
深度學習BP演算法 BackPropagation以及詳細例子解析
反向傳播演算法是多層神經網路的訓練中舉足輕重的演算法,本文著重講解方向傳播演算法的原理和推導過程。因此對於一些基本的神經網路的知識,本文不做介紹。在理解反向傳播演算法前,先要理解神經網路中的前饋神經網路演算法。
前饋神經網路
如下圖,是一個多層神經網路的簡單示意圖: 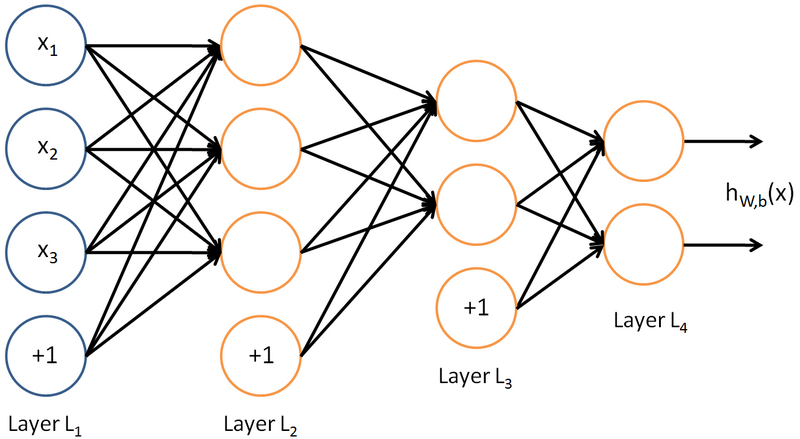
給定一個前饋神經網路,我們用下面的記號來描述這個網路:
L:表示神經網路的層數;
nl:表示第l層神經元的個數;
fl(∙):表示l層神經元的啟用函式;
Wl∈Rnl×nl−1:表示l−1層到第l層的權重矩陣;
bl∈Rnl:表示l−
zl∈Rnl:表示第l層神經元的輸入;
al∈Rnl:表示第l層神經元的輸出;
前饋神經網路通過如下的公式進行資訊傳播:
zl=Wl⋅fl(zl−1)+bl 這樣通過一層一層的資訊傳遞,可以得到網路的最後輸出 y為:
x=a0→z1→a1→z1→⋯→aL−1→zL→aL=y
反向傳播演算法
在瞭解前饋神經網路的結構之後,我們一前饋神經網路的資訊傳遞過程為基礎,從而推到反向傳播演算法。首先要明確一點,反向傳播演算法是為了更好更快的訓練前饋神經網路,得到神經網路每一層的權重引數和偏置引數。
在推導反向傳播的理論之前,首先看一幅能夠直觀的反映反向傳播過程的圖,這個圖取材於Principles of training multi-layer neural network using back propagation。
Principles of training multi-layer neural network using backpropagation
The project describes teaching process of multi-layer neural network employing backpropagation algorithm. To illustrate this process the three layer neural network with two inputs and one output,which is shown in the picture below, is used: 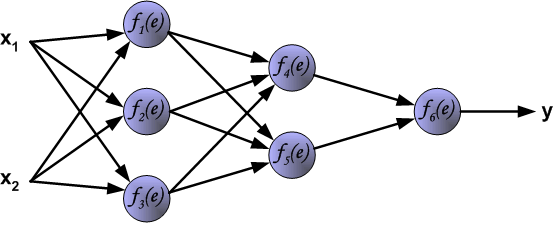
Each neuron is composed of two units. First unit adds products of weights coefficients and input signals. The second unit realise nonlinear function, called neuron activation function. Signal e is adder output signal, and y = f(e) is output signal of nonlinear element. Signal y is also output signal of neuron. 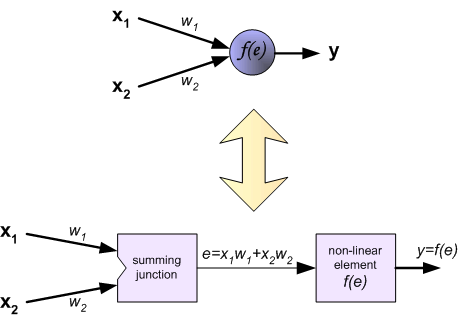
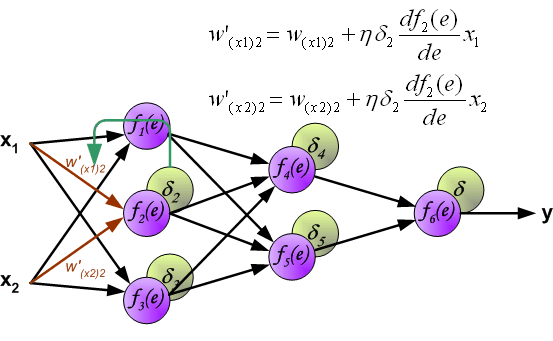
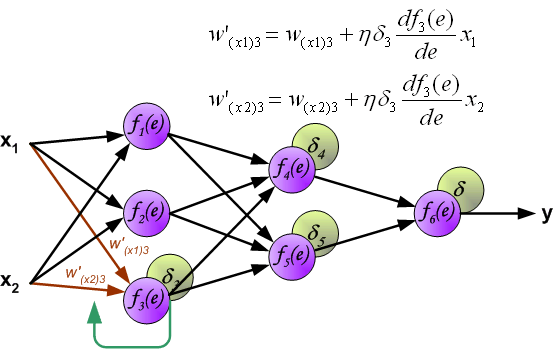
