
HashMap擴容死迴圈問題
JDK 1.7 HashMap 擴容核心演算法
下面這是JDK 1.7中HashMap擴容時呼叫的核心程式碼,作用是將原hash桶中的節點轉移到新的hash桶中:
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null 其中核心程式碼是下面這一段:
1 do {
2 //保留要轉移指標的下一個節點 下面我們來模擬一下多執行緒場景下擴容會出現的問題:
假設在擴容過程中舊hash桶中有一個單鏈表,單鏈表中只有一個節點A,也就是e引用的物件。新hash桶中有一個單鏈表,單鏈表中的節點是B->C,也就是newTable[i]引用的物件。
單執行緒擴容
如果只有一個執行緒在執行擴容:
- 執行到第 3 行next = e.next的時候next == null
- 從第 5 行到第 9 行會將A節點按照頭插法插入到newTable[i]所引用的單鏈表中,此時newTable[i]所引用的單鏈表中的節點是A->B->C
- 第 11 行e = next會將next賦值給e,所以e == null
- 這時候迴圈就結束了,整個擴容過程中毫無問題
多執行緒擴容
如果是多個執行緒同時在擴容,我們以T1執行緒的擴容過程為主視角,T2和T3執行緒只是會在T1執行緒擴容過程中搗亂的:
- T1執行緒執行到第 7 行e.next = newTable[i]的時候會使得 e.next == B
- 此時T2執行緒過來搗亂了,執行到第 3 行next = e.next,那麼會使得next == B,此時T2執行緒的使命結束了,下面不去考慮T2執行緒了
- T1執行緒執行到第 9 行newTable[i] = e的時候,使用頭插法將A插入到newTable[i]所引用的單鏈表中,此時newTable[i]所引用的單鏈表中的節點是A->B->C
- T1執行緒繼續執行到 11 行e = next,將使得e == B,由於e != null,所以迴圈將繼續
- T1執行緒開啟新的一輪迴圈,執行到第 3 行next = e.next的時候因為B.next == C,所以next == C
- 由於e == B,newTable[i] == A,當T1執行緒執行到第 7 行e.next = newTable[i]的時候,將導致A.next == B, B.next == A
當執行到這一步的時候,大家會發現好像看見了一個環,離真相越來越近了,下面我們兩種情況來繼續執行下去:
沒有T3執行緒介入,導致get請求死迴圈
- T1執行緒繼續向下執行到第 11 行e = next,將使得e == C,將繼續進行下一輪迴圈
- T1在這一輪新的迴圈中沒有其他執行緒介入,這一輪執行完畢之後將跳出迴圈,而此時newTable[i]所引用的單鏈表會形成一個閉環
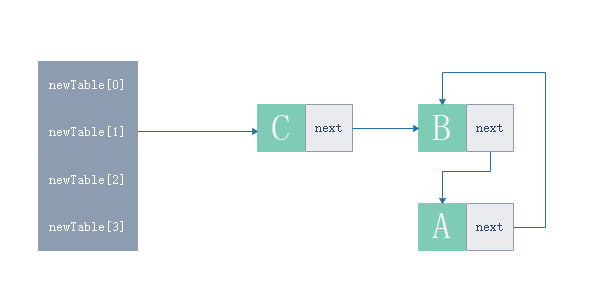
- 這時候如果使用者傳送一個get(A)的請求,將導致get請求發生死迴圈
有T3執行緒介入,導致T1執行緒擴容過程發生死迴圈
- 當T1執行緒執行到第 7 行e.next = newTable[i]的時候會使得 e.next == A
- 此時T3執行緒過來搗亂了,執行到第 3 行next = e.next,那麼會使得next == A,此時T3執行緒的使命結束了,下面不去考慮T2執行緒了
- 此時A.next == B, B.next == A, next == A,T1執行緒繼續往下執行next指標會在A和B之間無線迴圈,導致T1擴容過程中發生死迴圈
擴容死迴圈程式碼示例
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
public class HashMapTest {
public static void main(String[] args) throws Exception {
HashMap<String,String> map = new HashMap<String, String>();
TestDeadLock t1 = new TestDeadLock(map);
t1.start();
TestDeadLock t2 = new TestDeadLock(map);
t2.start();
TestDeadLock t3 = new TestDeadLock(map);
t3.start();
}
}
class TestDeadLock extends Thread {
private HashMap<String,String> map;
public TestDeadLock(HashMap<String, String> map) {
super();
this.map = map;
}
@Override
public void run() {
for (int i = 0; i<500000; i++) {
map.put(UUID.randomUUID().toString(), UUID.randomUUID().toString());
System.out.println("Running ~~");
}
}
}main方法執行到一半後不會再列印”Running ~~”,並且方法不會執行結束,所以判斷擴容過程造成死迴圈了。
JDK 1.7 HashMap擴容導致死迴圈的主要原因
HashMap擴容導致死迴圈的主要原因在於擴容後連結串列中的節點在新的hash桶使用頭插法插入。
新的hash桶會倒置原hash桶中的單鏈表,那麼在多個執行緒同時擴容的情況下就可能導致產生一個存在閉環的單鏈表,從而導致死迴圈。
JDK 1.8 HashMap擴容不會造成死迴圈的原因
在JDK 1.8中執行上面的擴容死迴圈程式碼示例就不會發生死迴圈,我們可以理解為在JDK 1.8 HashMap擴容不會造成死迴圈,但還是需要理論依據才有信服力。
首先通過上面的分析我們知道JDK 1.7中HashMap擴容發生死迴圈的主要原因在於擴容後連結串列倒置以及連結串列過長。
那麼在JDK 1.8中HashMap擴容不會造成死迴圈的主要原因就從這兩個角度去分析一下。
由於擴容是按兩倍進行擴,即 N 擴為 N + N,因此就會存在低位部分 0 - (N-1),以及高位部分 N - (2N-1), 所以在擴容時分為 loHead (low Head) 和 hiHead (high head)。
然後將原hash桶中單鏈表上的節點按照尾插法插入到loHead和hiHead所引用的單鏈表中。
由於使用的是尾插法,不會導致單鏈表的倒置,所以擴容的時候不會導致死迴圈。
通過上面的分析,不難發現迴圈的產生是因為新連結串列的順序跟舊的連結串列是完全相反的,所以只要保證建新鏈時還是按照原來的順序的話就不會產生迴圈。
如果單鏈表的長度達到 8 ,就會自動轉成紅黑樹,而轉成紅黑樹之前產生的單鏈表的邏輯也是藉助loHead (low Head) 和 hiHead (high head),採用尾插法。然後再根據單鏈表生成紅黑樹,也不會導致發生死迴圈。
這裡雖然JDK 1.8 中HashMap擴容的時候不會造成死迴圈,但是如果多個執行緒同時執行put操作,可能會導致同時向一個單鏈表中插入資料,從而導致資料丟失的。
所以不論是JDK 1.7 還是 1.8,HashMap執行緒都是不安全的,要使用執行緒安全的Map可以考慮ConcurrentHashMap。
喜歡這篇文章的朋友,歡迎掃描下圖關注公眾號lebronchen,第一時間收到更新內容。
