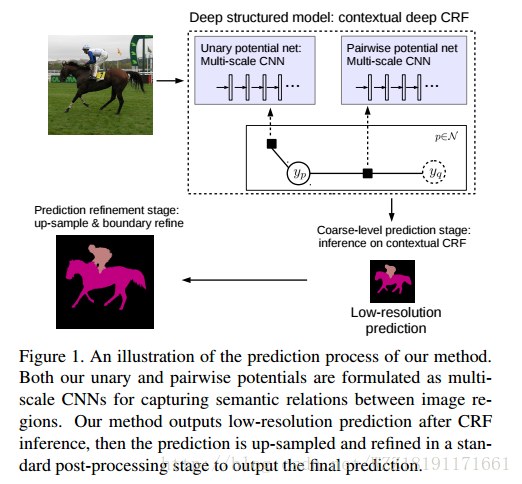
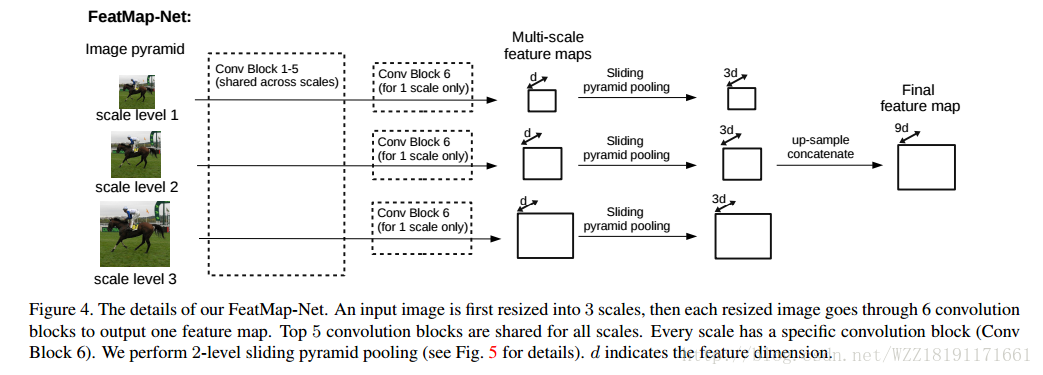
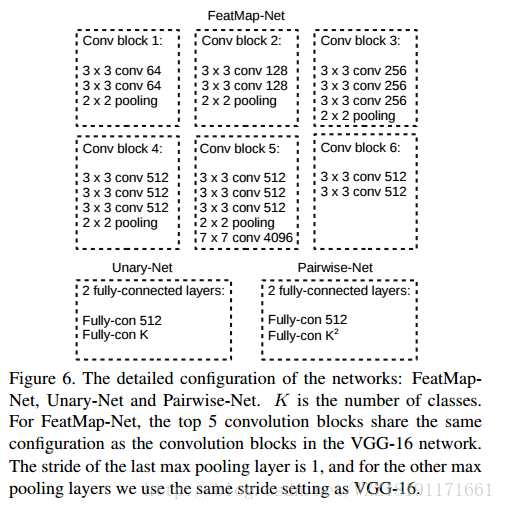
Semantic Image Segmentation via Deep Parsing Network網路:
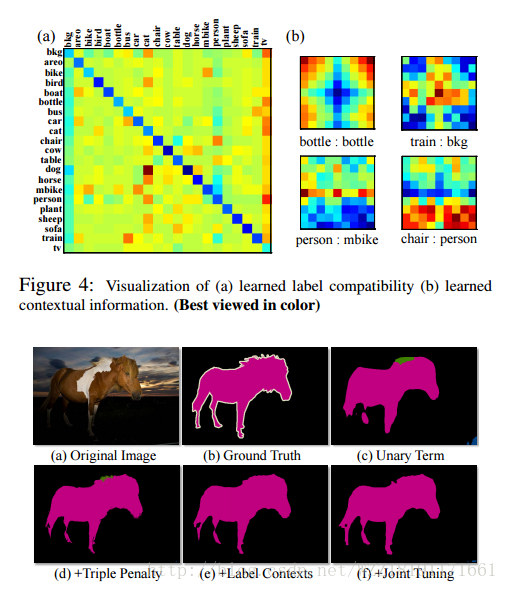
BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation:
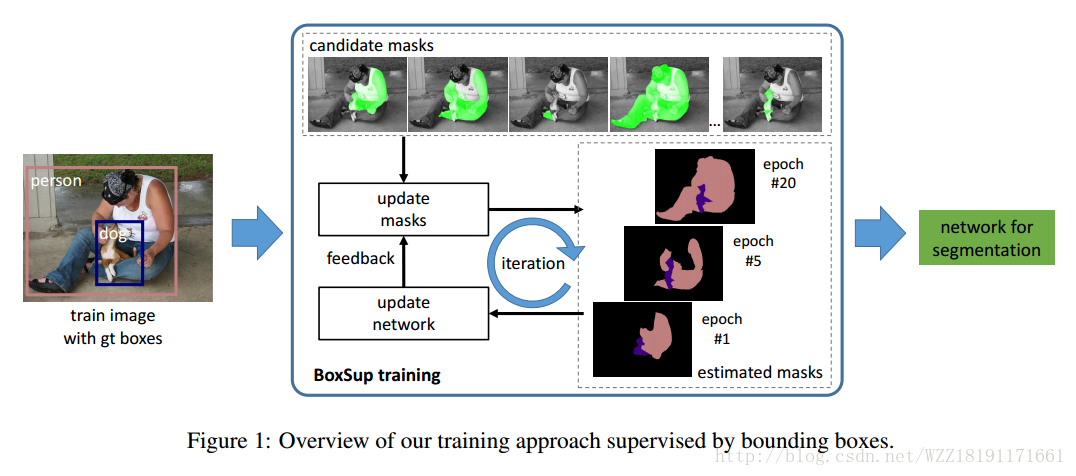
Learning Deconvolution Network for Semantic Segmentation:

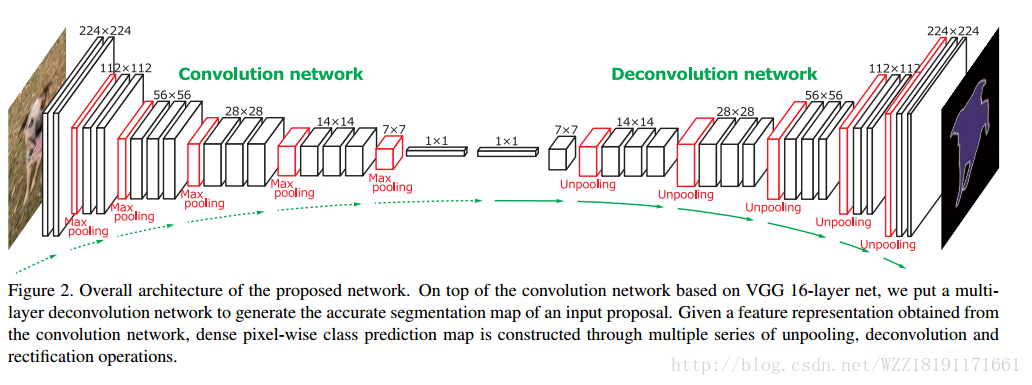
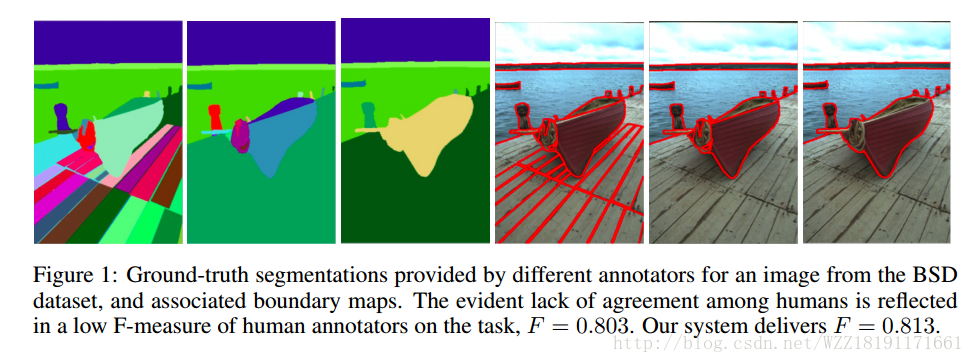
PUSHING THE BOUNDARIES OF BOUNDARY DETECTION USING DEEP LEARNING:
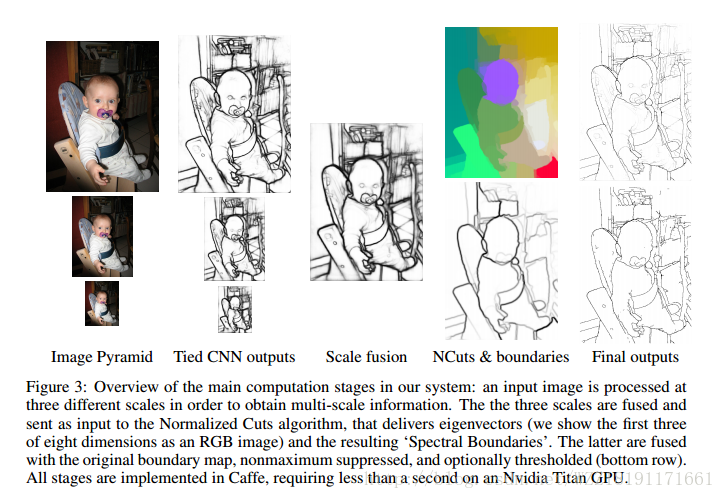
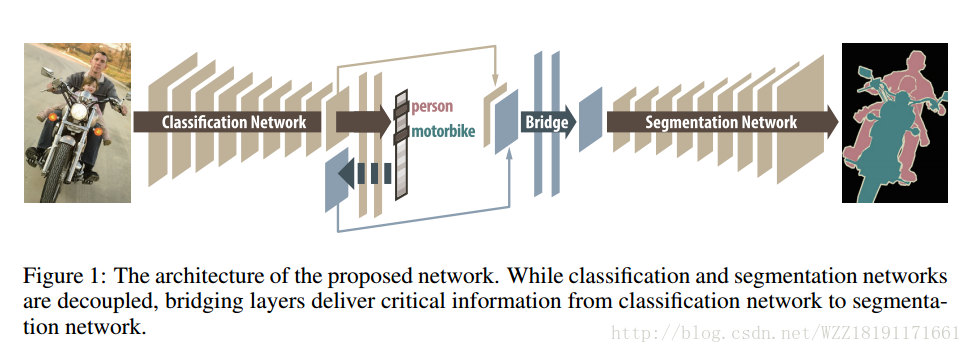
Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation:
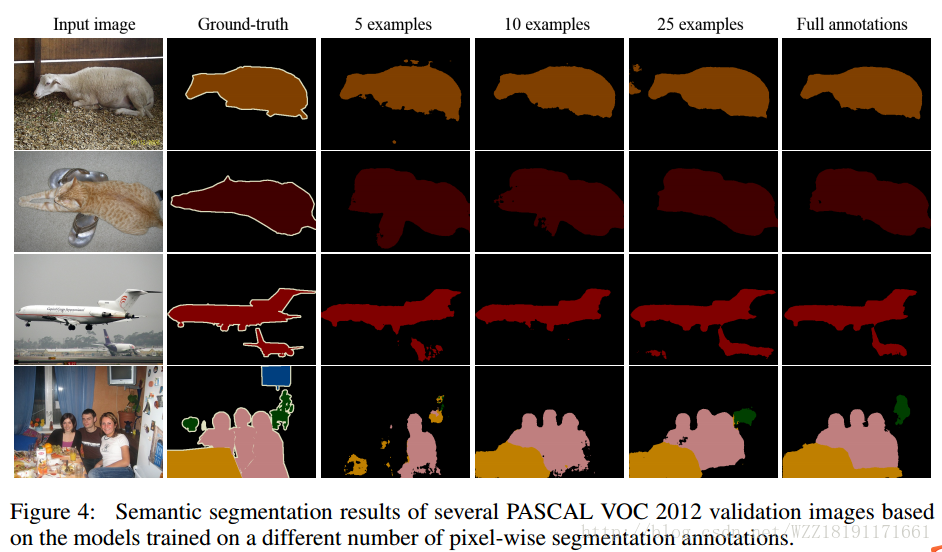
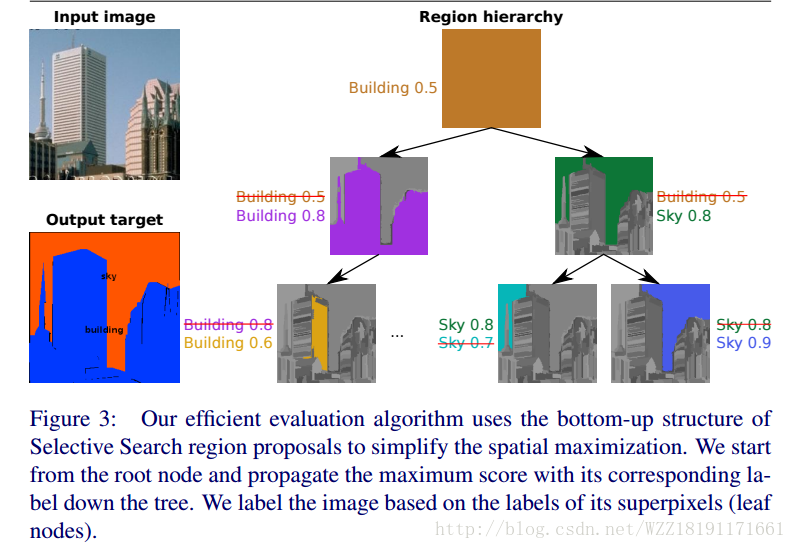
Learning Transferrable Knowledge for Semantic Segmentation with Deep Convolutional Neural Network:
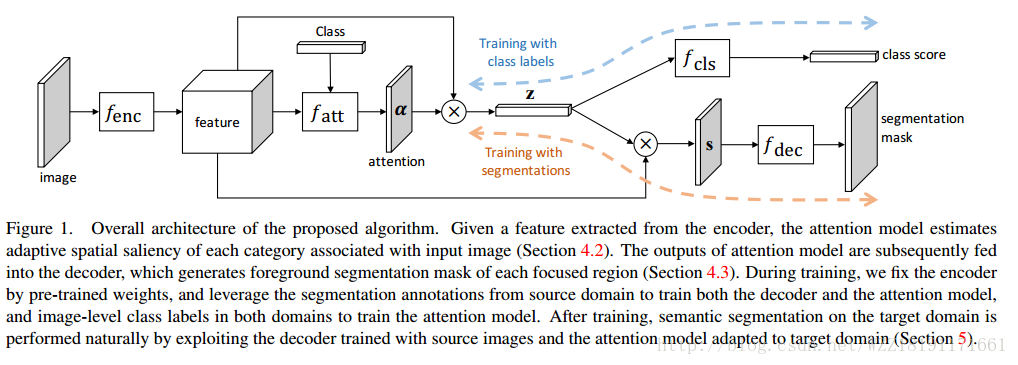
Feedforward Semantic Segmentation With Zoom-Out Features網路:
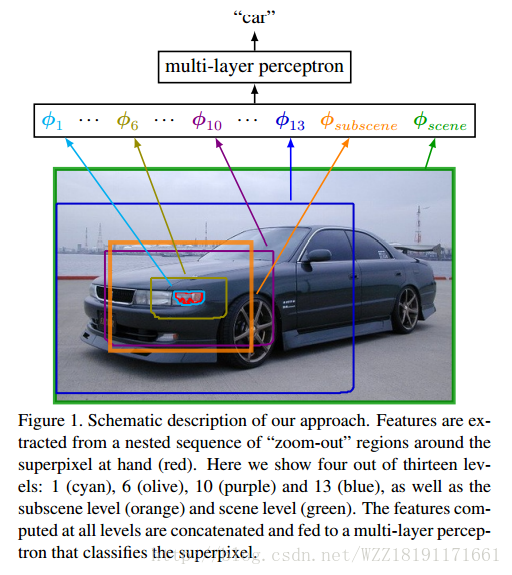