To teach the neural network we need training data set. The training data set consists of input signals (x1 and x2 ) assigned with corresponding target (desired output) z. The network training is an iterative process. In each iteration weights coefficients of nodes are modified using new data from training data set. Modification is calculated using algorithm described below: Each teaching step starts with forcing both input signals from training set. After this stage we can determine output signals values for each neuron in each network layer. Pictures below illustrate how signal is propagating through the network, Symbols w(xm)n represent weights of connections between network input xm and neuron n in input layer. Symbols yn represents output signal of neuron n. 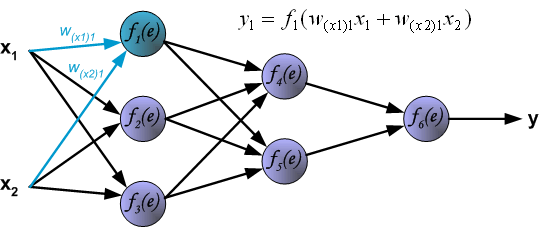
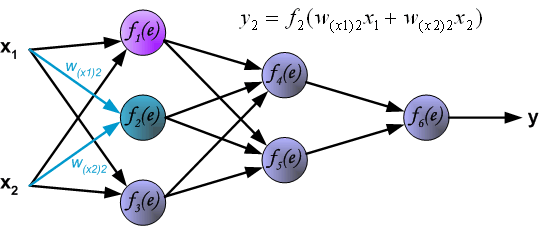
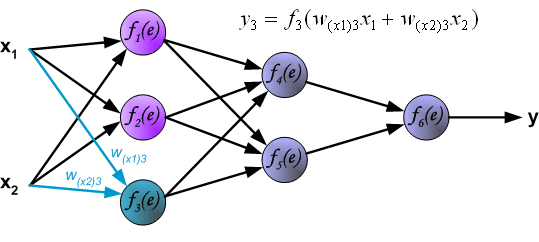
Propagation of signals through the hidden layer. Symbols wmn represent weights of connections between output of neuron m and input of neuron n in the next layer. 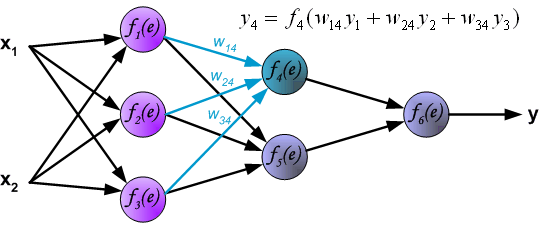
Propagation of signals through the output layer. 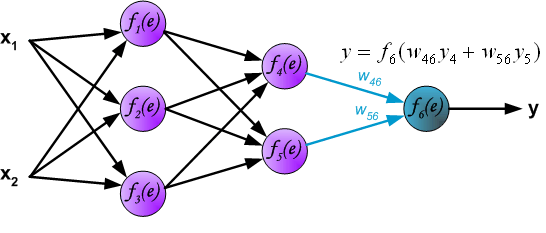
In the next algorithm step the output signal of the network y is compared with the desired output value (the target), which is found in training data set. The difference is called error signal d of output layer neuron. 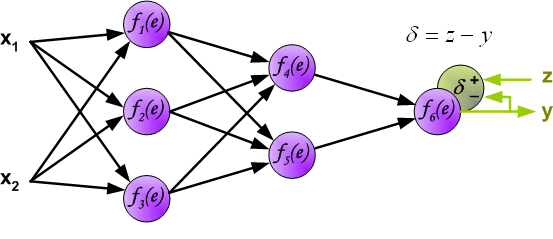
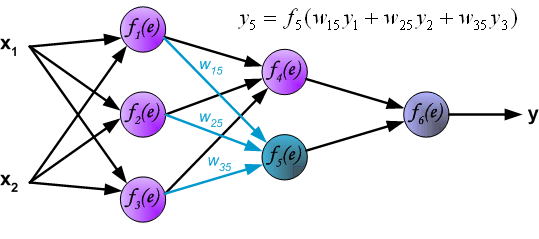
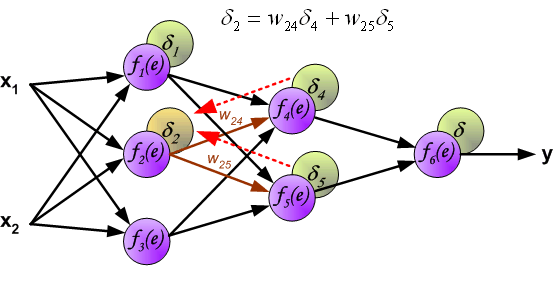
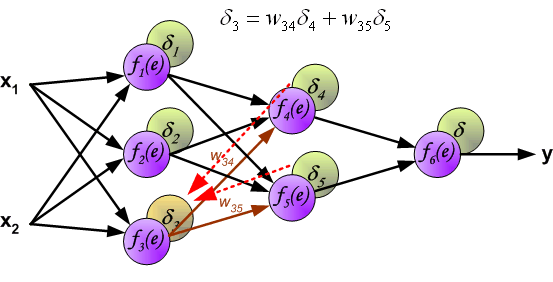
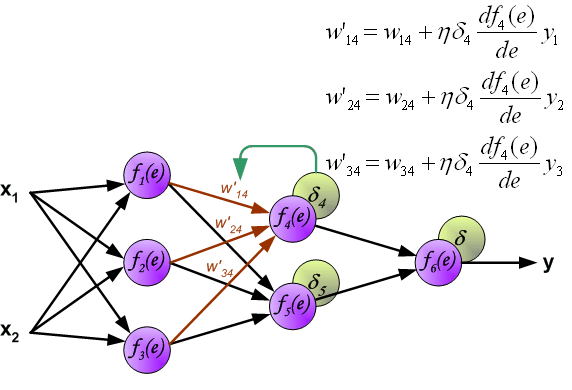
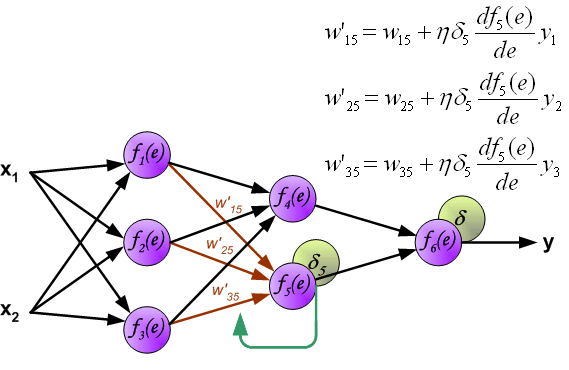