Joint Calibration for Semantic Segmentation:
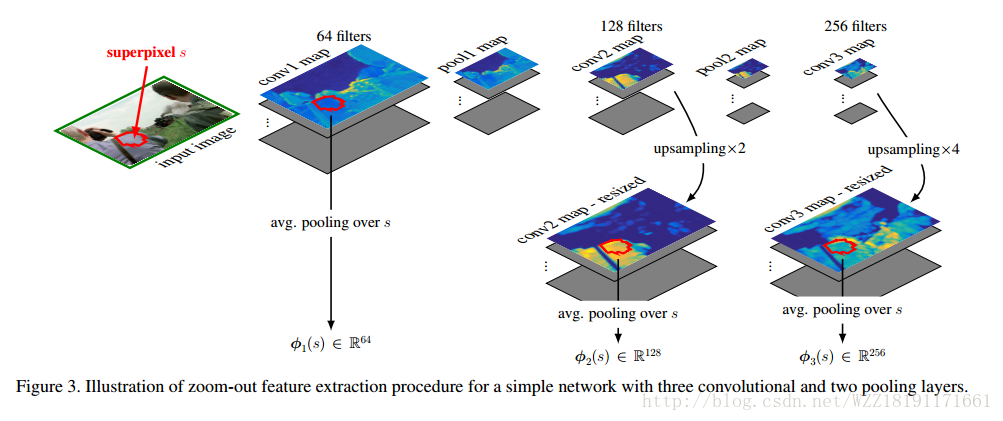
Hypercolumns for Object Segmentation and Fine-Grained Localization:
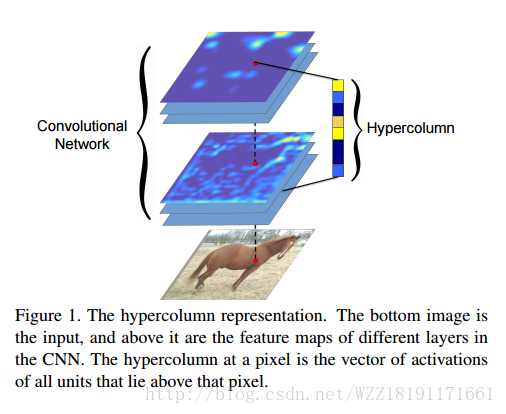
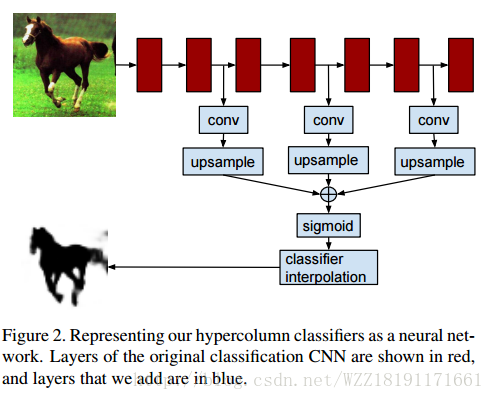
Learning Hierarchical Features for Scene Labeling:
MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS:
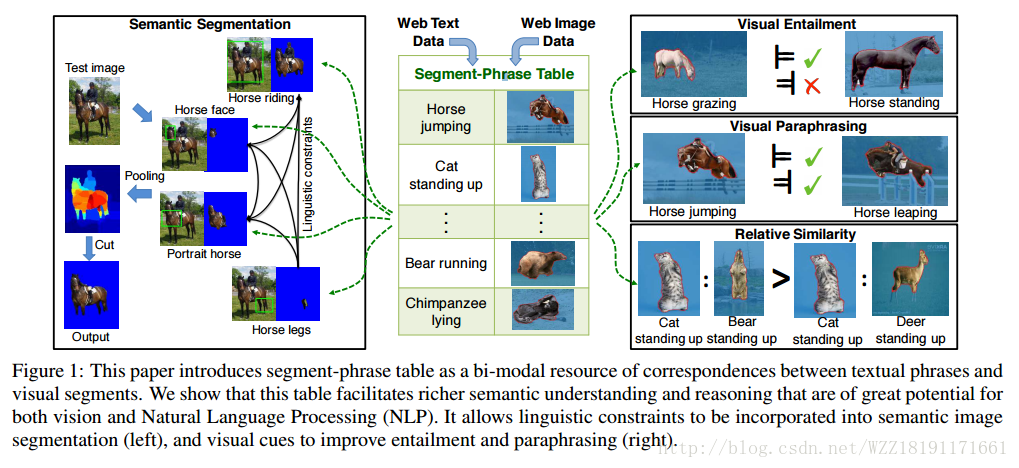
Segment-Phrase Table for Semantic Segmentation, Visual Entailment and Paraphrasing:
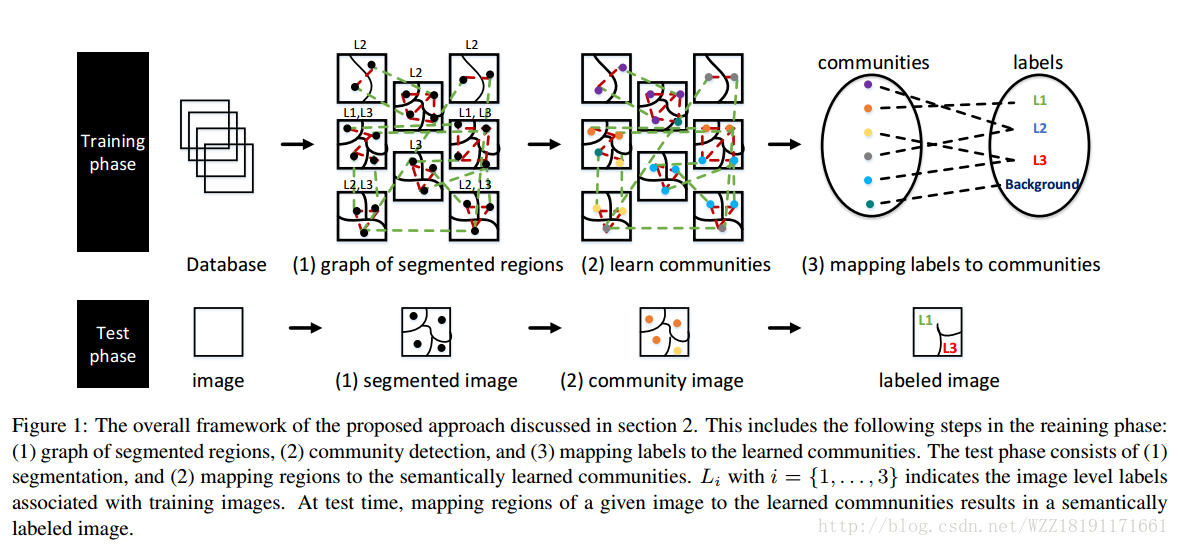
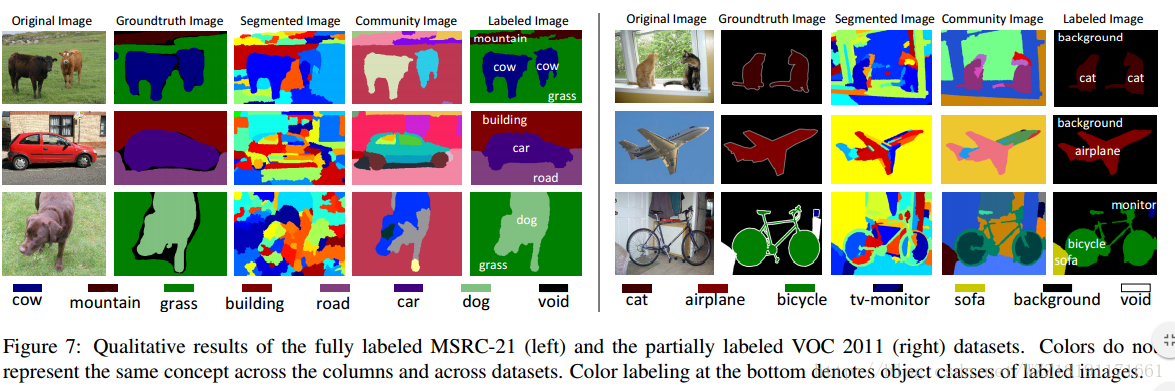
Weakly supervised graph based semantic segmentation by learning communities of image-parts:
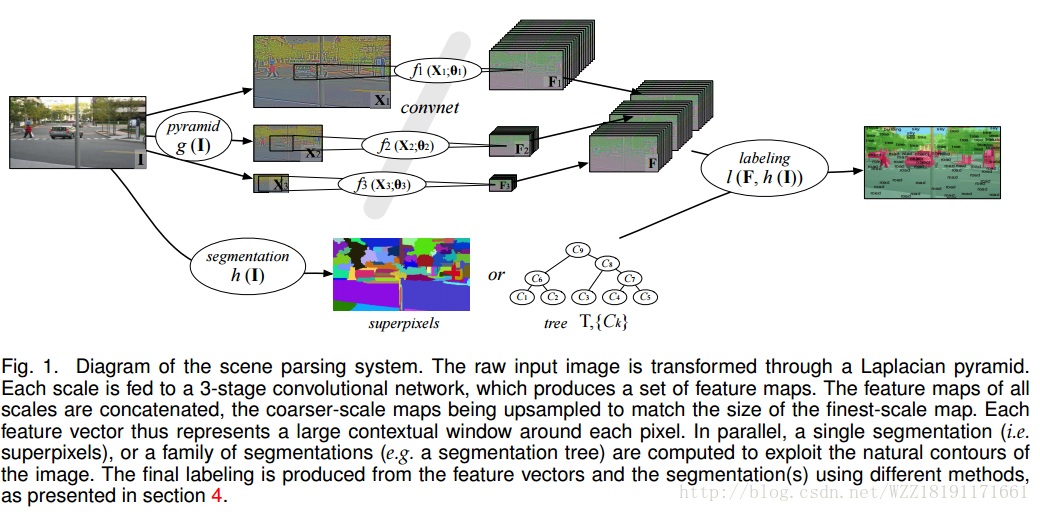
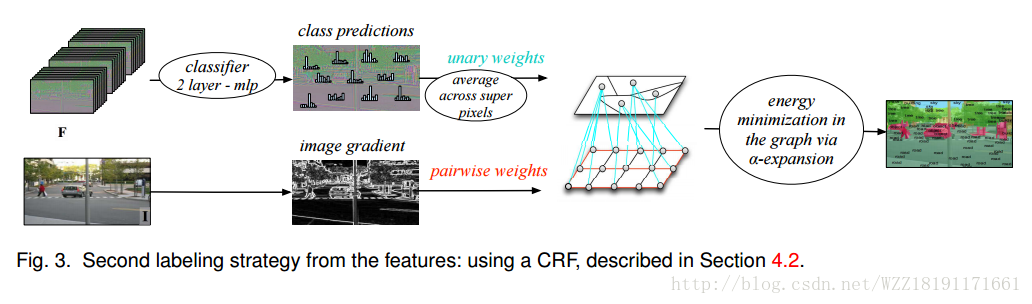
Scene Parsing with Multiscale Feature Learning:
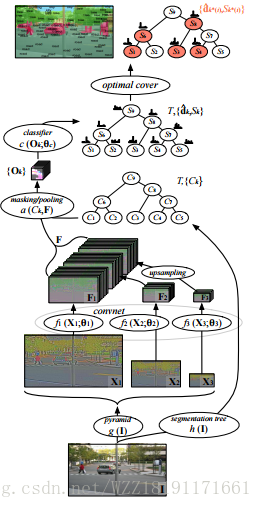

DLT網路:
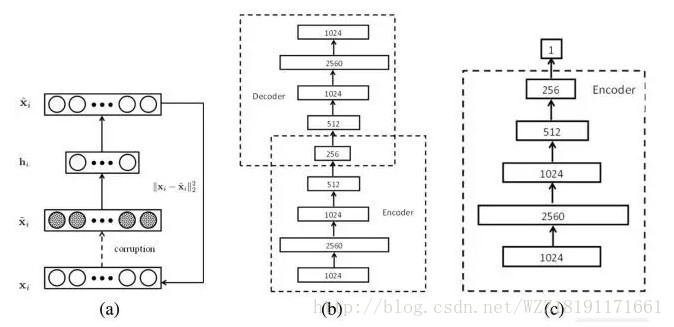
Transferring Rich Feature Hierarchies for Robust Visual Tracking網路:

FCNT網路:
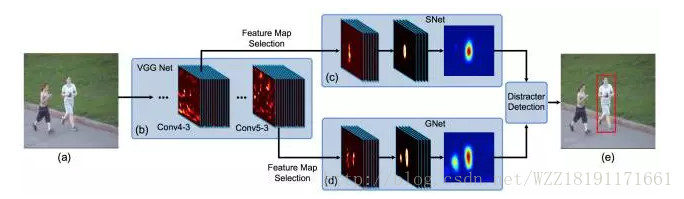
Hierarchical Convolutional Features for Visual Tracking網路:
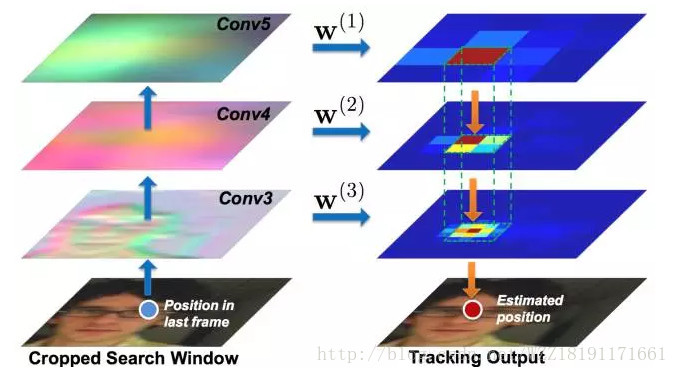
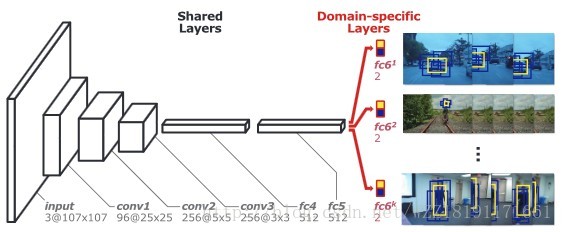
MDNet網路:
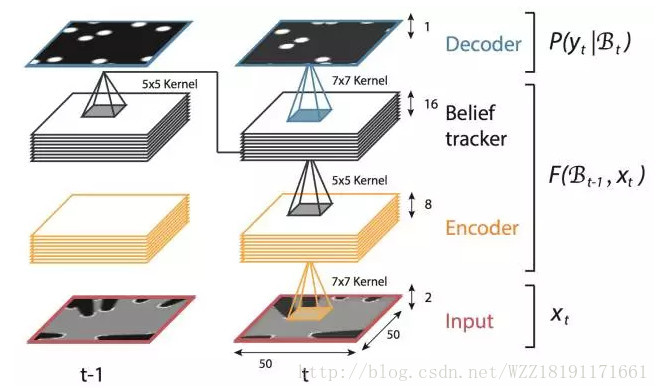
DeepTracking網路:
ecurrently Target-Attending Tracking網路:
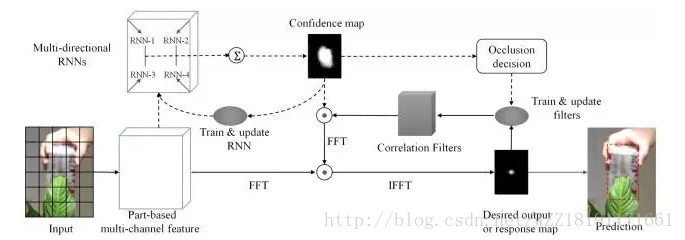
DeepTrack網路:
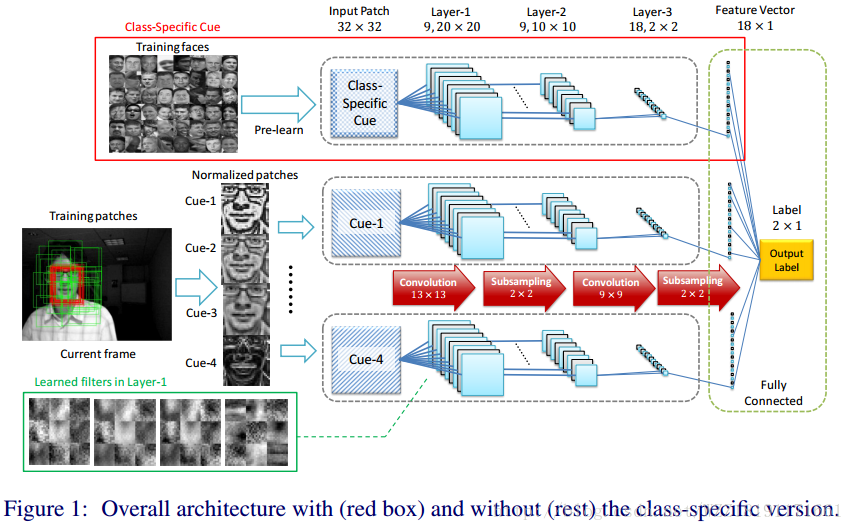
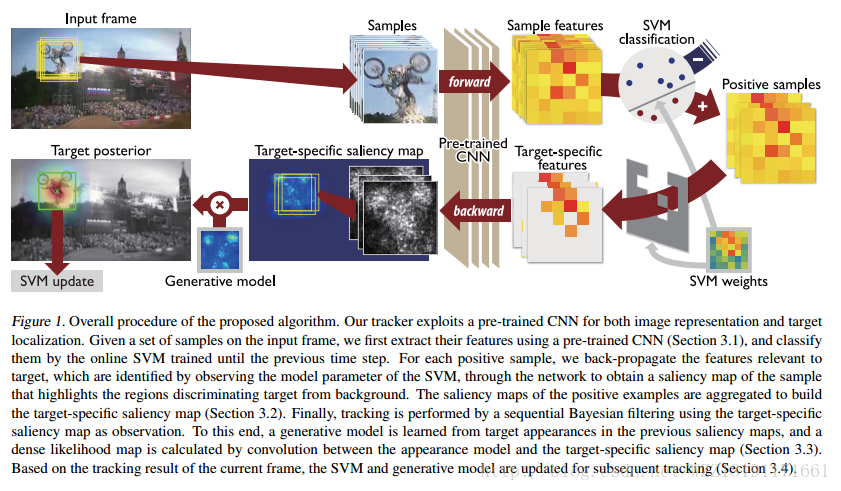
Online Tracking by Learning Discriminative Saliency Map
with Convolutional Neural Network:
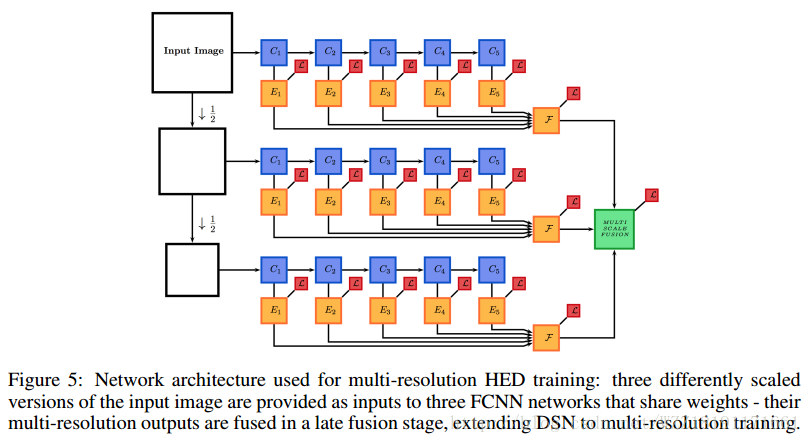
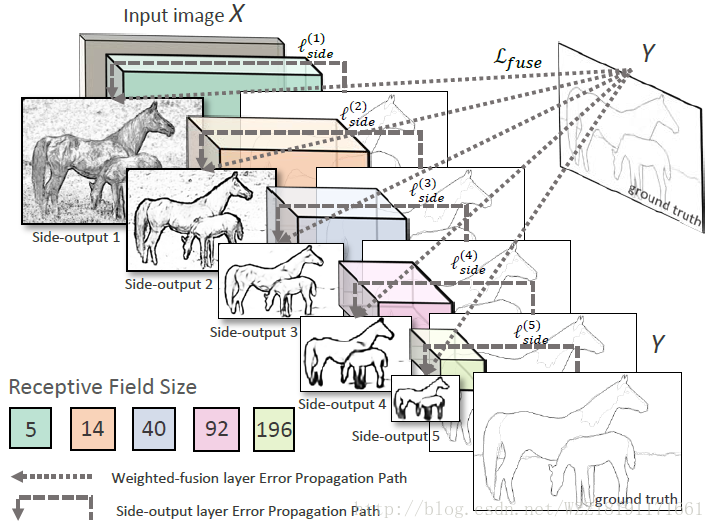
HED網路:
DeepEdge網路:

DeepContour網路:
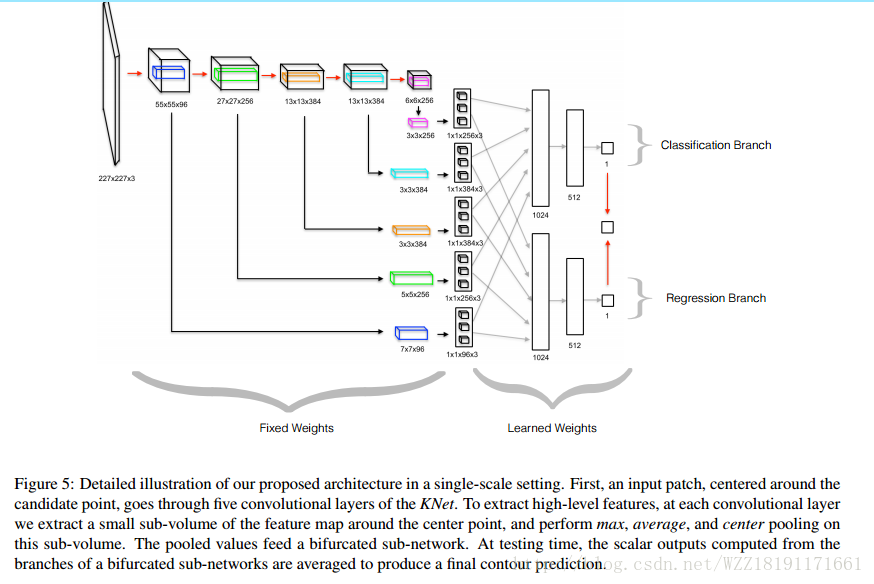
DeepPose網路:

JTCN網路:
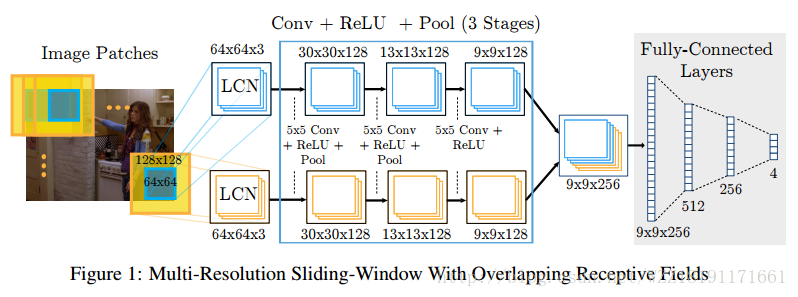
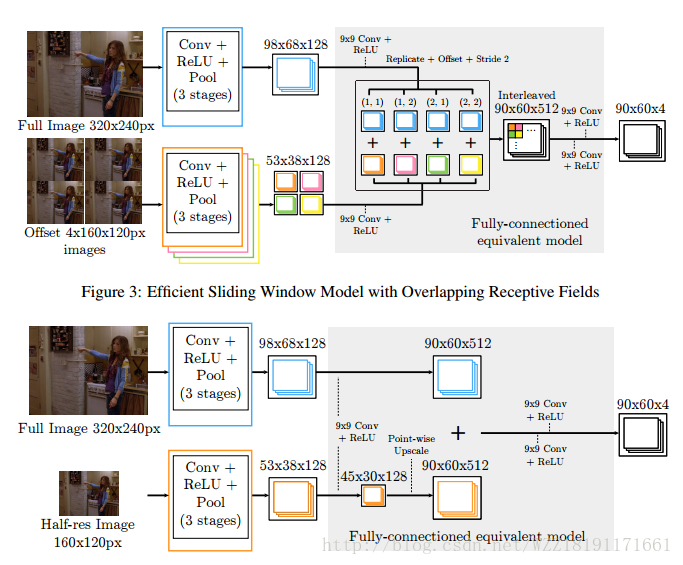
Flowing convnets for human pose estimation in videos網路:
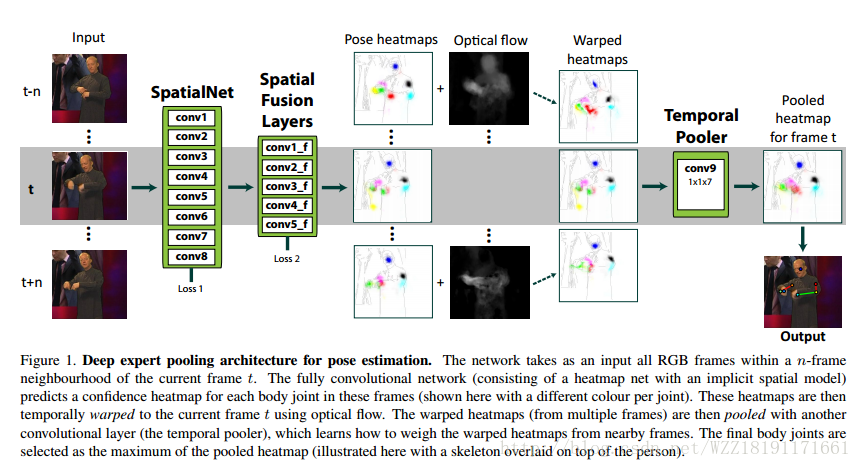
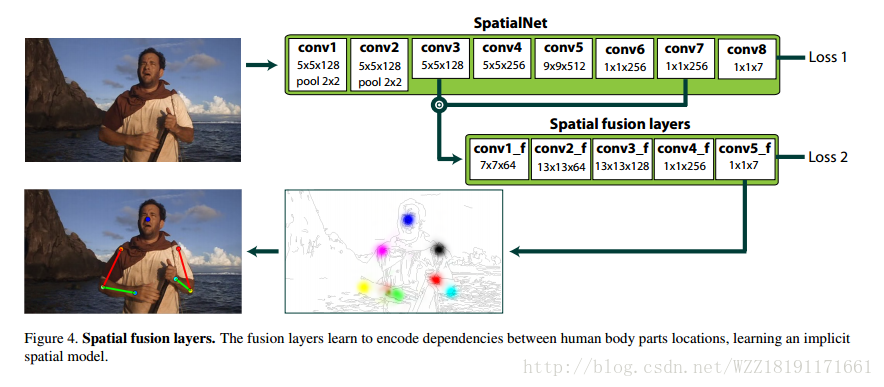
Stacked hourglass networks for human pose estimation網路:
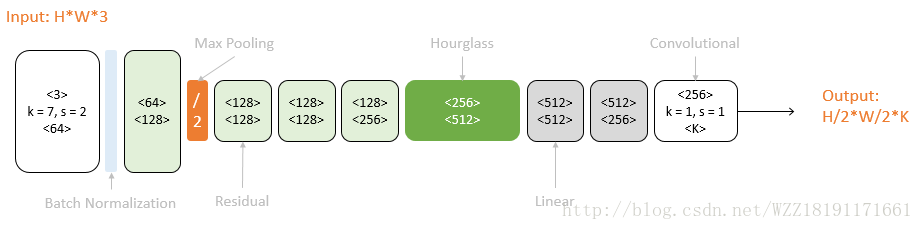
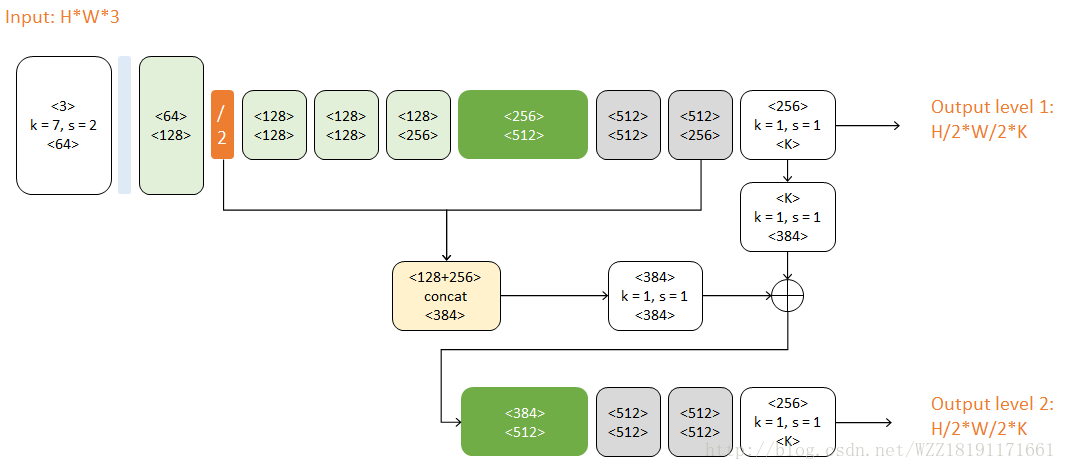
Convolutional pose machines網路:
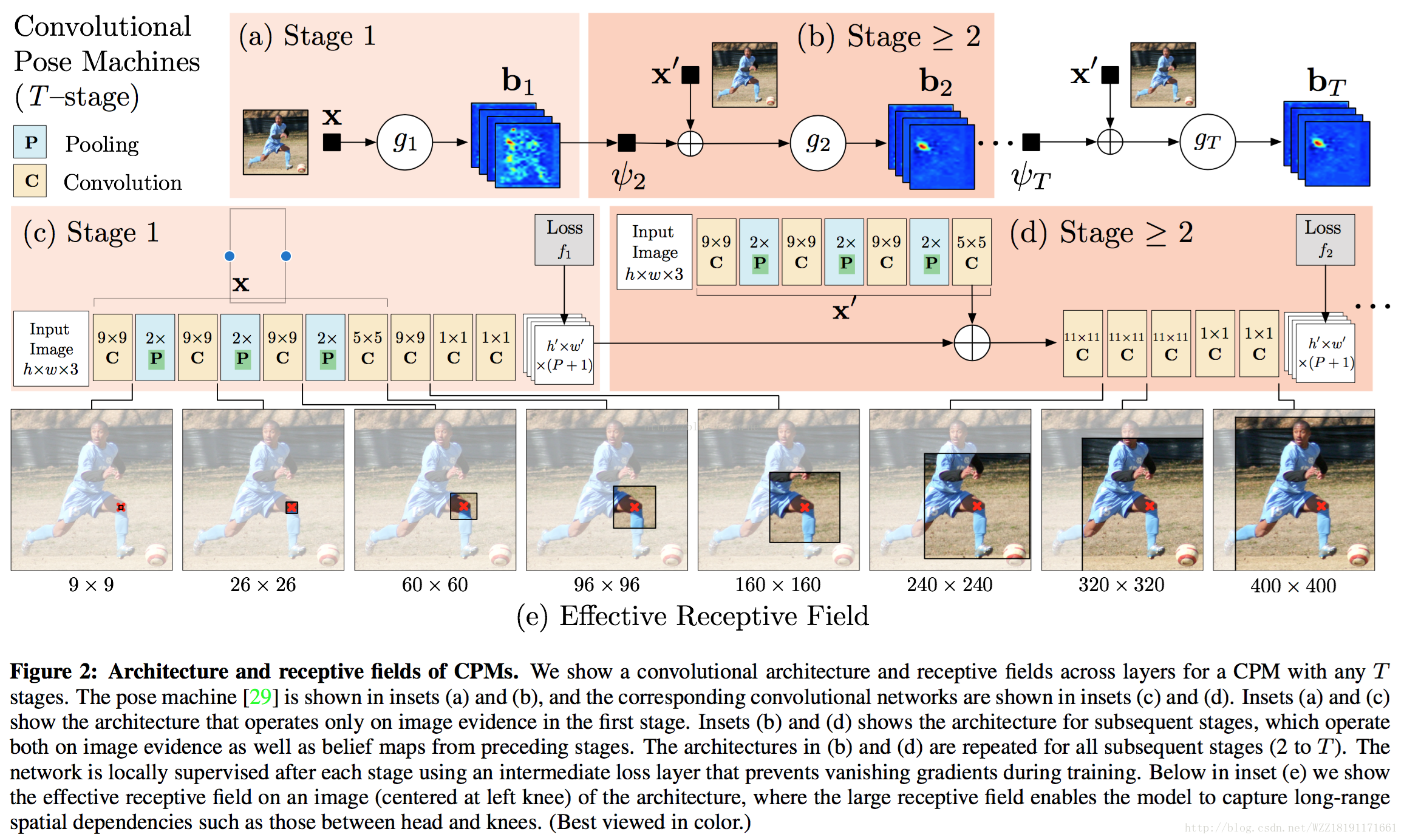
Deepcut網路:

Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields網路:
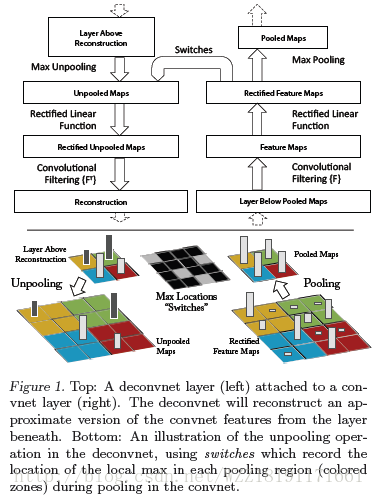
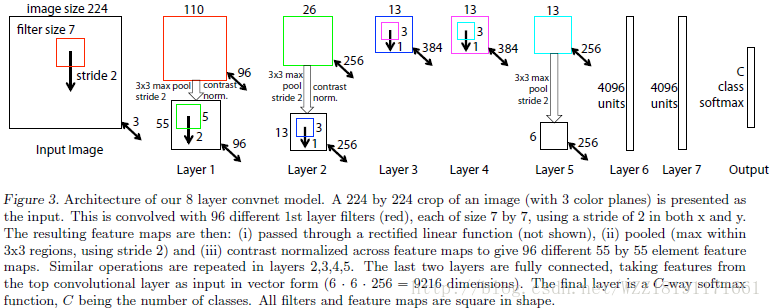
Visualizing and Understanding Convolutional Networks網路:
Inverting Visual Representations with Convolutional Networks:

Object Detectors Emerge in Deep Scene CNNs:

Understanding Deep Image Representations by Inverting Them:

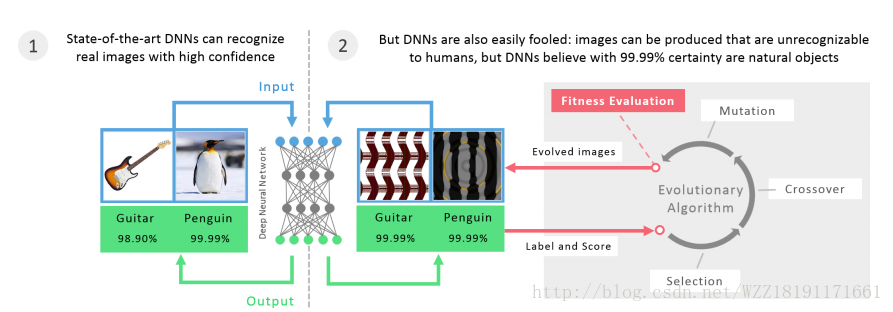
Deep Neural Networks are Easily Fooled:High Confidence Predictions for Unrecognizable Images:
Understanding image representations by measuring their equivariance and equivalence:

Learning Iterative Image Reconstruction網路:
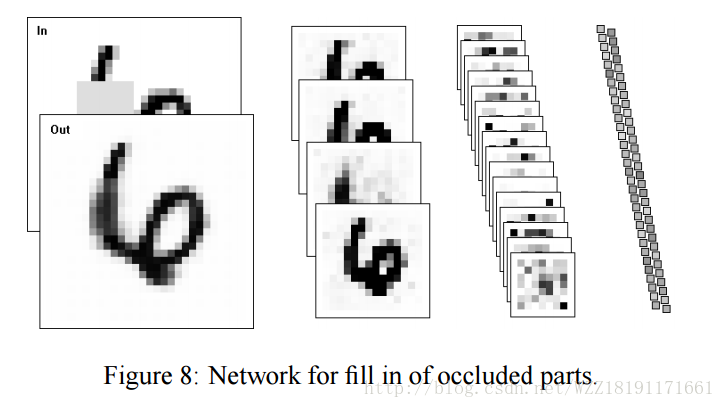
Learning Iterative Image Reconstruction in the Neural Abstraction Pyramid:

Learning a Deep Convolutional Network for Image Super-Resolution:
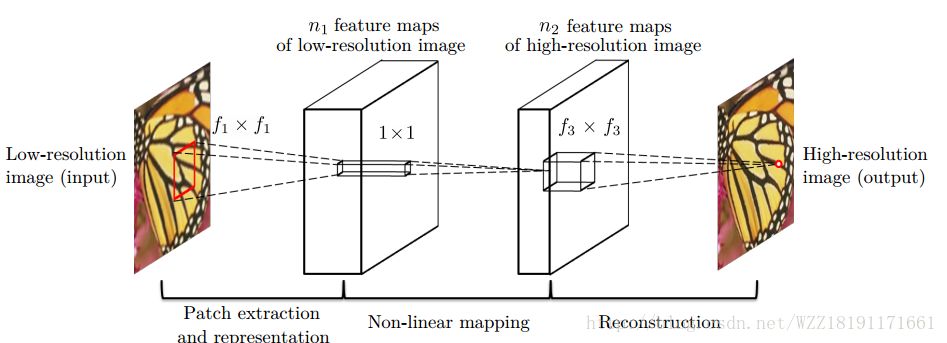
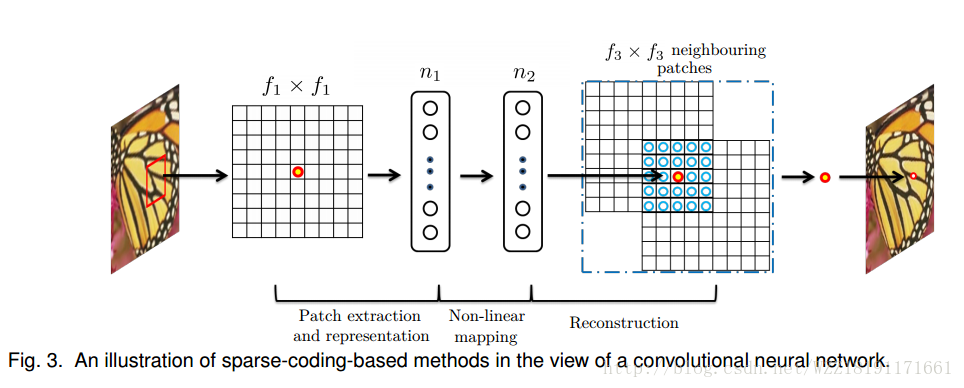
Image Super-Resolution Using Deep Convolutional Networks:
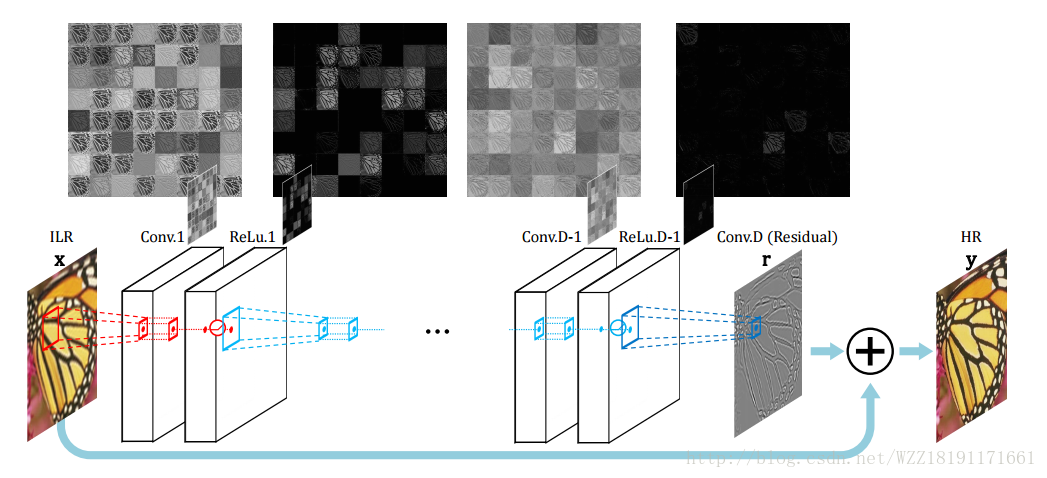
Accurate Image Super-Resolution Using Very Deep Convolutional Networks:
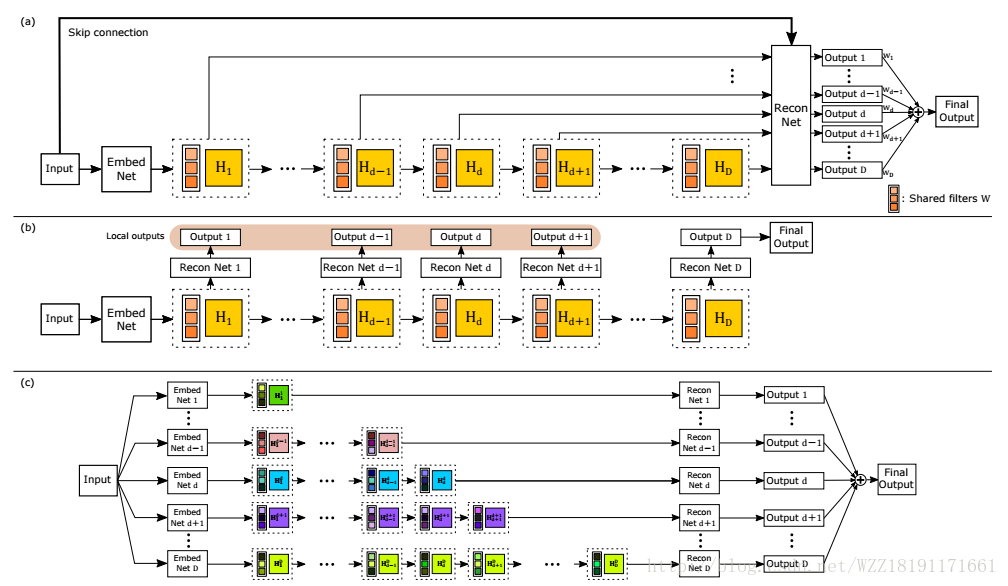
Deeply-Recursive Convolutional Network for Image Super-Resolution:
Deep Networks for Image Super-Resolution with Sparse Prior:
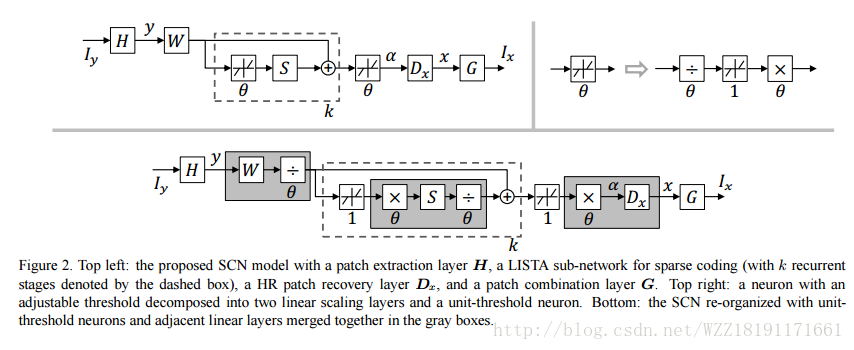
Perceptual Losses for Real-Time Style Transfer and Super-Resolution:
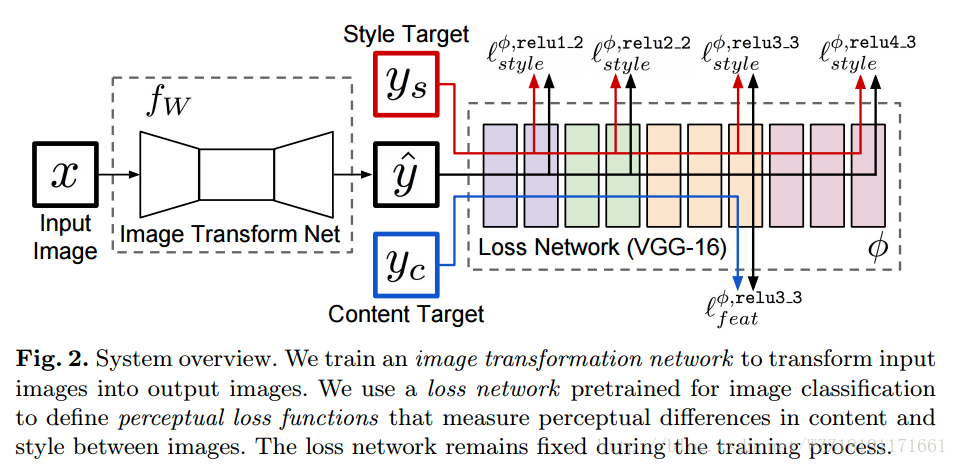
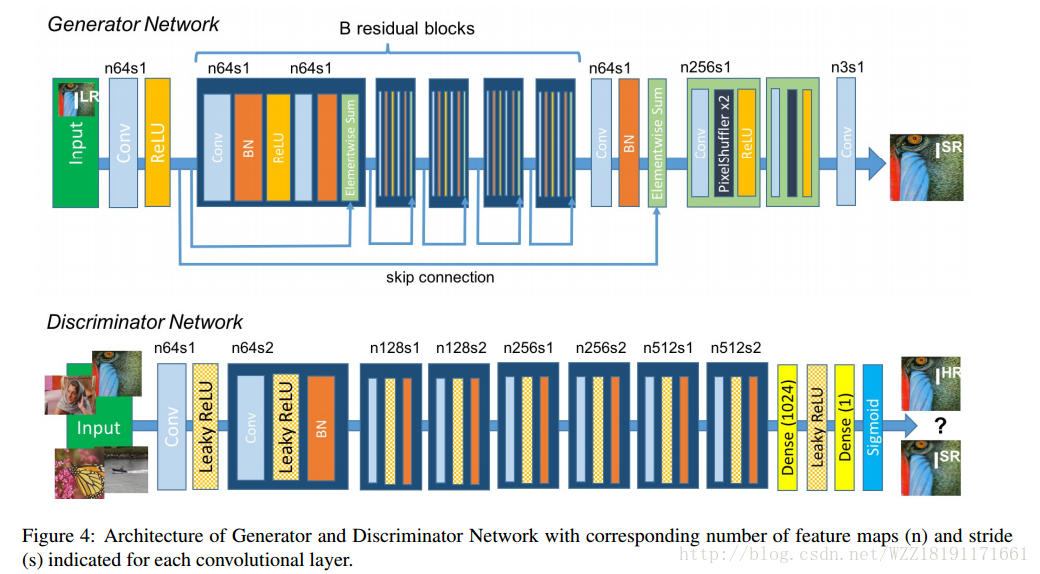
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network:
Explain Images with Multimodal Recurrent Neural Networks:
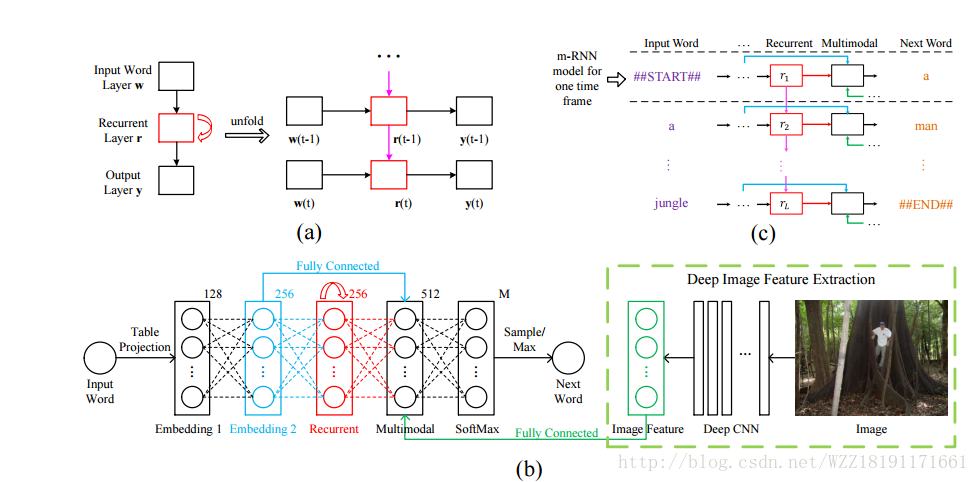
Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models:
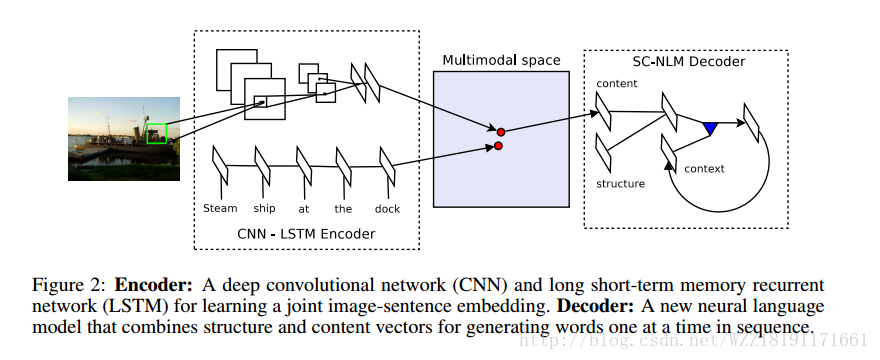
Long-term Recurrent Convolutional Networks for Visual Recognition and Description:
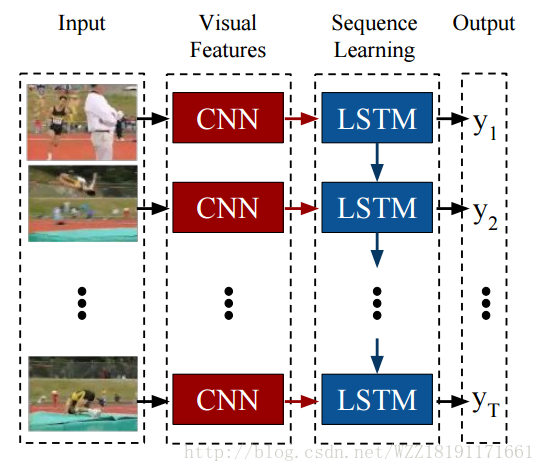
A Neural Image Caption Generator:
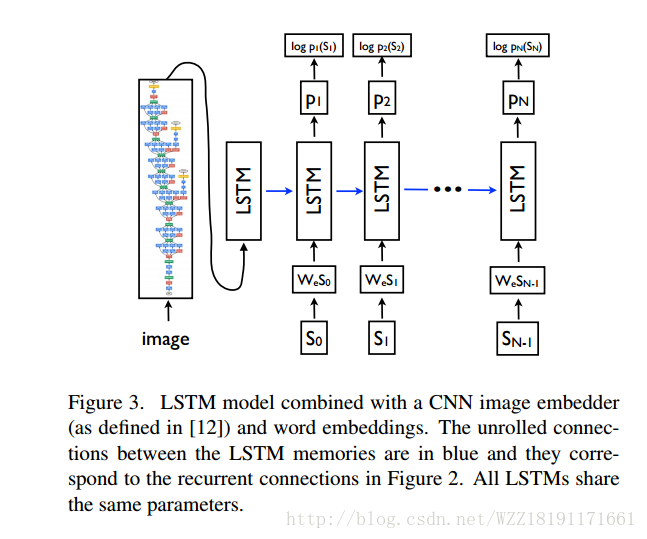
Deep Visual-Semantic Alignments for Generating Image Description:

Translating Videos to Natural Language Using Deep Recurrent Neural Networks:
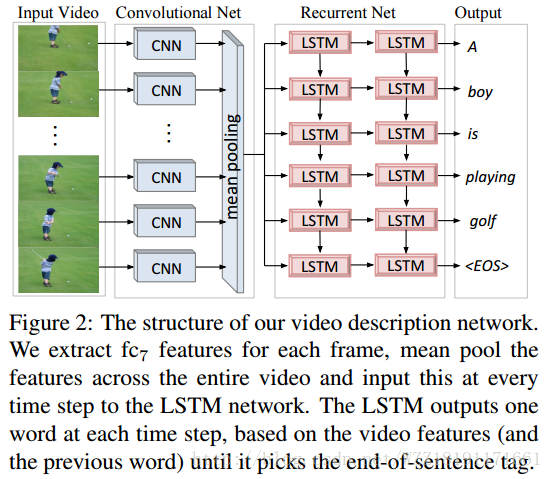
Learning a Recurrent Visual Representation for Image Caption Generation:

From Captions to Visual Concepts and Back:
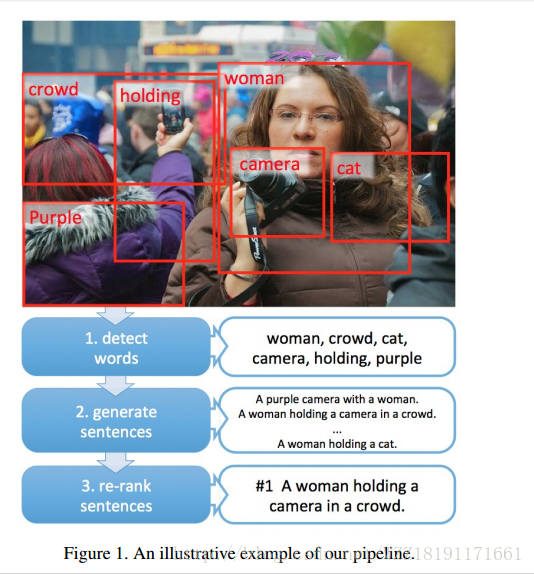
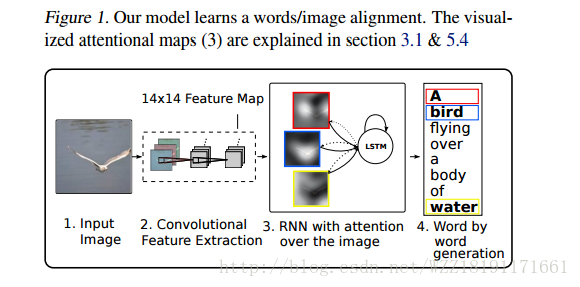
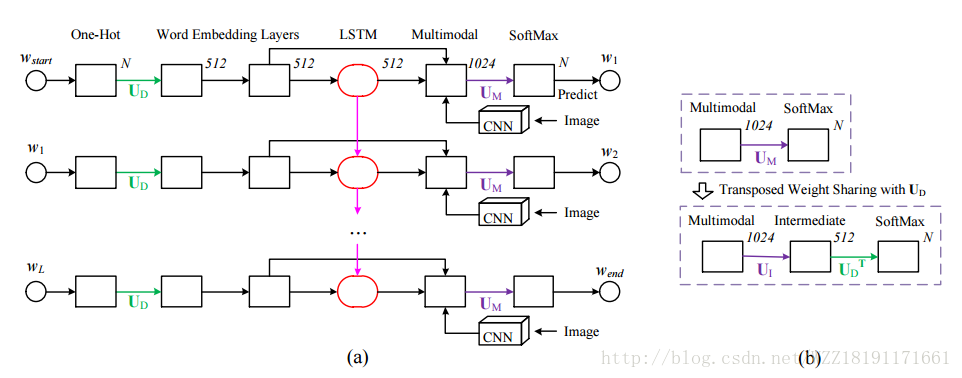
Show, Attend, and Tell: Neural Image Caption Generation with Visual Attention:
Phrase-based Image Captioning:

Learning like a Child: Fast Novel Visual Concept Learning from Sentence Descriptions of Images:
Exploring Nearest Neighbor Approaches for Image Captioning:
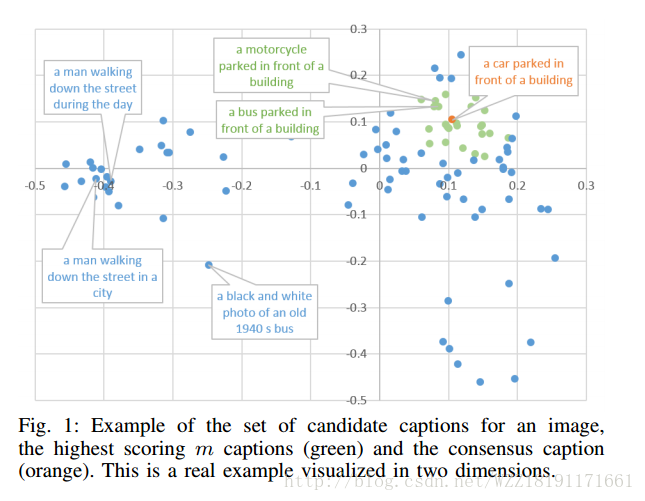
Image Captioning with an Intermediate Attributes Layer:
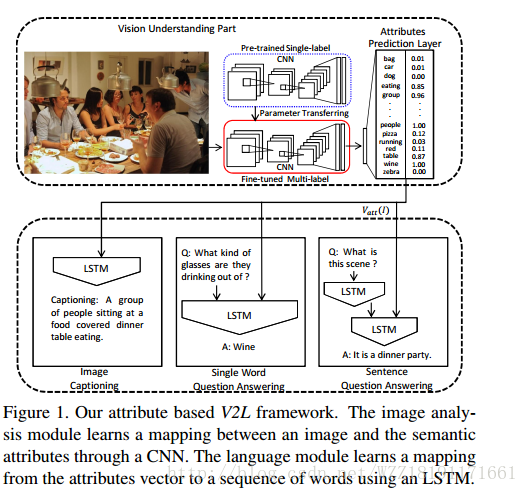
Learning language through pictures:

Describing Multimedia Content using Attention-based Encoder-Decoder Networks:
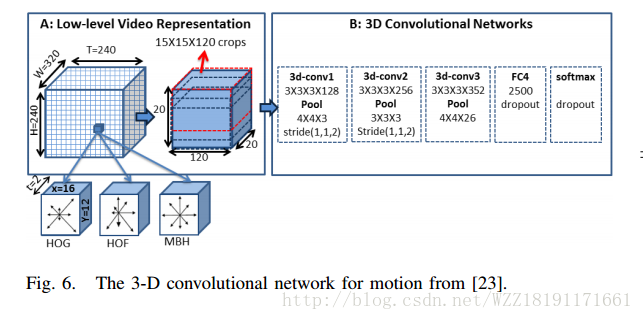
Image Representations and New Domains in Neural Image Captioning:

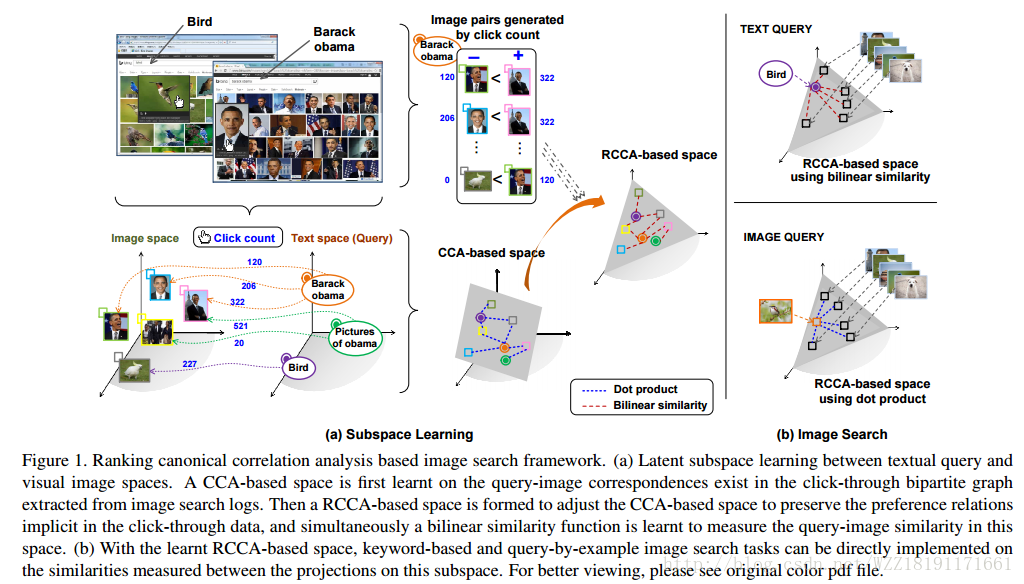
Learning Query and Image Similarities with Ranking Canonical Correlation Analysis:
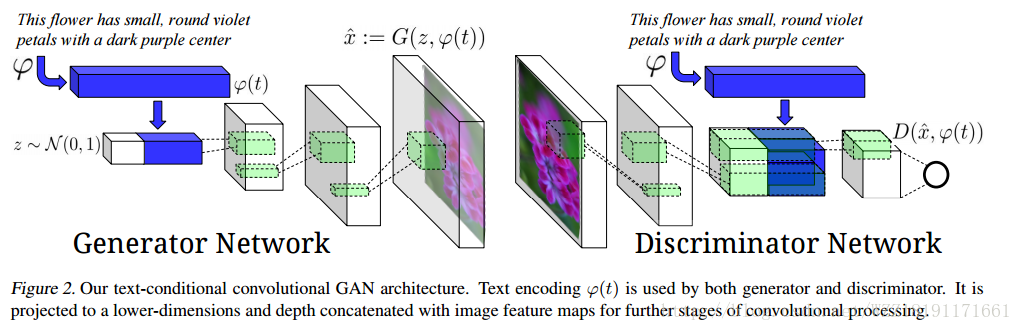
Generative Adversarial Text to Image Synthesis:
GENERATING IMAGES FROM CAPTIONS WITH ATTENTION:
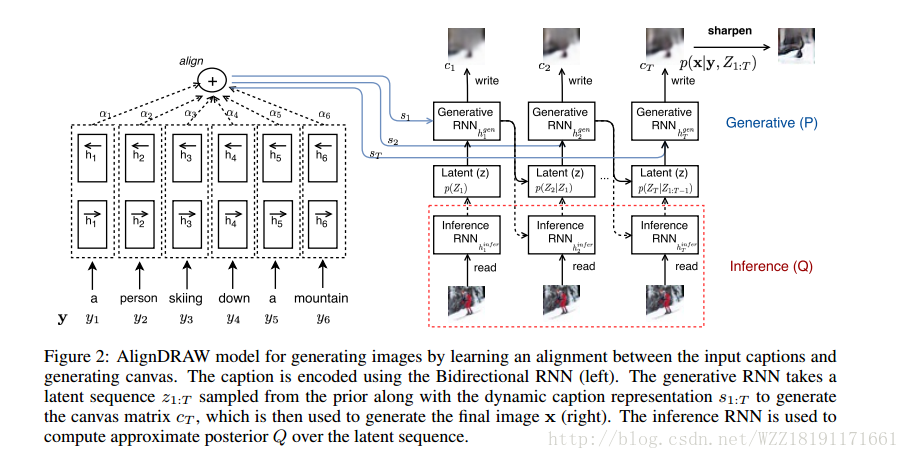
Long-term Recurrent Convolutional Networks for Visual Recognition and Description:

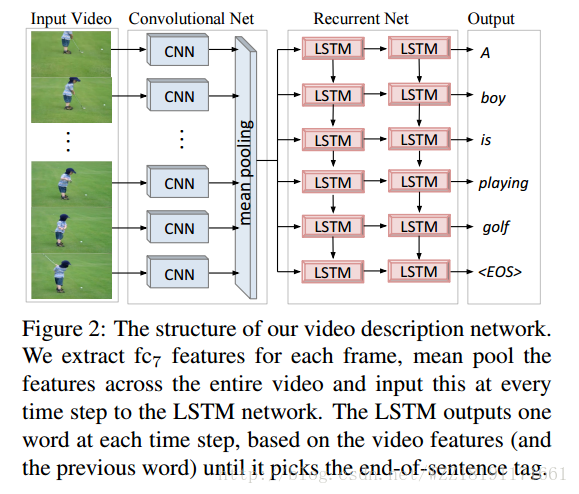
Translating Videos to Natural Language Using Deep Recurrent Neural Networks:
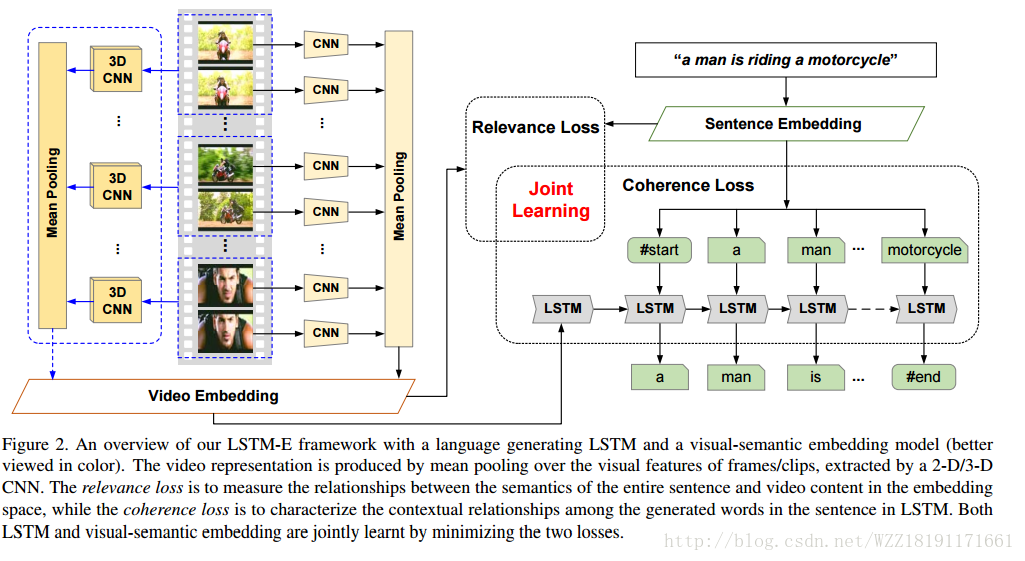
Joint Modeling Embedding and Translation to Bridge Video and Language:
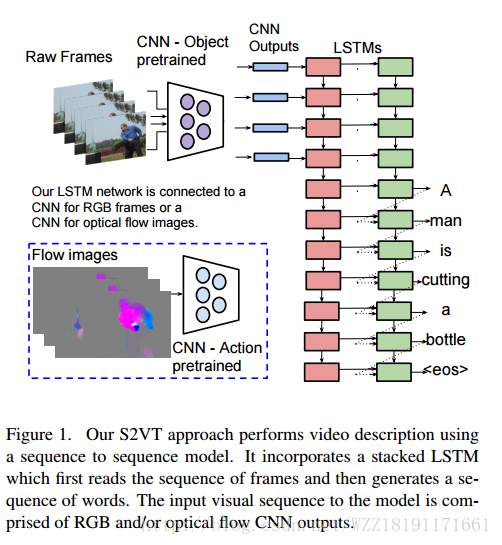
Sequence to Sequence–Video to Text:
Describing Videos by Exploiting Temporal Structure:
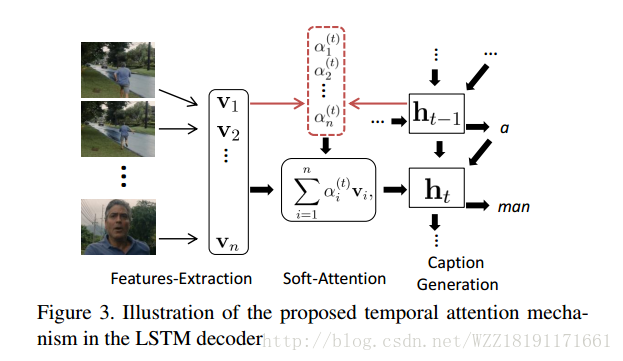
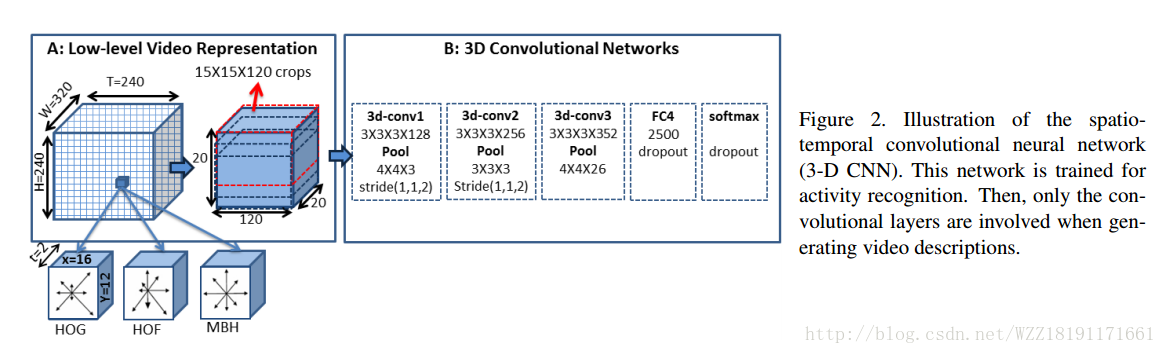
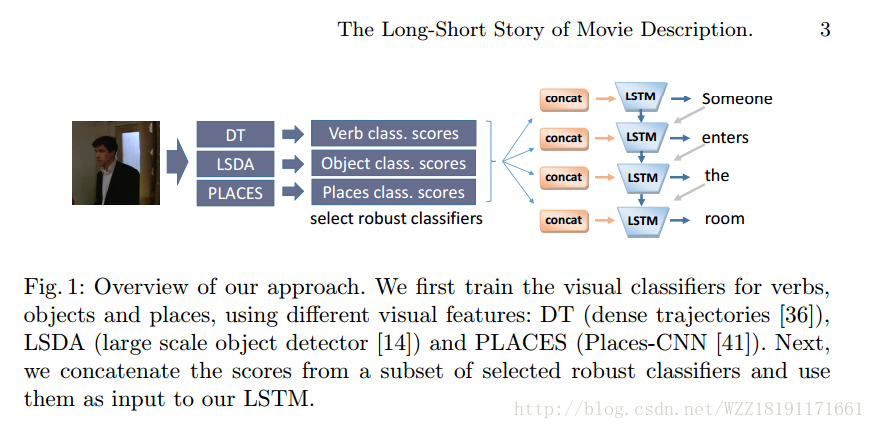
The Long-Short Story of Movie Description:
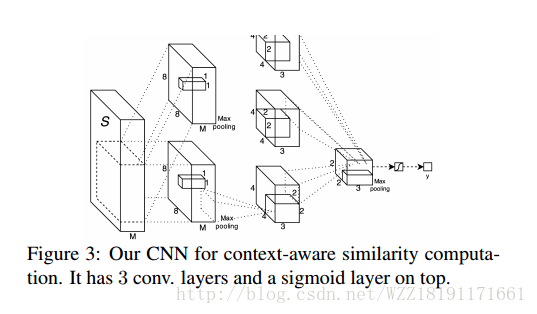
Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books:
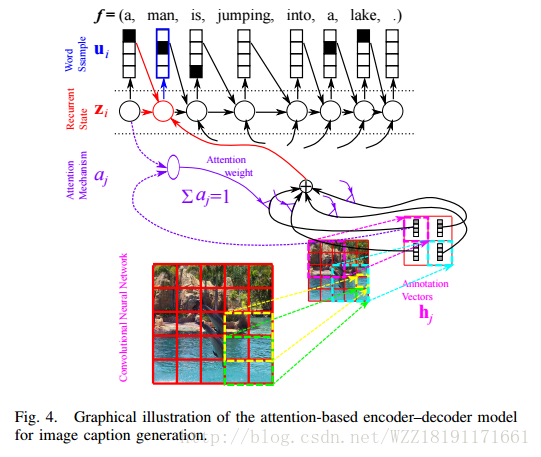
Describing Multimedia Content using Attention-based Encoder-Decoder Networks:
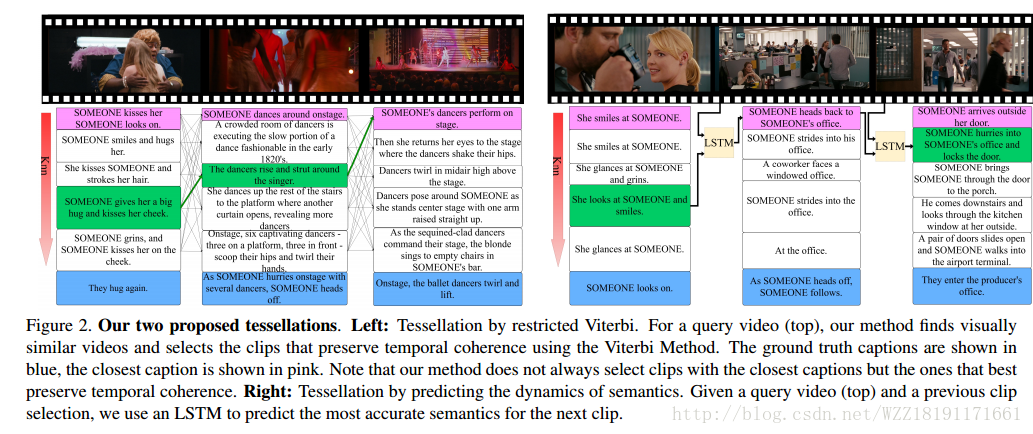
Temporal Tessellation for Video Annotation and Summarization:
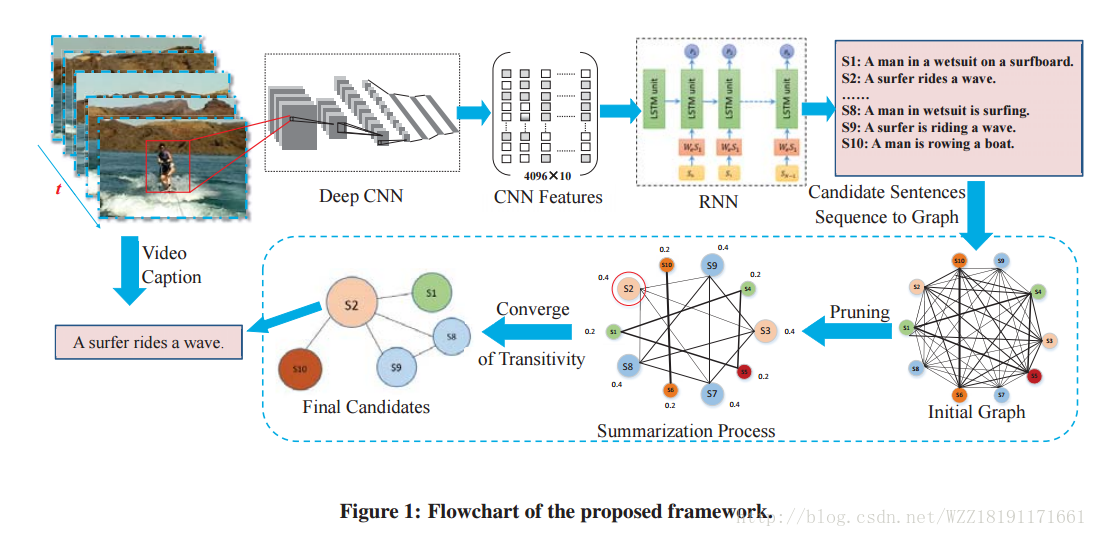
Summarization-based Video Caption via Deep Neural Networks:
Deep Learning for Video Classification and Captioning:
問答系統
經典模型:
Ask Your Neurons: A Neural-based Approach to Answering Questions about Images
https://arxiv.org/pdf/1505.01121.pdfImage Question Answering: A Visual Semantic Embedding Model and a New Dataset
https://arxiv.org/pdf/1505.02074.pdfDataset and Methods for Multilingual Image Question Answering
https://arxiv.org/pdf/1505.05612.pdfImage Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction
Dynamic Memory Networks for Visual and Textual Question Answering
https://arxiv.org/pdf/1603.01417v1.pdfMultimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding
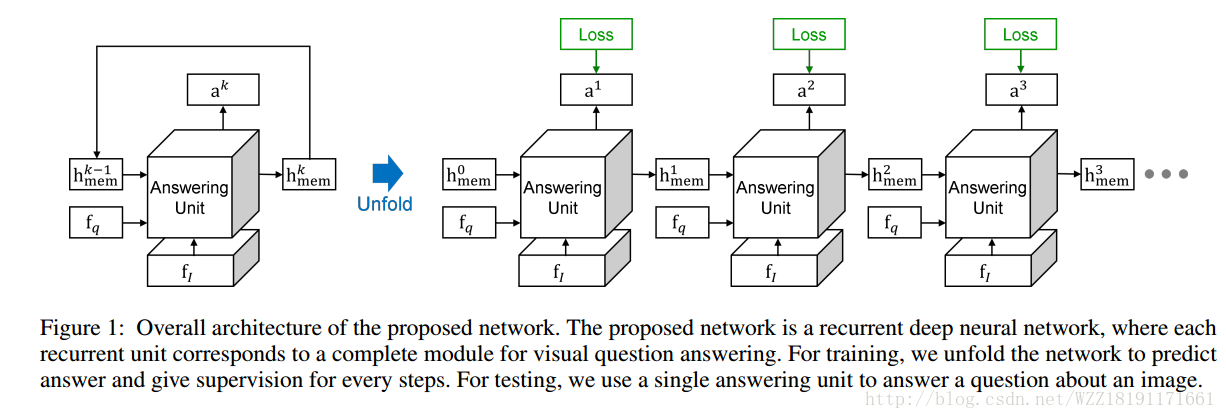
https://arxiv.org/pdf/1606.01847.pdfTraining Recurrent Answering Units with Joint Loss Minimization for VQA
https://arxiv.org/pdf/1606.03647.pdf
VQA: Visual Question Answering:
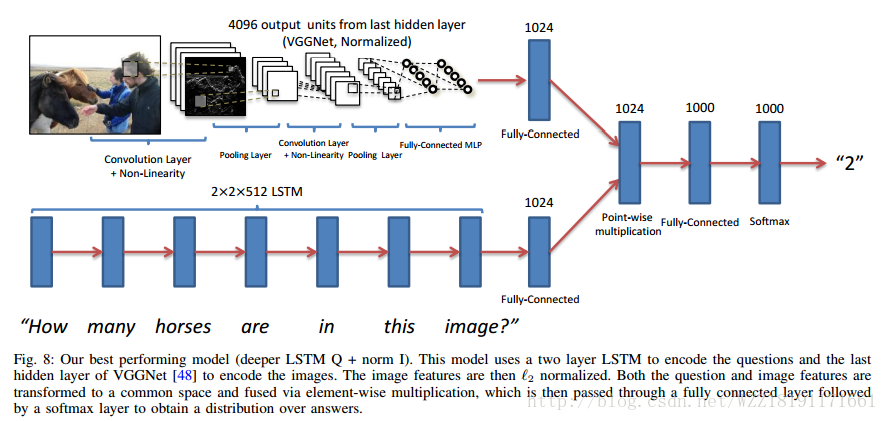
Ask Your Neurons: A Neural-based Approach to Answering Questions about Images:
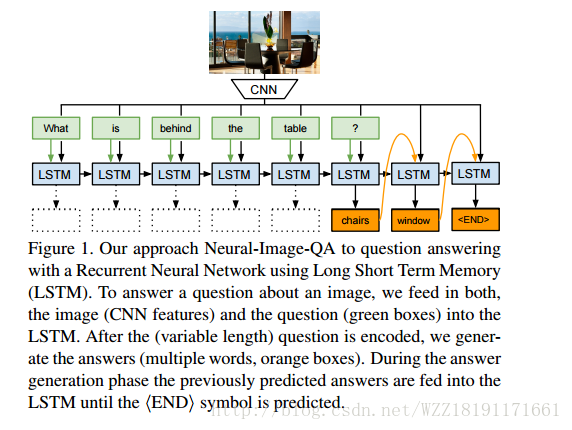
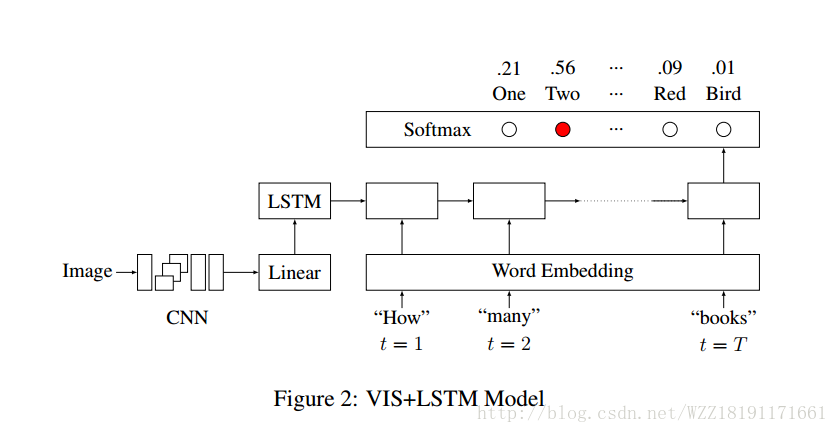
Image Question Answering: A Visual Semantic Embedding Model and a New Dataset:
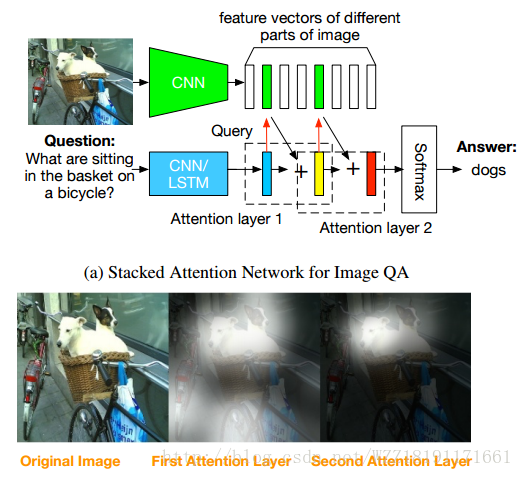
Stacked Attention Networks for Image Question Answering:
Dataset and Methods for Multilingual Image Question Answering:
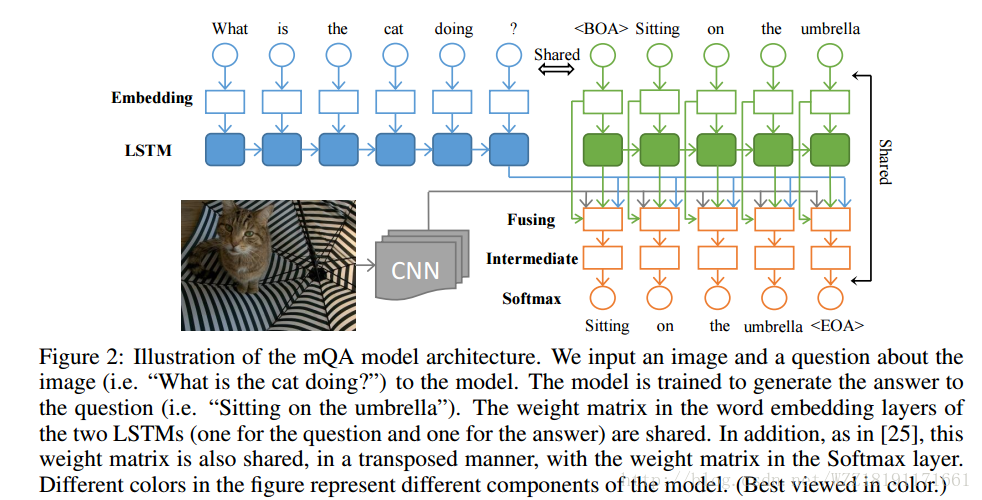
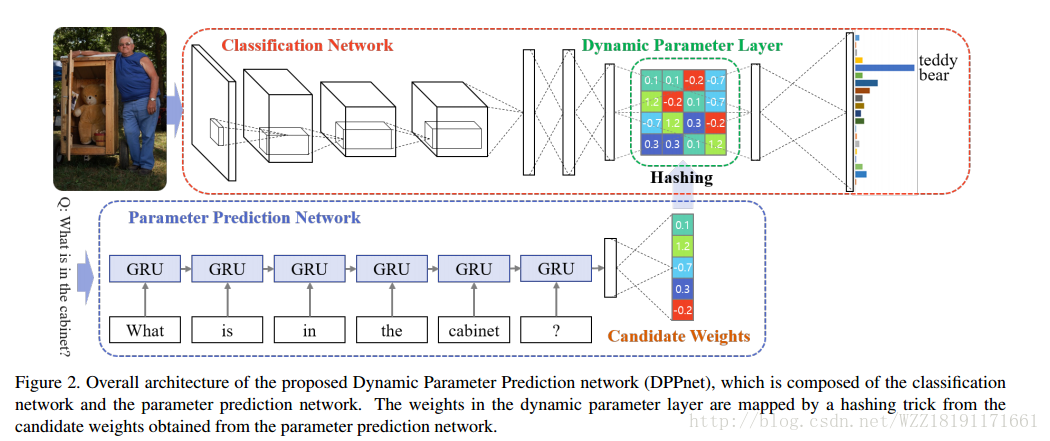
Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction:
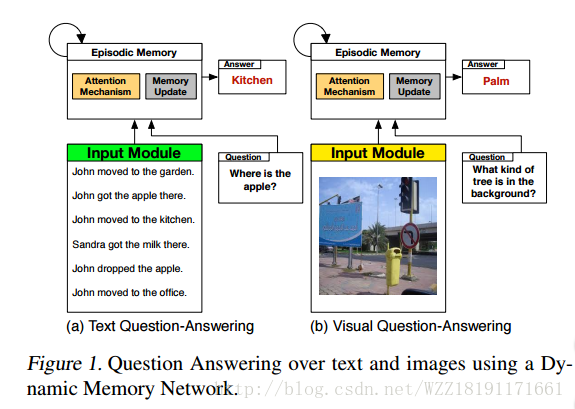
Dynamic Memory Networks for Visual and Textual Question Answering:
Multimodal Residual Learning for Visual QA:
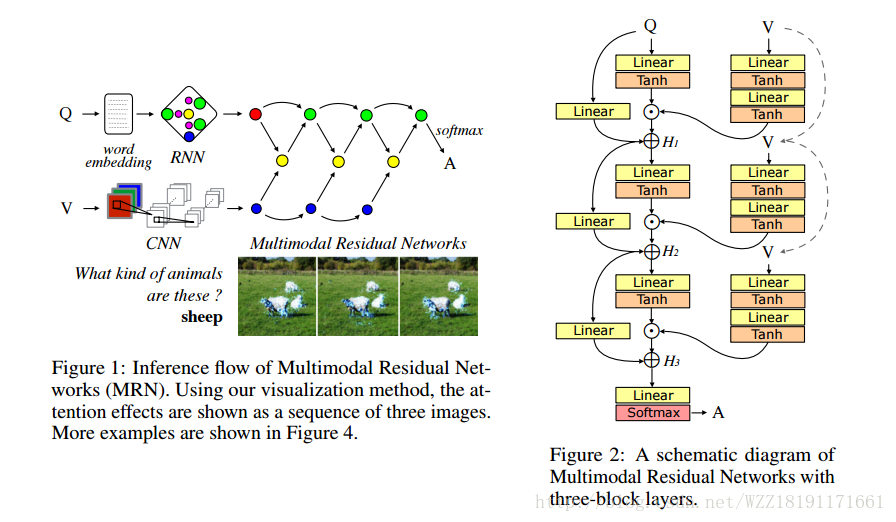
Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding:
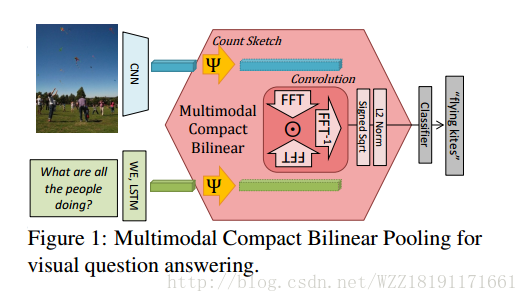
Training Recurrent Answering Units with Joint Loss Minimization for VQA:
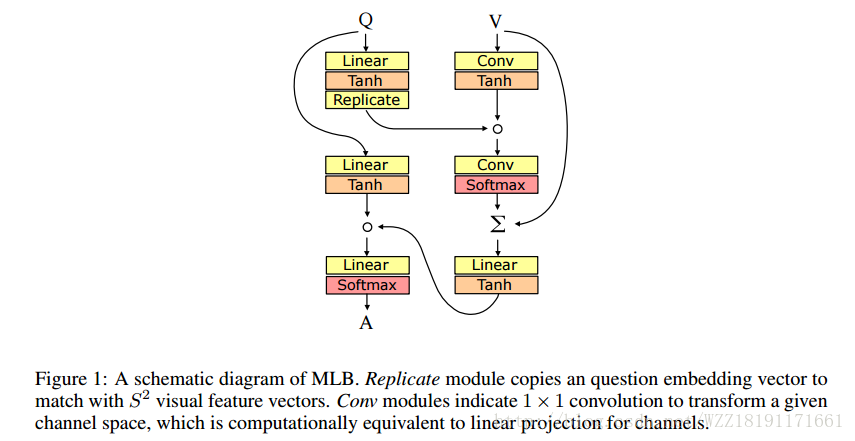
Hadamard Product for Low-rank Bilinear Pooling:
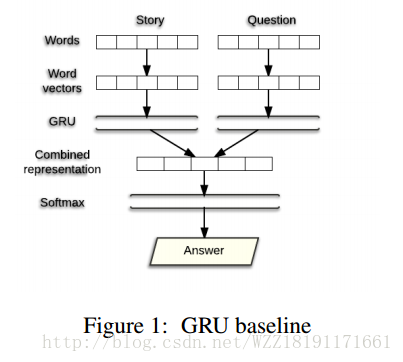
Question Answering Using Deep Learning:
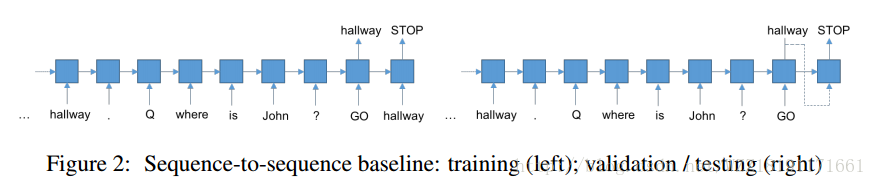
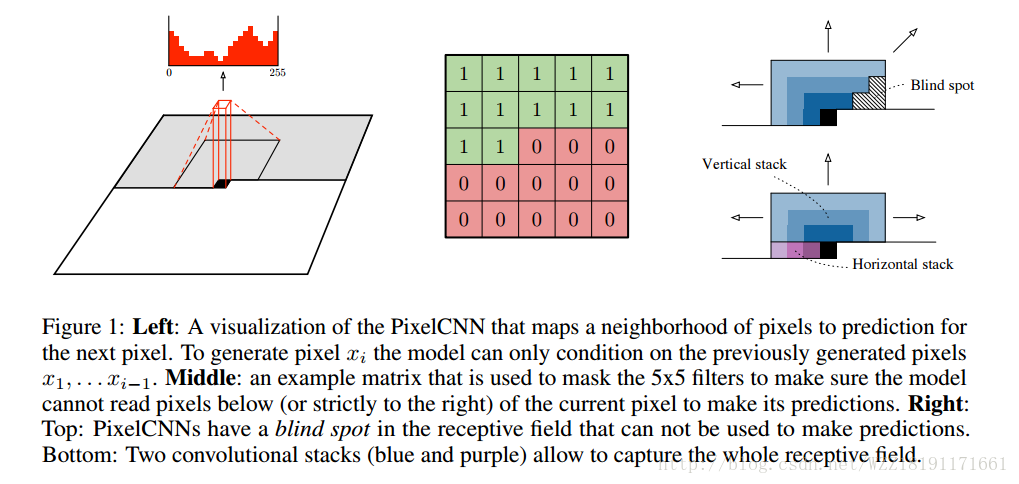
Conditional Image Generation with PixelCNN Decoders:
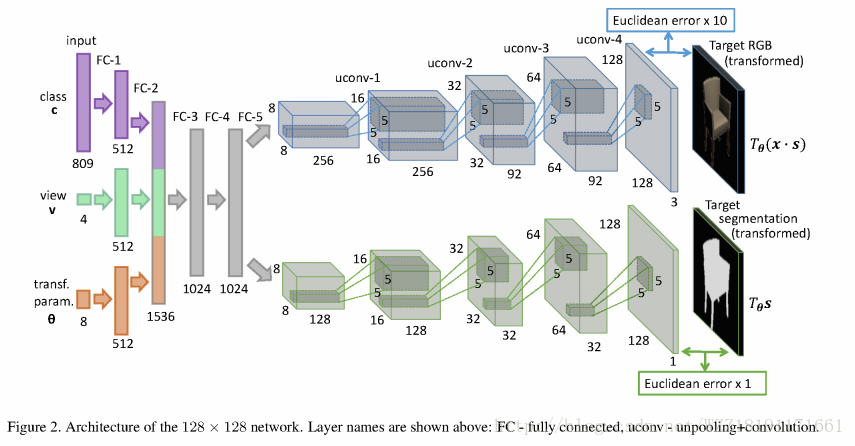
Learning to Generate Chairs with Convolutional Neural Networks:
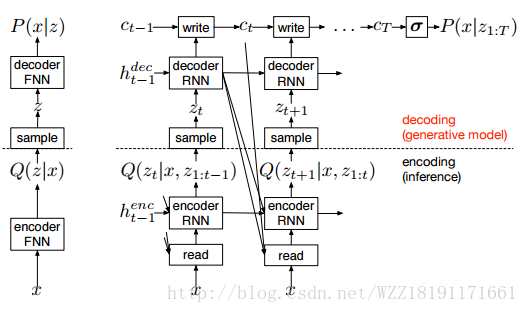
DRAW: A Recurrent Neural Network For Image Generation:

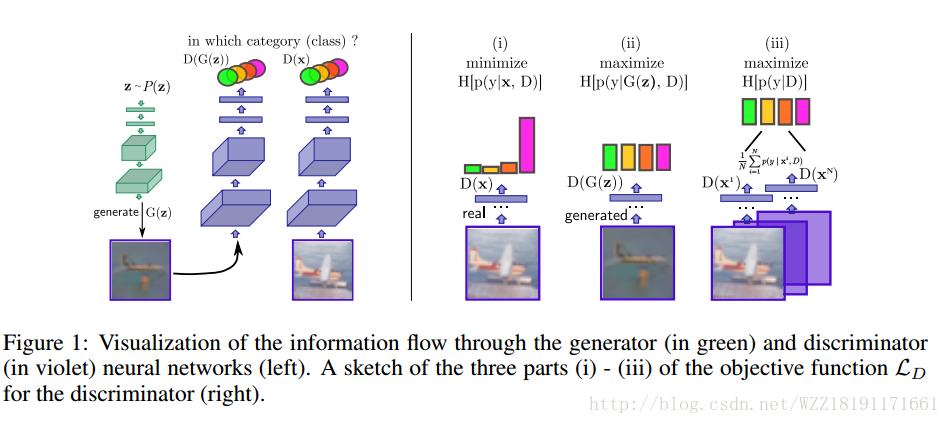
Generative Adversarial Networks:
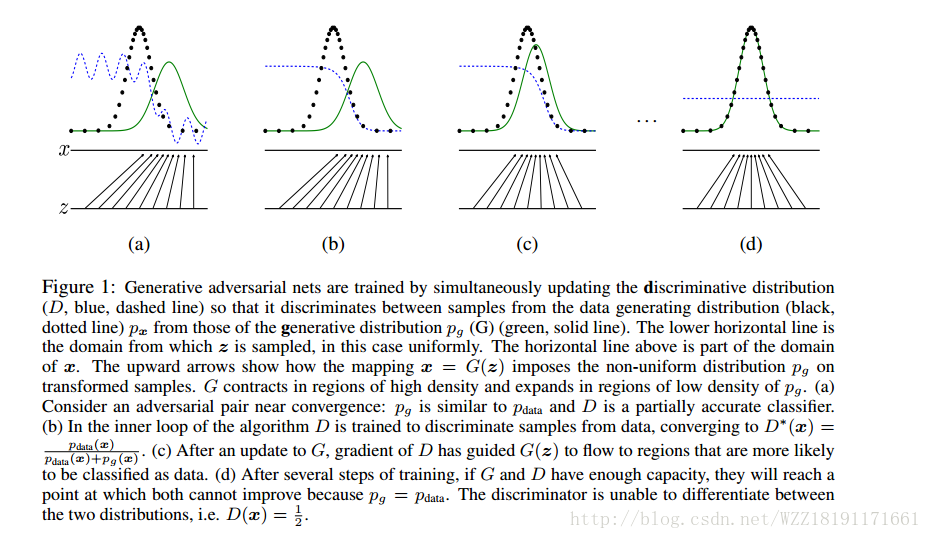
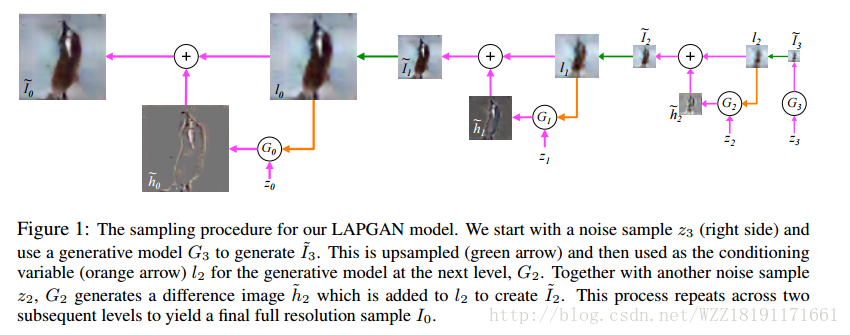
Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks:
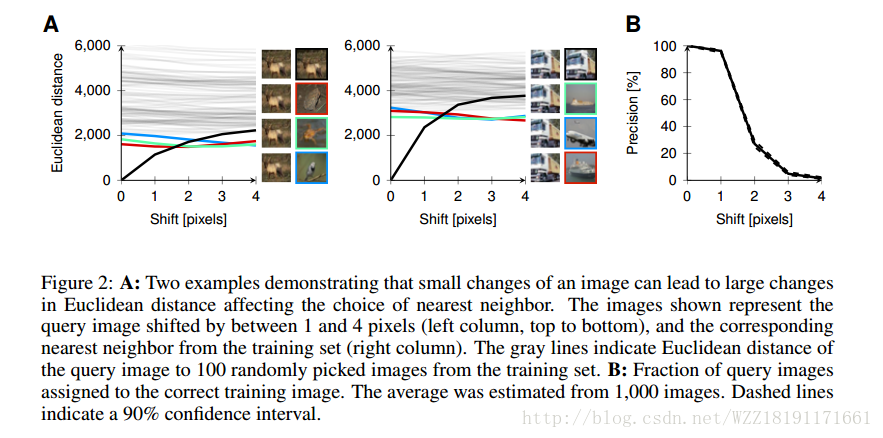
A note on the evaluation of generative models:
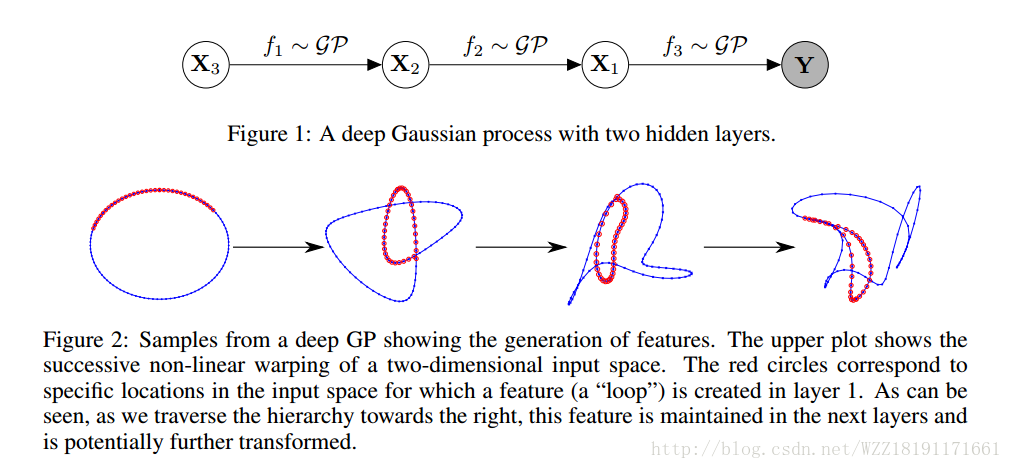
Variationally Auto-Encoded Deep Gaussian Processes:
Generating Images from Captions with Attention:
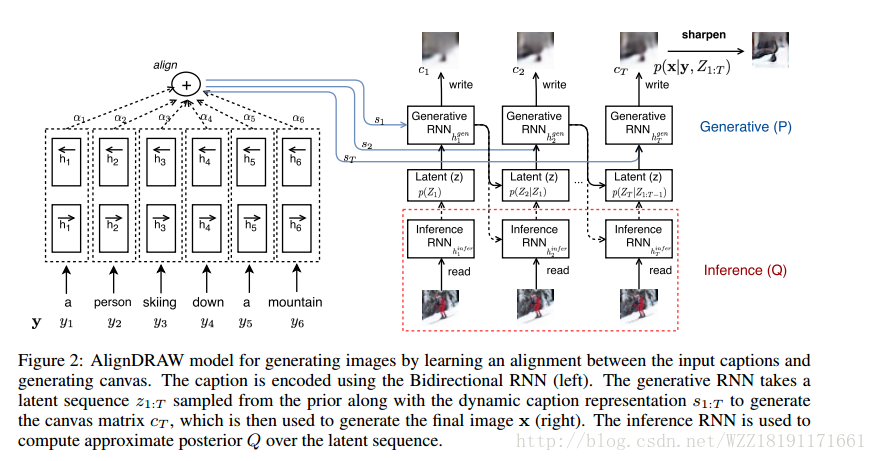
Unsupervised and Semi-supervised Learning with Categorical Generative Adversarial Networks:
Censoring Representations with an Adversary:

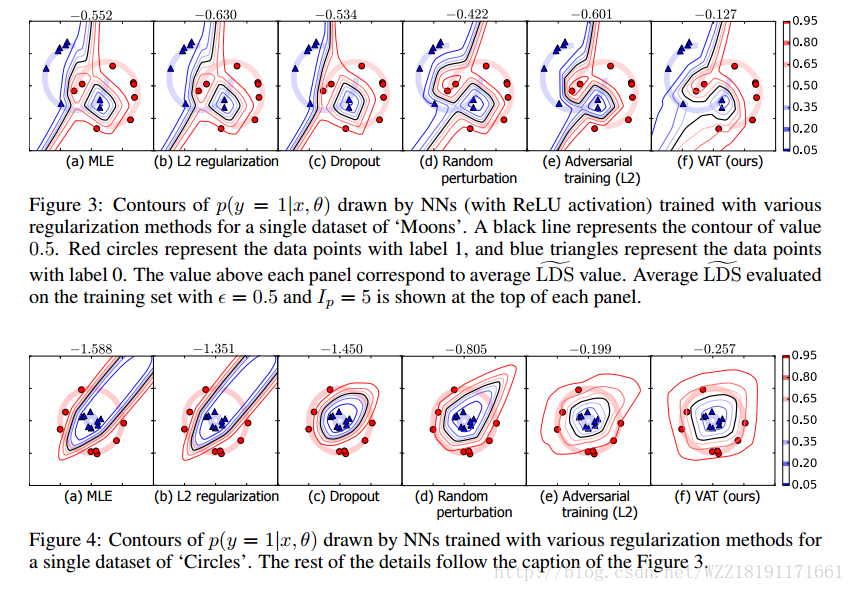
Distributional Smoothing with Virtual Adversarial Training:
Generative Visual Manipulation on the Natural Image Manifold:

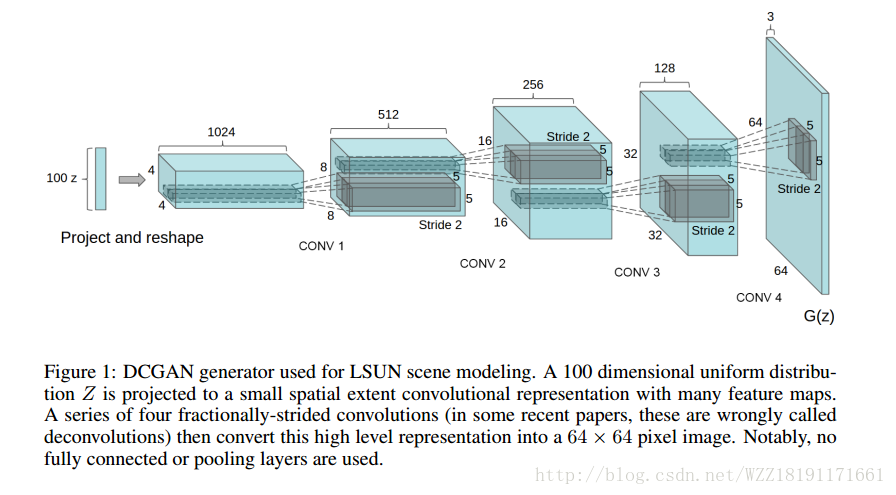
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks:
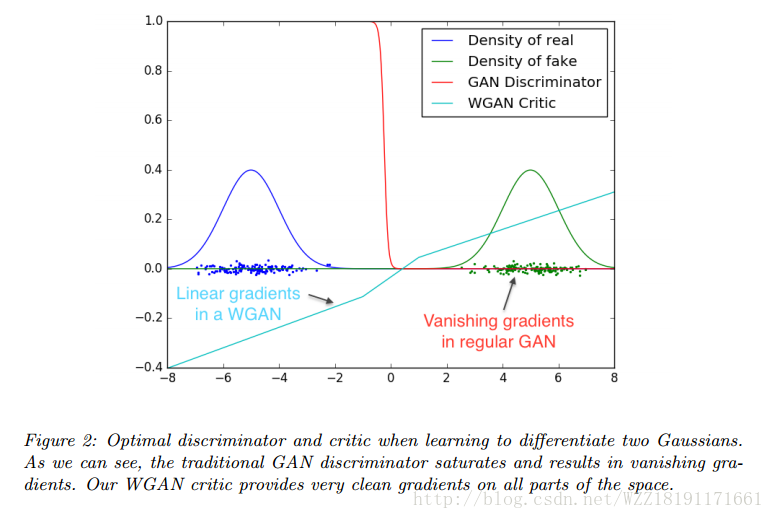
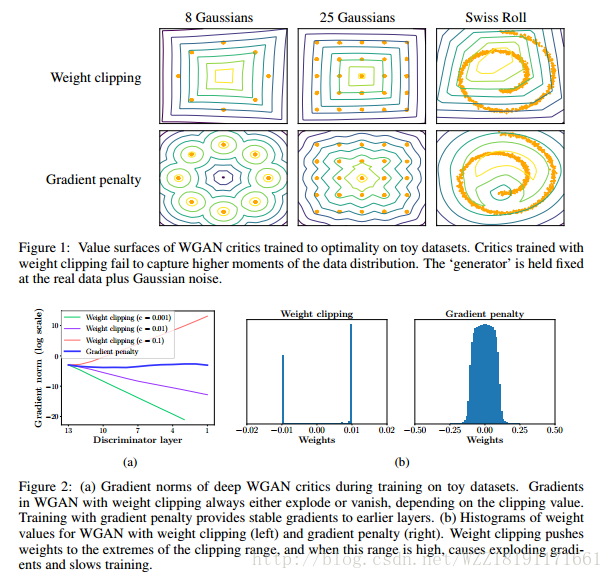
Wasserstein GAN:
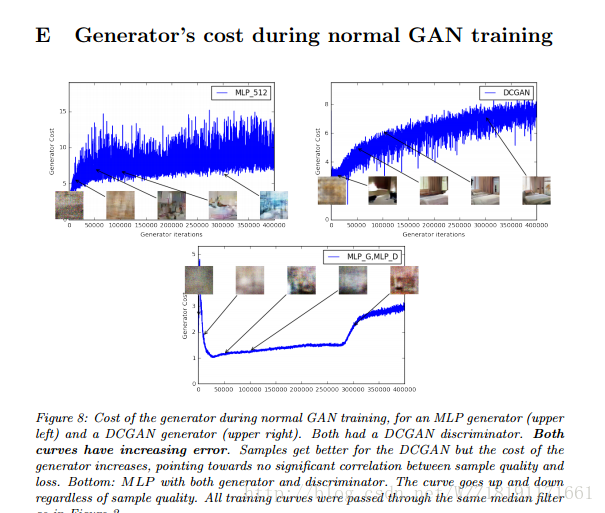
Loss-Sensitive Generative Adversarial Networks on Lipschitz Densities:
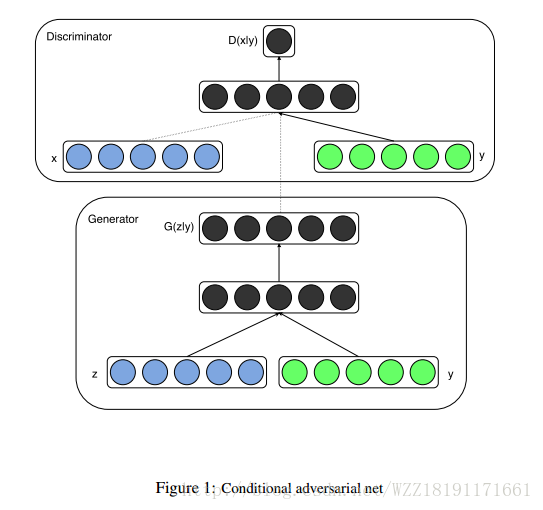
Conditional Generative Adversarial Nets:
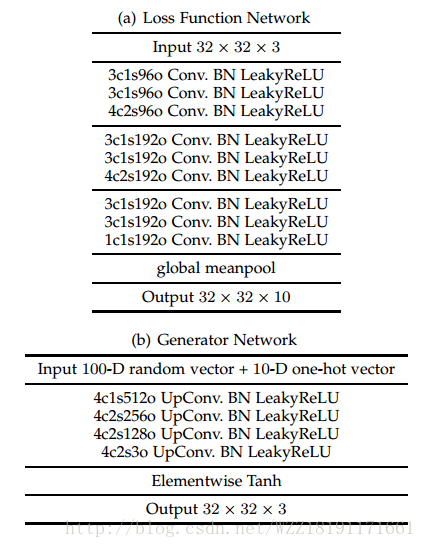
InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets:

Conditional Image Synthesis With Auxiliary Classifier GANs:
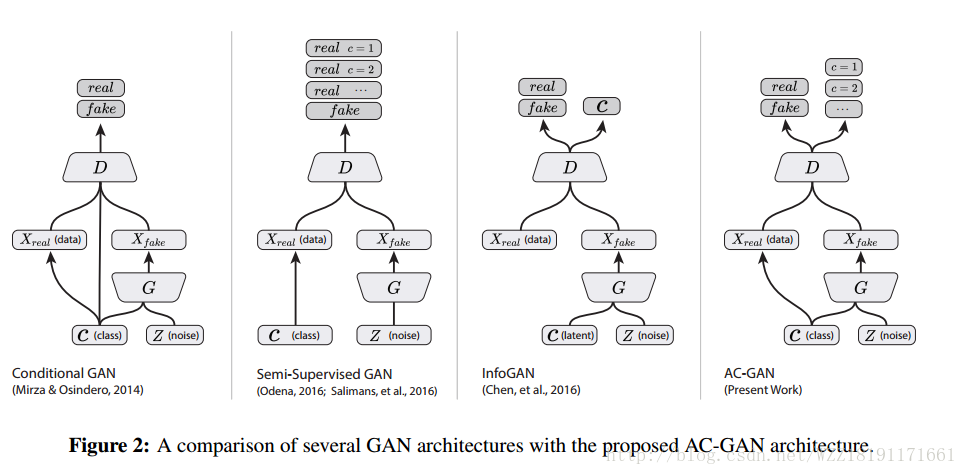
SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient:
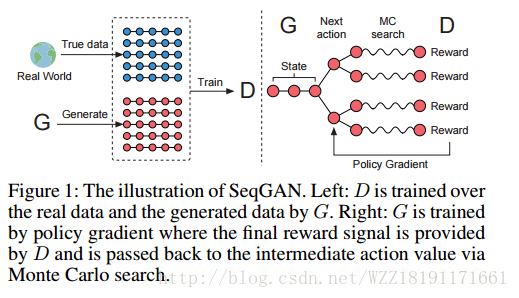
Improved Training of Wasserstein GANs:
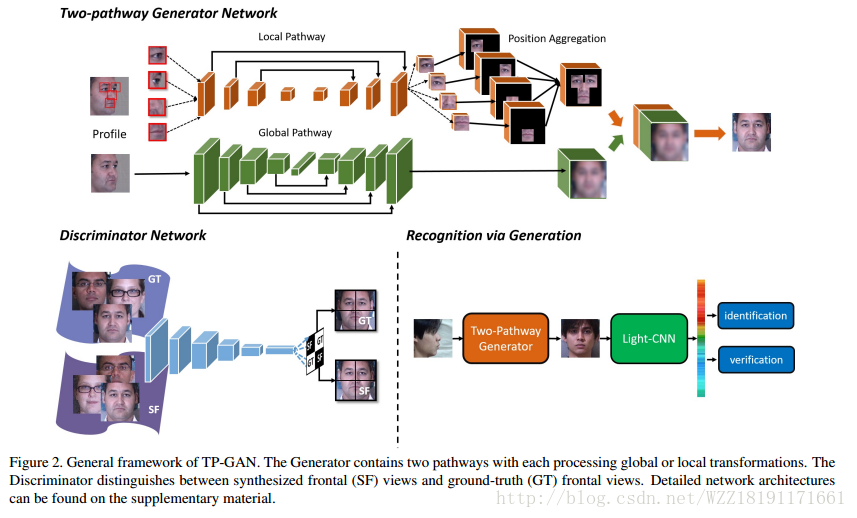
Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis:
Predicting Eye Fixations using Convolutional Neural Networks:

相關推薦
深度學習在CV領域的進展以及一些由深度學習演變的新技術
CV領域 1.進展:如上圖所述,當前CV領域主要包括兩個大的方向,”低層次的感知” 和 “高層次的認知”。 2.主要的應用領域:視訊監控、人臉識別、醫學影象分析、自動駕駛、 機器人、AR、VR 3.主要的技術:分類、目標檢
第二篇 KinectV2結合opencv入門開發以及一些相關的學習資料
第二篇 KinectV2結合opencv入門開發以及一些相關的學習資料 首先宣告一下,本系統所使用的開發環境版本是計算機系統Windows 10、Visual Studio 2013、Opencv3.0和Kinect SDK v2.0。這些都可以在百度上找到,downl
總結CNN的發展歷程,以及一些卷積操作的變形,附帶基礎的深度學習知識與公式
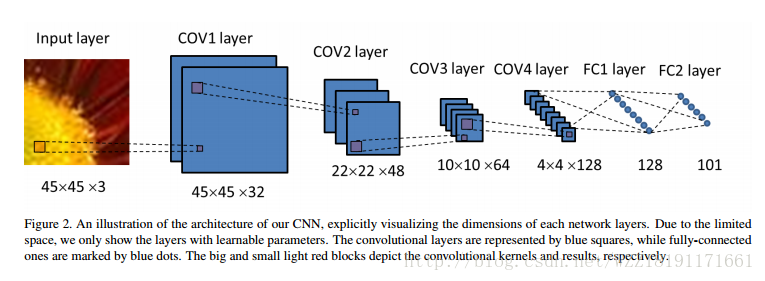
1.Lenet-5 :最先出現的卷積神經網路,1998年,由於當時的硬體還不成熟,因此到了2012年出現了AlexNet 2.AlexNet:可以說是現在卷積神經網路的雛形 3.VGGNet:五個模組的卷積疊加,網路結構如下: 4.GoogleNet:ince
Linux學習- 相對路徑以及一些命令20180409
linux path dir等相對路徑-從你當前位置的相對的路徑 絕對路徑-從根開始的路徑pwd 當前路徑cd 改變路徑 cd - 就是你上次的位置不管你在上面目錄 只要只輸入命令 cd 就會回來進入系統時的位置cd .. 回到目錄的上一級mkdir 新建一個目錄 它至創建路徑最後一個目錄,要保證之前都存在,
Hibernate學習一:Hebinate入門以及一些小問題
路徑 java ima maven 註意 添加 cfg.xml mod hbm 1:Hebinate框架的簡述: Hebinate框架主要用用在javaee開發中的dao層設計,實現對數據庫的crud等操作, Hibernate的底層通過jdbc實現,通過對jdbc的封裝
linux入門學習(二):linux圖形化界面與命令行界面之間的切換,以及一些系統命令
之間 linu 鏡像 pan ctr 安裝 linux -- linux鏡像 一、linux圖形化界面與命令行界面之間的切換 註意:前提是你安裝的 linux鏡像ios 必須具備圖形化功能。 1) 圖形化界面--->命令行界面: ctrl + alt +
【PHP學習】靜態檔案快取綜合小案例以及一些函式的注意點
靜態快取技術 儲存在磁碟上的靜態檔案,用PHP生 成資料到靜態檔案中。原理如下: php中的快取操作 生成快取 獲取快取 刪除快取 甩一段別人的程式碼 class Response{ static public function datas($cod
深度學習BP演算法 BackPropagation以及詳細例子解析
反向傳播演算法是多層神經網路的訓練中舉足輕重的演算法,本文著重講解方向傳播演算法的原理和推導過程。因此對於一些基本的神經網路的知識,本文不做介紹。在理解反向傳播演算法前,先要理解神經網路中的前饋神經網路演算法。 前饋神經網路 如下圖,是一個多層神
mzy git學習,git協同開發忽略文件配置以及一些雜點(九)
回憶一個電腦多賬戶問題 之前也說了,如果使用ssh登陸的話,一個電腦就只能登陸一個賬號了,不像通過憑據可以切換(但是其實也可以每次去生成新的公鑰和私鑰,只要你不嫌麻煩) 再次補充: ssh-keygen -t rsa -C “郵箱” 到github或者碼雲上選擇: clone o
入坑DL CV 一些基礎技能學習
進入實驗室學習了一個月左右,記錄一下新手入門所學的基本知識,都是入門級別的教程 1、Python 快速入門:廖雪峰Python教程--> https://www.liaoxuefeng.com/ 參考書:Python學習手冊、Python CookBook以及Python官方文件 2、
平時積累的優秀部落格連結(linux windows android ios c/c++ java ACM open cv LeetCode 數學 演算法 前端 機器/深度學習 圖形影象加速 )
<a href = "http://www.pudn.com/">pudn</a> <a href = "http://www.cnblogs.com/grandyang/p/4606334.html">leetCode刷完的神</a> <
Pandas基礎以及一些pandas學習資料連結
對於資料科學家,無論是資料分析還是資料探勘來說,Pandas是一個非常重要的Python包。它不僅提供了很多方法,使得資料處理非常簡單,同時在資料處理速度上也做了很多優化,使得和Python內建方法相比時有了很大的優勢。 如果你想學習Pandas,建議先看兩個網
深度學習: CV頂會 & CV頂刊
CV三大會議 CVPR: International Conference on Computer Vision and Pattern Recognition (每年,6月開會) ICCV: International Conference on Compute
hive學習筆記以及一些linux命令
去雙引號: sed -i "s/"//g" textNameworking:perl -p -i -e "s/ /,/g" ./wuhan_feiy_end_result.csv 出現 分組無效情況:
跑深度學習網路時碰到的一些問題記錄
分兩部分記錄:一.日誌資訊二.程式語言#############################################################################一.日誌資訊 在TRAIN_DIR路徑下會產生四種檔案: 1.c
深度學習在影象上的一些應用
背景 馬上就上班快半年了,畢業前一直在和工業中的資料打交道,工作中卻接觸的都是圖片,之前還有一點不太適應,不過本著資料是流動的基本思想,在圖片應用領域也能快速入門,並給公司做出了一定的貢獻。如果介紹的有什麼不對的地方請多指正,畢竟學習應用不過幾個月。 深度學習 什麼是深度學習
java的I/O學習記錄(以及一些其他知識點)
JAVA的I/O 1 I/O的基礎知識 1.1 流 Java程式通過流執行I/O。 流是一種抽象,要麼產生資訊,要麼使用資訊。 流通過java的I/O系統連結到
深度學習Loss 種類彙總以及討論
(1)首先是從大的角度來說,度量loss的主要為兩種方法。一種是從歐式距離計算,以L2-norm為主,一種是近來的另闢蹊徑的轉換到角度領域,主要從餘弦和夾角這兩個在我看來有異曲同工之效的角度。但是,總的Loss改進的出發點從之前的可分到現在的最大化類間最小化類內這個目標。遍觀
【深度學習CV】SVM, Softmax損失函式
Deep learning在計算機視覺方面具有廣泛的應用,包括影象分類、目標識別、語義分隔、生成影象描述等各個方面。本系列部落格將分享自己在這些方面的學習和認識,如有問題,歡迎交流。 在使用卷積神經網路進行分類任務時,往往使用以下幾類損失函式: 平
深度學習視覺領域常用資料集彙總
[導讀] “大資料時代”,資料為王!無論是資料探勘還是目前大熱的深度學習領域都離不開“大資料”。大公司們一般會有自己的資料,但對於創業公司或是高校老師、學生來說,“Where can I get large datasets open to the public?”是不得不面對的一個問題。 本文結合筆者