It is impossible to compute error signal for internal neurons directly, because output values of these neurons are unknown. For many years the effective method for training multiplayer networks has been unknown. Only in the middle eighties the backpropagation algorithm has been worked out. The idea is to propagate error signal d (computed in single teaching step) back to all neurons, which output signals were input for discussed neuron. 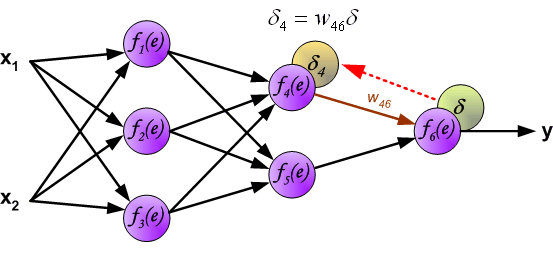
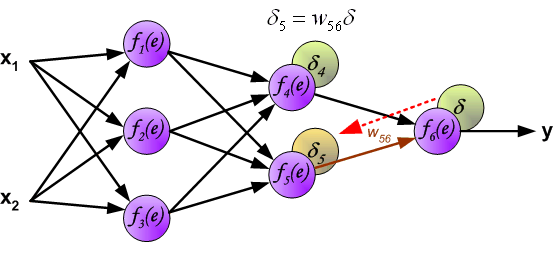
The weights' coefficients wmn used to propagate errors back are equal to this used during computing output value. Only the direction of data flow is changed (signals are propagated from output to inputs one after the other). This technique is used for all network layers. If propagated errors came from few neurons they are added. The illustration is below: 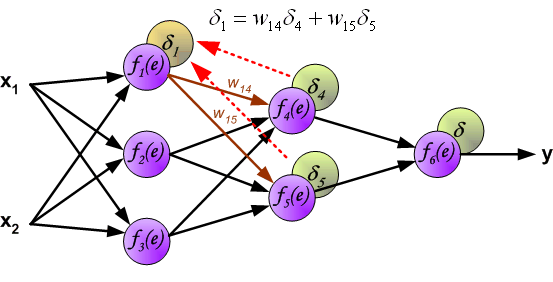
When the error signal for each neuron is computed, the weights coefficients of each neuron input node may be modified. In formulas below df(e)/de represents derivative of neuron activation function (which weights are modified). 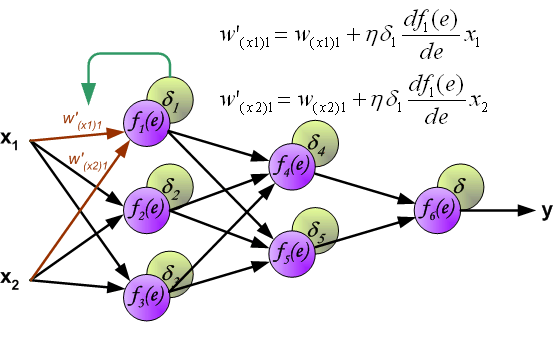
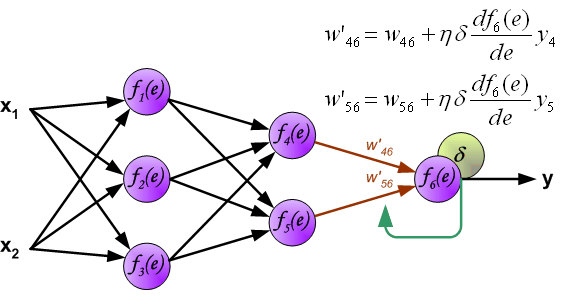
Coefficient h affects network teaching speed. There are a few techniques to select this parameter. The first method is to start teaching process with large value of the parameter. While weights coefficients are being established the parameter is being decreased gradually. The second, more complicated, method starts teaching with small parameter value. During the teaching process the parameter is being increased when the teaching is advanced and then decreased again in the final stage. Starting teaching process with low parameter value enables to determine weights coefficients signs. References Ryszard Tadeusiewcz "Sieci neuronowe", Kraków 1992 |
||
|
Mariusz Bernacki
Przemysław Włodarczyk
mgr inż. Adam Gołda (2005) Katedra Elektroniki AGH |
||
| Last modified: 06.09.2004 |
||
A Step by Step Backpropagation Example
Background
Backpropagation is a common method for training a neural network. There is no shortage of papers online that attempt to explain how backpropagation works, but few that include an example with actual numbers. This post is my attempt to explain how it works with a concrete example that folks can compare their own calculations to in order to ensure they understand backpropagation correctly.
If this kind of thing interests you, you should sign up for my newsletter where I post about AI-related projects that I’m working on.
Backpropagation in Python
You can play around with a Python script that I wrote that implements the backpropagation algorithm in this Github repo.
Backpropagation Visualization
For an interactive visualization showing a neural network as it learns, check out my Neural Network visualization.
Additional Resources
If you find this tutorial useful and want to continue learning about neural networks and their applications, I highly recommend checking out Adrian Rosebrock’s excellent tutorial on Getting Started with Deep Learning and Python.
Overview
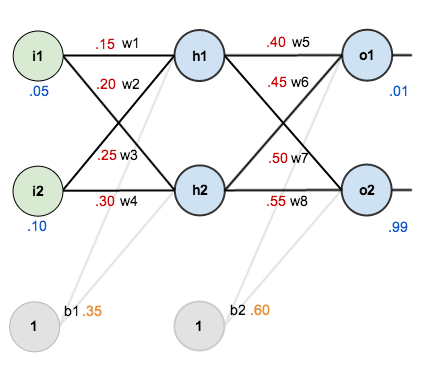
For this tutorial, we’re going to use a neural network with two inputs, two hidden neurons, two output neurons. Additionally, the hidden and output neurons will include a bias.
Here’s the basic structure:

In order to have some numbers to work with, here are the initial weights, the biases, and training inputs/outputs:
The goal of backpropagation is to optimize the weights so that the neural network can learn how to correctly map arbitrary inputs to outputs.
For the rest of this tutorial we’re going to work with a single training set: given inputs 0.05 and 0.10, we want the neural network to output 0.01 and 0.99.
The Forward Pass
To begin, lets see what the neural network currently predicts given the weights and biases above and inputs of 0.05 and 0.10. To do this we’ll feed those inputs forward though the network.
We figure out the total net input to each hidden layer neuron, squash the total net input using an activation function (here we use the logistic function), then repeat the process with the output layer neurons.
Total net input is also referred to as just net input by some sources. Here’s how we calculate the total net input for 


We then squash it using the logistic function to get the output of

Carrying out the same process for 

We repeat this process for the output layer neurons, using the output from the hidden layer neurons as inputs.
Here’s the output for 



And carrying out the same process for 

Calculating the Total Error
We can now calculate the error for each output neuron using the squared error function and sum them to get the total error:
^{2}")
 is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [
1].
is included so that exponent is cancelled when we differentiate later on. The result is eventually multiplied by a learning rate anyway so it doesn’t matter that we introduce a constant here [
1].
For example, the target output for
^{2} = \frac{1}{2}(0.01 - 0.75136507)^{2} = 0.274811083")
Repeating this process for

The total error for the neural network is the sum of these errors:

The Backwards Pass
Our goal with backpropagation is to update each of the weights in the network so that they cause the actual output to be closer the target output, thereby minimizing the error for each output neuron and the network as a whole.
Output Layer
Consider 

 is read as “the partial derivative of
is read as “the partial derivative of
 with respect to
with respect to
 “. You can also say “the gradient with respect to
“.
“. You can also say “the gradient with respect to
“.
By applying the chain rule we know that:

Visually, here’s what we’re doing:

We need to figure out each piece in this equation.
First, how much does the total error change with respect to the output?
^{2} + \frac{1}{2}(target_{o2} - out_{o2})^{2}")
^{2 - 1} * -1 + 0")
 = -(0.01 - 0.75136507) = 0.74136507")
") is sometimes expressed as
is sometimes expressed as
 When we take the partial derivative of the total error with respect to
When we take the partial derivative of the total error with respect to
 , the quantity
, the quantity
^{2}") becomes zero because
does not affect it which means we’re taking the derivative of a constant which is zero.
becomes zero because
does not affect it which means we’re taking the derivative of a constant which is zero.
Next, how much does the output of
The partial derivative of the logistic function is the output multiplied by 1 minus the output:

 = 0.75136507(1 - 0.75136507) = 0.186815602")
Finally, how much does the total net input of 
} + 0 + 0 = out_{h1} = 0.593269992")
Putting it all together:


You’ll often see this calculation combined in the form of the delta rule:
 * out_{o1}(1 - out_{o1}) * out_{h1}")
Alternatively, we have 


